Review — ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Align Visual and Language Representations Using Contrastive Learning
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision, ALIGN, by Google Research
2021 ICML, Over 600 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, VLM, Contrastive Learning
- ALIGN, A Large-scale ImaGe and Noisy-text embedding, is proposed to leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset.
- A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss.
Outline
- A Large-Scale Noisy Image-Text Dataset
- Pre-training and Task Transfer
- Results
1. A Large-Scale Noisy Image-Text Dataset

- The methodology of constructing Conceptual Captions dataset is followed to get a version of raw English alt-text data (image and alt-text pairs).
- While Conceptual Captions dataset was cleaned by heavy filtering and post-processing, in this paper, quality is traded for scale by relaxing most of the cleaning steps in the original work.
Only minimal frequency-based filtering is applied. The result is a much larger (1.8B image-text pairs) but noisier dataset.
2. Pre-training and Task Transfer

2.1. Model Architecture
- ALIGN is pretrained using a dual-encoder architecture.
- The model consists of a pair of image and text encoders with a cosine-similarity combination function at the top.
- EfficientNet with global pooling (without training the 1x1 conv layer in the classification head) is used as the image encoder.
- BERT with [CLS] token embedding is used as the text encoder. A fully-connected layer with linear activation is added on top of BERT encoder to match the dimension from the image tower.
- Both image and text encoders are trained from scratch.
- Unless ablation study, EfficientNet-L2 and BERT-Large are used.
2.2. Loss Functions
- The image and text encoders are optimized via normalized softmax loss.
- In training, matched image-text pairs are treated as positive and all other random image-text pairs that can be formed in a training batch as negative.
- The sum of two losses are minimized. one is for image-to-text classification:

- Another one is for text-to-image classification:

- Here, xi and yj are the normalized embedding of image in the i-th pair and that of text in the j-th pair, respectively. N is the batch size. σ is the temperature to scale the logits, which is a learnable parameter as well.
- The model is trained on 1024 Cloud TPUv3 cores with 16 positive pairs on each core. Therefore the total effective batch size is 16384.
2.3. Transferring
- ALIGN models are evaluated on image-to-text and text-to-image retrieval tasks, with and without finetuning. During fine-tuning, the same loss function is used.
- Zero-shot transfer of ALIGN is also applied to visual classification tasks. If we directly feed the texts of classnames into the text encoder, ALIGN is able to classify images into candidate classes via image-text retrieval.
- The image encoder is transferred to downstream visual classification tasks using two settings: Training the top classification layer only (with frozen ALIGN image encoder) and fully fine-tuned.
3. Results
3.1. Image-Text Matching & Retrieval

In the zero-shot setting, ALIGN gets more than 7% improvement in image retrieval task compared to the previous SOTA, CLIP.
With fine-tuning, ALIGN outperforms all existing methods by a large margin, including those that employ more complex cross-modal attention layers such as OSCAR.

ALIGN achieves SOTA results in all metrics, especially by a large margin on image-to-text (+22.2% R@1) and text-to-image (20.1% R@1) tasks.
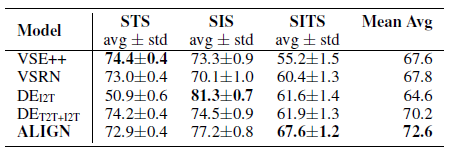
ALIGN also outperforms the previous SOTA on SITS task with an improvement of 5.7%.
3.2. Zero-shot Visual Classification

ALIGN shows great robustness on classification tasks with different image distributions. In order to make a fair comparison, the same prompt ensembling method as CLIP is used. Such ensembling gives 2.9% improvement on ImageNet top-1 accuracy.
3.3. Visual Classification With Image Encoder Only
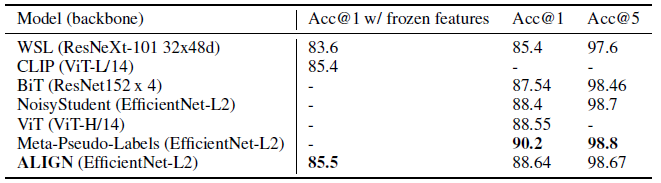
With frozen features, ALIGN slightly outperforms CLIP and achieves SOTA result of 85.5% top-1 accuracy.
After fine-tuning ALIGN achieves higher accuracy than BiT and ViT models, and is only worse than Meta Pseudo Labels which requires deeper interaction between ImageNet training and large-scale unlabeled data.
- Compared to Noisy Student and Meta-Pseudeo-Labels which also use EfficientNet-L2, ALIGN saves 44% FLOPS by using smaller test resolution (600 vs 800).

ALIGN outperforms BiT-L.
- (Please kindly check out the paper for the ablation experiments.)
Reference
[2021 ICML] [ALIGN]
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
3.1. Visual/Vision/Video Language Model (VLM)
2018 [Conceptual Captions] 2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT] [VL-BERT] [OSCAR] 2021 [CLIP] [VinVL] [ALIGN]
