Brief Review — MobileViTv2: Separable Self-attention for Mobile Vision Transformers
MobileViTv2 in 2023 TMLR, Improves MobileViTv1 in 2022 ICLR

Separable Self-attention for Mobile Vision Transformers
MobileViTv2, by Apple Inc.
2023 TMLR, Over 170 Citations (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer] [CrossFormer++] [FastViT] [EfficientFormerV2]
==== My Other Paper Readings Are Also Over Here ====
- It’s been a while not having story about image classification paper.
- MobileViTv1 is the multi-headed self-attention (MHA) in Transformers, which requires O(k²) time complexity with respect to the number of tokens.
- This paper introduces a separable self-attention method with linear complexity, i.e. O(k).
Outline
- MobileViTv2
- Results
1. MobileViTv2

1.1. MHA in Transformer
- MHA in Transformer feeds an input x, comprising of k d-dimensional token (or patch) embeddings to 3 branches, namely query Q, key K, and value V. Each branch (Q, K, and V) is comprised of h linear layers.
- The dot-product between the output of linear layers in Q and K is then computed simultaneously for all h heads, and is followed by a softmax operation σ to produce an attention (or context-mapping) matrix a.
- The outputs of h heads are concatenated to produce a tensor with k d-dimensional tokens, which is then fed to another linear layer with weights WO, to produce the output of MHA y. Mathematically:
- where the symbol ⟨·, ·⟩ denotes the dot-product operation.
1.2. MHA in Linformer
- In Linformer, MHA in (a) is extended by introducing token projection layers, which project k tokens to a pre-defined number of tokens p, thus reducing the complexity from O(k²) to O(k).
- However, it still uses costly operations (e.g., batch-wise matrix multiplication) for computing self-attention.
1.3. Separable self-attention in Proposed MobileViTv2

- Similar to MHA, the input x is processed using 3 branches, i.e., input I, key K, and value V.
- The input branch I maps each d-dimensional token in x to a scalar using a linear layer with weights WI. The weights WI serves as the latent node L, as in Fig. 4(b). This linear projection is an inner-product operation and computes the distance between latent token L and x, resulting in a k-dimensional vector. A softmax operation is then applied to this k-dimensional vector to produce context scores cs.
- The context scores cs are used to compute a context vector cv. Specifically, the input x is linearly projected to a d-dimensional space using key branch K with weights WK to produce an output xK.
- The context vector cv then computed as a weighted sum of xK as:
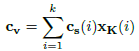
As seen, the context vector cv is analogous to the attention matrix a in the sense that it also encodes the information from all tokens in the input x, but is cheap to compute. The contextual information encoded in cv is shared with all tokens in x.
- In branch V, the input x is linearly projected with weights WV, followed by ReLU to produce an output xV.
- The contextual information in cv is then propagated to xV via broadcasted element-wise multiplication operation. The resultant output is then fed to another linear layer with weights WO to produce the final output Y. Mathematically:
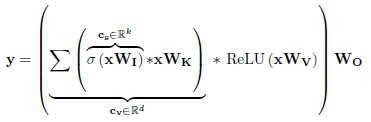
1.4. Model Variants
- The width of MobileViTv2 network is uniformly scaled using a width multiplier α ∈ {0.5, 2.0}. This is in contrast to MobileViTv1 which trains three specific architectures (XXS, XS, and S) for mobile devices.
2. Results
2.1. Inference Time of Self-Attention Blocks

3× improvement in inference speed is obtained by proposed MobileViTv2 with similar performance on the ImageNet-1k dataset.
2.2. Comparison With MobileViTv1
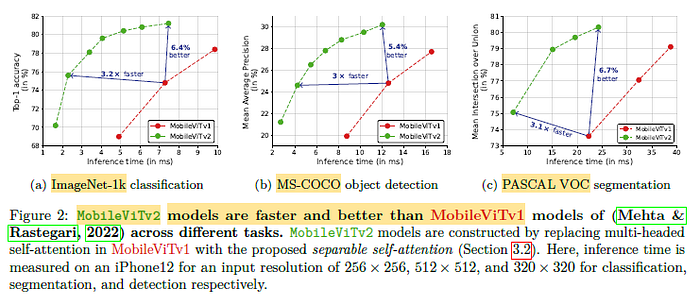
The proposed separable self-attention is fast and efficient as compared to MobileViTv1.
2.3. SOTA Comparisons on Image Classification
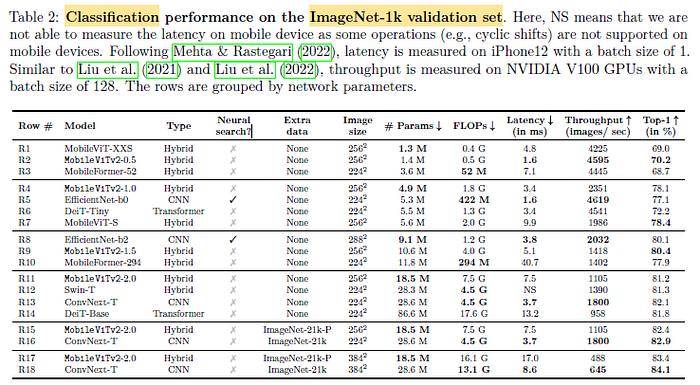
MobileViTv2 bridges the latency gap between CNN- and ViT-based models on mobile devices while maintaining performance with similar or fewer parameters.
2.4. Downstream Tasks
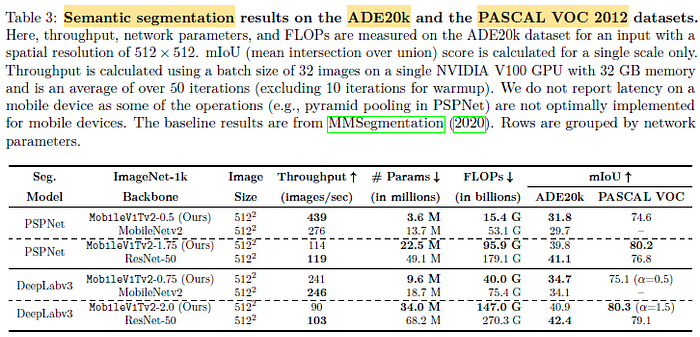
MobileViTv2 delivers competitive performance at different complexities while having significantly fewer parameters and FLOPs.
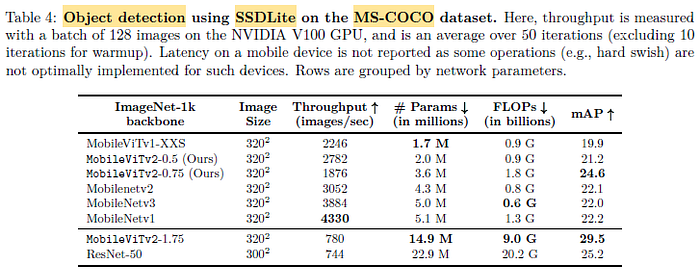
MobileViTv2 delivers competitive performance to models with different capacities, further validating the effectiveness of the proposed self-separable attention method.
