Review — Wukong: A 100 Million Large-scale Chinese Cross-modal Pre-training Benchmark
Provide Chinese Wukong Dataset, Release Models Pretrained on Wukong Dataset

Wukong: A 100 Million Large-scale Chinese Cross-modal Pre-training Benchmark, Wukong, by Huawei Noah’s Ark Lab, and Sun Yat-sen University
2022 NeurIPS, Track Datasets and Benchmarks, Over 10 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, VLM, Vision Transformer, ViT
- There are the lack of large-scale datasets and benchmarks in Chinese hinders the development of Chinese VLP models.
- A large-scale Chinese cross-modal dataset, named Wukong, is released, which contains 100 million Chinese image-text pairs collected from the web.
- Wukong aims to benchmark different multi-modal pre-training methods. A group of models pre-trained with various image encoders (ViT-B/ViT-L/SwinT),with different advanced pre-training techniques into VLP such as locked-image text tuning, token-wise similarity in contrastive learning, and reduced-token interaction, is also released.
Outline
- Wukong Dataset
- Wukong Pretraining Techniques
- Wukong Chinese Benchmark
1. Wukong Dataset

1.1. Motivations
- Table 1: Despite the availability of large-scale English datasets, directly translating them into Chinese and then training a Chinese VLP model can lead to a severe performance drop.
To bridge this gap, authors release a large-scale Chinese cross-modal dataset named Wukong, which contains 100 million image-text pairs collected from the web.
1.2. Test Set Comparison
- Table 2: The comparison of available Chinese image-text testing datasets.
A test set called Wukong-Test is built, the quality of which has been verified by human experts.
1.3. Dataset Construction
- Table 3: The original keyword list is taken from [40] and only the first 200,000 most frequently keywords are used to search for images and their corresponding captions in Baidu.
- For data balance, at most 1000 image-text pairs are kept for each keyword. In this way, we collect a total of 166 million raw 〈image, text〉 pairs.
- A series of image and text filtering strategies are applied to filter out some pairs, to finalize Wukong dataset, as shown in Table 3.

2. Wukong Pretraining Techniques

Three variations of pretrained models: global similarity (CLIP-style); token-wise similarity (FILIP-style) and token-wise similarity with token reduction layer (Wukong-style).
2.1. Model Architecture
- Following the recent widely adopted contrastive pre-training architectures CLIP and FILIP, a dual-stream model with Transformer-based text and image encoders, is used.
- Visual Encoder: ViT and SwinT, are considered.
- Textual Encoder: A standard decoder-only Transformer is used, with a vocabulary size of 21,128 for Chinese text tokenization. The text encoder has 12 layers, each of which has 8 attention heads and a hidden state dimension of 512.
- Linear Projection of the Encoders: On the top of the visual and textual encoders, the global representations of visual token sequence (e.g., [CLS] token for ViT; average pooled representation of all patch tokens for SwinT) and textual token sequence (e.g., textual [SEP] token) are linearly projected to the common multi-modal space, followed by L2-normalization separately.
- Token Reduction Layer: Instead of only computing global representation, a late interaction method as introduced in FILIP, is also considered. Yet, a large amount of computation is introduced. A token reduction layer inspired by [37]. It aims to learn a small set of tokens (e.g., 12 or 24) from the whole output tokens of the visual encoder (e.g., 16×16 in ViT-L/14), and use them for the reduced-token interaction. This token reduction layer is used in all the Wukong-style models.
2.2. Pre-training Objectives
- For a training batch consisting of b image-text pairs {xIk, xTk} where k is from 1 to b, xTk (resp. xIk) is positive to xIk (resp. xTk) while negative to all other texts (resp. images) in the same batch.
- Therefore, the image-to-text and text-to-image contrastive losses for (xIk, xTk) can be formulated as:
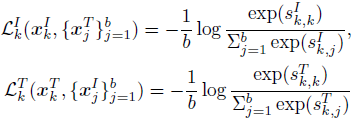
- where sIk,j denotes the similarity of the k-th image to the j-th text, while sTk,j denotes the similarity between the k-th text to the j-th image. The total loss L is then computed as:
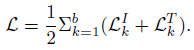
- The learned representations of the image and text are denoted as zI and zT with the size of n1×d and n2×d, respectively. Here n1 and n2 are the numbers of (non-padded) tokens in each image and text.
2.2.1. Global Similarity
- In CLIP and ALIGN, the similarity is computed via dot product of the global features of the entire image and text sequence. Specifically, the global similarity between the image and text is computed as:
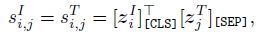
- where [zIi][CLS] denotes the feature vector of the [CLS] token of the i-th image and [zTj][SEP] denotes the feature vector of the [SEP] token of the j-th text. Since SwinT has no [CLS] token, the average pooling is used on the features of all patch tokens to represent it.
2.2.2. Token-Wise Similarity
- In FILIP, the similarity is computed based on a finer-grained interaction between the image patches and textual tokens.
- The average token-wise maximum similarity of all non-padded tokens in this i-th image is regarded as the cross-modal similarity:

