Brief Review — LRCN: Long-term Recurrent Convolutional Networks for Visual Recognition and Description
LRCN, Using Both CNN & LSTM, Outperforms m-RNN

Long-term Recurrent Convolutional Networks for Visual Recognition and Description, LRCN, by UT Austin, UMass Lowell, and UC Berkeley,
2015 CVPR, Over 6000 Citations (Sik-Ho Tsang @ Medium)
Video Classification, Image Captioning, Video Captioning
- Long-term Recurrent Convolutional Networks (LRCNs) is proposed, which uses CNN and LSTM jointly for image description and video description.
- LRCN processes the (possibly) variable-length visual input (left) with a CNN (middle-left), whose outputs are fed into a stack of recurrent sequence models (LSTMs, middle-right), which finally produce a variable-length prediction (right).
Outline
- Use Cases
- Results
1. Use Cases

- (It is assumed CNN and LSTM are known first.)
1.1. Sequential Inputs, Fixed Outputs (Left)

- The visual activity recognition problem can fall under this umbrella, with videos of arbitrary length T as input, but with the goal of predicting a single label like running or jumping drawn from a fixed vocabulary.
1.2. Fixed Inputs, Sequential Outputs (Middle)

- The image description (image captioning) problem fits in this category, with a non-time-varying image as input, but a much larger and richer label space consisting of sentences of any length.
1.3. Sequential Inputs and Outputs (Right)

- Finally, it’s easy to imagine tasks for which both the visual input and output are time-varying, and in general the number of input and output timesteps may differ, e.g.: video description (video captioning) task.
2. Results
2.1. Activity Recognition / Video Classification

- Two variants of the LRCN architecture are explored: one in which the LSTM is placed after the first fully connected layer of the CNN (LRCN-fc6) and another in which the LSTM is placed after the second fully connected layer of the CNN (LRCN-fc7).
- The LRCN networks are trained with video clips of 16 frames. The LRCN predicts the video class at each time step and we average these predictions for final classification.
- At test time, we extract 16 frame clips with a stride of 8 frames from each video and average across clips.
- There can be RGB color image and flow image as input.
- The CNN base of the LRCN is a hybrid of the Caffe reference model, a minor variant of AlexNet, and the network used by ZFNet, pretrained on ImageNet.
- When classifying center crops, the top-1 classification accuracy is 60.2% and 57.4% for the hybrid and Caffe reference models.
The LRCN shows clear improvement over the baseline single-frame system and approaches the accuracy achieved by other deep models.
2.2. Image Description / Image Captioning
- At each timestep, both the image features and the previous word are provided as inputs to the sequential model, in this case a stack of LSTMs (each with 1000 hidden units).
- The fourth LSTM’s outputs are inputs to the softmax which produces a distribution over words.
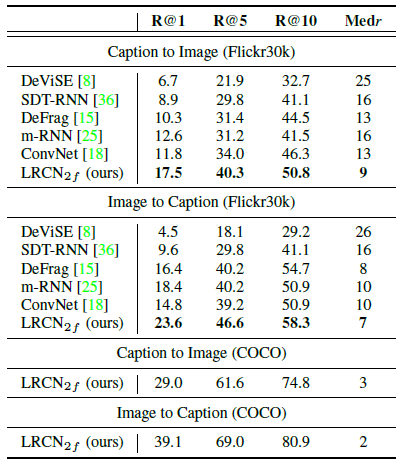
- Median rank, Medr, of the first retrieved ground truth image or caption and Recall@K, the number of images or captions for which a correct caption or image is retrieved within the top K results.
The proposed model consistently outperforms the strong baselines from recent work [18, 25, 15, 36, 8] such as m-RNN.
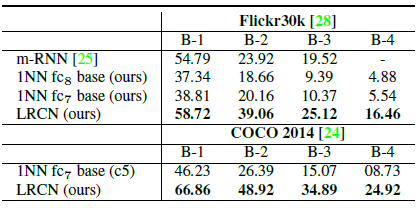
- BLEU score is measured (used in SMT/NMT) as similarity of the descriptions.
Based on the B-1 scores, generation using LRCN performs comparably with m-RNN on Flickr30k and COCO2014.
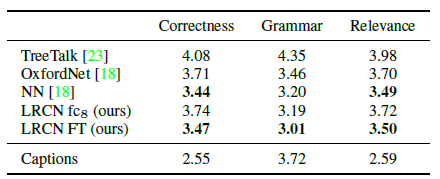
- Turkers in AMT are used to rank the sentences based on correctness, grammar and relevance.
The finetuned (FT) LRCN model performs on par with the Nearest Neighbour (NN) on correctness and relevance, and better on Grammar.
2.3. Video Description / Video Captioning
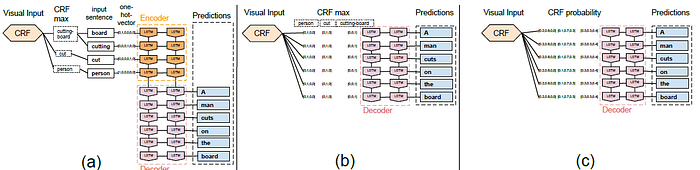
- In convention, a semantic representation of the video is first recognized using the maximum a posterior estimate (MAP) of a CRF taking in video features as unaries.
- This representation, e.g. person, cut, cutting board, is then concatenated to a input sentence (person cut cutting board) which is translated to a natural sentence (a person cuts on the board) using phrase-based statistical machine translation (SMT).
- Here, SMT is replaced by LSTM with different architecture variants.
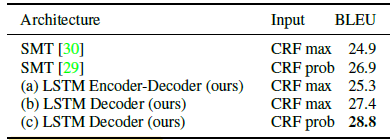
- The LSTM outperforms an SMT-based approach to video description;
- The simpler decoder architecture (b) and (c) achieve better performance than (a), likely because the input does not need to be memorized; and
- The approach achieves 28.8%, clearly outperforming the best reported number of 26.9% on TACoS multilevel by [29].
This paper should be the one of the popular cited papers, which uses CNN+LSTM.
Reference
[2015 CVPR] [LRCN]
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
1.12. Video Classification / Action Recognition
2014 … 2015 … [LRCN] … 2018 [NL: Non-Local Neural Networks] [S3D, S3D-G] 2019 [VideoBERT]
5.2. Image Captioning
2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell] [LRCN] 2017 [Visual N-Grams]
5.3. Video Captioning
2015 [LRCN] 2019 [VideoBERT]
