Brief Review — Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
Conceptual 12M, Larger Scale Than Conceptual 3M

Conceptual 12M: PushingWeb-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts,
Conceptual 12M (CC12M), by Google Research,
2021 CVPR, Over 200 Citations (Sik-Ho Tsang @ Medium)
Dataset, VLM, Visual Language, Vision Language Model, Image Captioning
==== My Other Paper Readings Also Over Here ====
- By relaxing the data collection pipeline used in Conceptual Captions 3M (CC3M), Conceptual 12M (CC12M) is introduced.
- CC12M is a dataset with 12 million image-text pairs specifically meant to be used for vision-and-language pre-training.
Outline
- Conceptual 12M (CC12M)
- Results
1. Conceptual 12M (CC12M)

- CC3M involves substantial image, text, and image-text filtering and processing to obtain clean, high-precision captions.
- However, this approach comes at the cost of low recall (many potentially useful <image, Alt-text> pairs are discarded).
- CC12M follows the same pipeline but with relaxing conditions.
- e.g.: The maximum ratio of larger to smaller dimension to 2.5 instead of 2. Text between 3 and 256 words is allowed in the alt-text. Candidates with no noun or no determiner are discarded, but permit ones without prepositions. The maximum fraction of word repetition allowed is 0.2.
- Given a larger pool of text due to the above relaxations, the threshold for counting a word type as rare is increased from 5 to 20.
- There are also other relaxation, e.g.: name entity masking token.
As shown above, CC12M consists of 12.4M image-text pairs, about 4× larger than CC3M. The average caption length of CC12M is much longer.

- CC12M spans many categories, and can be attributed to (1) a dramatic increase in scale, and (2) the absence of fine-grained entity hypernymization.
- “<word> <frequency in CC3M>→<hfrequency in CC12M>”: luffy 0→152, mangosteen 0→212, zanzibar 0→1138, sumo 1→661, pokemon 1→8615, chevrolet 1→12181, mehndi 3→9218, pooh 4→7286, cyberpunk 5→5247, keto 6→6046, hound 9→3392, quiche 50→1109, durian 61→552, jellyfish 456→2901.
2. Results
2.1. Models

- Two most fundamental V+L tasks are focused: vision-to-language generation and vision-and-language matching.
- For vision-to-language generation, image captioning (ic) is used as the pre-training task. The task is to predict the target caption given image features. To train the model parameters, the standard cross entropy loss given the groundtruth caption is used. Encoder-decoder Transformer model is used.
- For vision-and-language matching, the model takes as input both image and text features and predicts whether the input image and text are matched. To train the model’s parameters, a contrastive softmax loss is used. Two encoder-only Transformer models are used for image and text.
2.2. Downstream Tasks
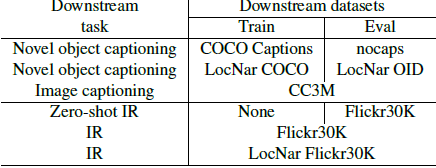
- Different pretraining tasks have different downstream tasks as above.
2.3. nocaps


- With a fine-tuned model, the benefit of transfer learning using pre-training on this task is clear (Row 1 vs. Rows 4,5,6), with CC12M outperforming CC3M by +14.2 CIDEr points and another +2.8 with CC3M+CC12M.
The above figure illustrates this effect; scaling up pre-training data benefits learning multimodal correspondences from a much larger pool of concepts.
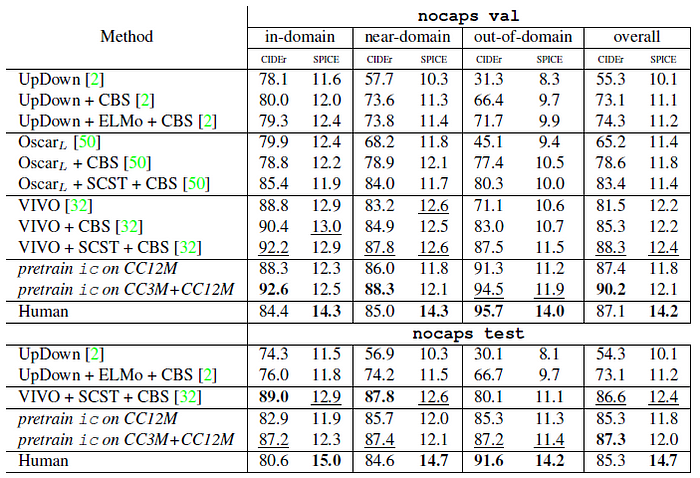
Comparing the best model (ic pre-trained on CC3M+CC12M) to existing state-of-the-art results on nocaps, it shows that it achieves state-of-the-art performance on CIDEr, outperforming a concurrent work [32].
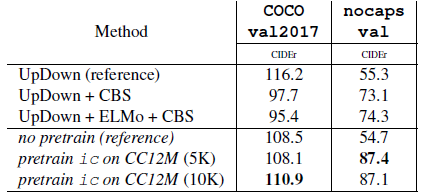
Over–fine-tuning on COCO Captions may incur a cost in terms of poor generalization.
2.4. LocNar
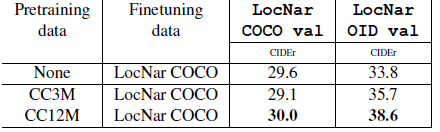
CC12M achieves superior performance (as measured by CIDEr) compared to CC3M as pretraining data.
2.5. CC3M
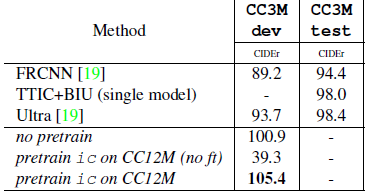
CC12M improves the CIDEr score on the dev split from 100.9 to 105.4 (+4.5 CIDER points).
2.6. Flickr30K
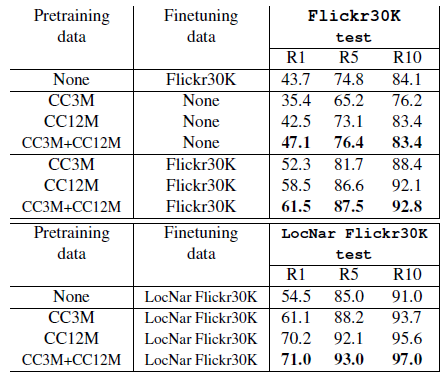
First, both CC3M and CC12M are beneficial, improving over “from-scratch” training.
Additionally, CC12M significantly outperforms CC3M in all cases.
Finally, combining the two datasets (CC3M+CC12M) results in even better performance.
Reference
[2021 CVPR] [Conceptual 12M (CC12M)]
Conceptual 12M: PushingWeb-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
3.1. Visual/Vision/Video Language Model (VLM)
2017 [Visual Genome (VG)] 2018 [Conceptual Captions] 2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT] [VL-BERT] [OSCAR] 2021 [CLIP] [VinVL] [ALIGN] [VirTex] [ALBEF] [Conceptual 12M (CC12M)] 2022 [FILIP] [Wukong]