- where:
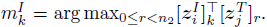
- The similarity of a text to an image can be computed in a similar way.
- However, The computation cost is about 2×n1×n2 times more than that of global similarity. Reduced-token interaction is introduced as below to reduce the cost.
2.2.3. Reduced-Token Interaction
- A learnable token reduction layer is added on top of visual tokens.
- The k-th attention map is computed via Convk, which is implemented using two convolutional layers. Then, a spatial global average pooling AvgPool is used to get the final k-th visual token Zlk:

2.2.4. Locked-Image Text Tuning
3. Wukong Chinese Benchmark
3.1. Zero-shot Image Classification

- Prompt Ensemble: 80 text prompts which are originally used on ImageNet by CLIP and manually translate them into Chinese.
In comparison with models pre-trained using Wukong dataset, BriVL shows a significantly poor performance. Wukong dataset is effective for multi-modal pre-training.
- The model trained with SwinT as the image encoder performs worse compared to others. The reason might be that patch merging in SwinT has already served a similar purpose in selecting and merging the important visual patch tokens. Therefore, the reduced-token interaction brings a negative impact.
Besides, using the same ViT image encoder, either ViT-B or ViT-L, Wukong models perform quite well. In particular, WukongViT-L achieves the highest average accuracy of 73.03% among all models.
3.2. Image-Text Retrieval
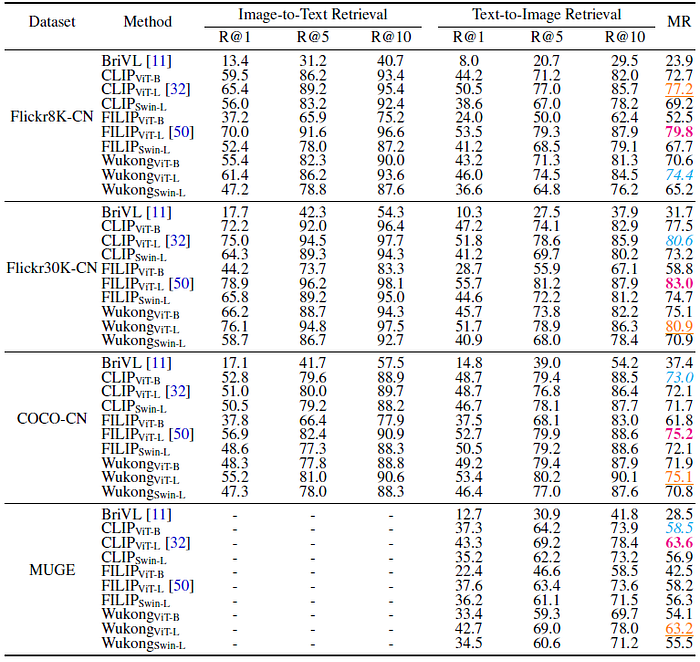
In general, models trained on Wukong dataset achieve a significantly better performance than BriVL, which demonstrates the effectiveness of the proposed dataset.
Besides, WukongViT-L shows a competitive performance in comparison to other models.
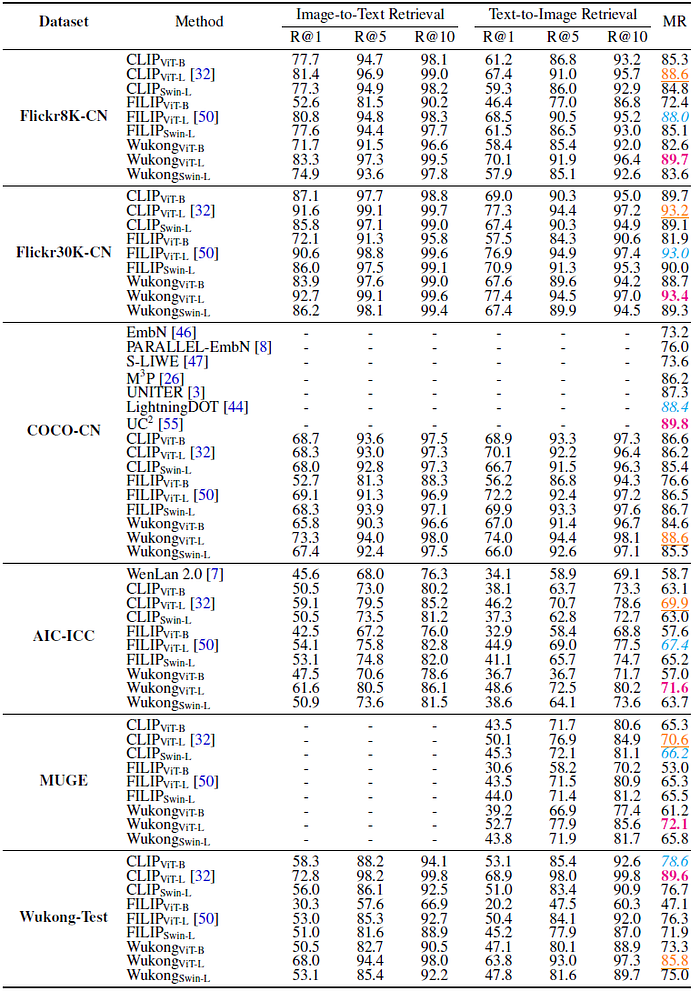
Generally, WukongViT-L achieves the best results among different model variants and datasets.
- For Wukong-Test, CLIPViT-L achieves the best result (89.6%) so far. It shows that models with global similarity is particularly effective when massively trained on in-domain Wukong train set.
3.3. Ablation Study
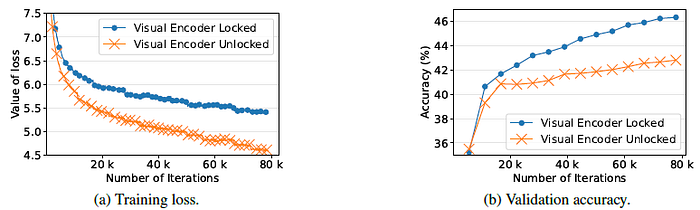
- The unlocked image encoder contributes to reduce the training loss and find the local optima efficiently.
However, the validation accuracy of LiT-tuning (locked) model remains higher than the other in almost every iteration, which demonstrates a better generalization.
Wukong aims to provide Chinese dataset, and release models that on Wukong Chinese dataset.
References
[2022 NeurIPS] [Wukong]
Wukong: A 100 Million Large-scale Chinese Cross-modal Pre-training Benchmark
[Dataset] [Wukong]
https://wukong-dataset.github.io/wukong-dataset/
3.1. Visual/Vision/Video Language Model (VLM)
2018 [Conceptual Captions] 2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT] [VL-BERT] [OSCAR] 2021 [CLIP] [VinVL] [ALIGN] 2022 [FILIP] [Wukong]
