Review — FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
FastViT, Better Accuracy-Latency Trade-Off

A Fast Hybrid Vision Transformer using Structural Reparameterization
FastViT, by Apple
2023 ICCV (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer] [CrossFormer++]
==== My Other Paper Readings Are Also Over Here ====
- A mixing operator, RepMixer, a building block of FastViT, is proposed that uses structural reparameterization to lower the memory access cost by removing skip-connections in the network.
- Train-time overparametrization and large kernel convolutions are further applied to boost accuracy and empirically show that these choices have minimal effect on latency.
Outline
- FastViT
- Results
1. FastViT

- FastViT applies different architectural choices onto PoolFormer to improve the model: RepMixer, Factorized Dense Convolution, Linear Train-Time Reparameterization, and Large Kernel Convolution.

Each Component Contribute to FastViT.
1.1. Reparameterizing Skip Connections
1.1.1. RepMixer
- Convolutional mixing was first introduced in ConvMixer:

- where σ is a non-linear activation function and BN is Batch Normalization and DWConv is depthwise convolutional layer.
The operations are reaaranged and the non-linear activation function is removed as shown below:

At inference time, it can be reparameterized to a single depthwise convolutional layer as shown below:

1.1.2. Positional Encodings

Conditional positional encodings, in Twins and CPVT, that is dynamically generated and conditioned on the local neighborhood of the input tokens. These encodings are generated as a result of a depth-wise convolution operator and are added to the patch embeddings.
There is lack of non-linearities in this group of operations, hence this block can be reparameterized.
- It is found that at 384×384 using RepMixer will lower the latency by 25.1% and at larger resolutions like 1024×1024, latency is lowered significantly by 43.9%.
1.2. Factorized Dense Convolution
All dense k×k convolutions are replaced with its factorized version, i.e. k×k depthwise followed by 1×1 pointwise convolutions.
1.3. Linear Train-Time Reparameterization

Linear train-time overparameterization as in MobileOne is applied. MobileOne-style overparameterization is used in stem, patch embedding, and projection layers which help in boosting performance.
- From Table 3, this train-time overparameterization improves Top-1 accuracy on ImageNet by 0.6% on FastViT-SA12 model. On a smaller FastViT-S12 variant, Top-1 accuracy improves by 0.9% as in Table 1.
1.4. Large Kernel Convolutions
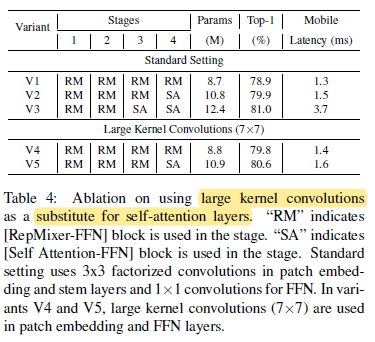
- A computationally efficient approach to improve the receptive field of early stages that do not use self-attention is by incorporating depthwise large kernel convolutions.
Depthwise large kernel convolutions are introduced in FFN and patch embedding layers.
- From Table 4, it is noted that variants using depthwise large kernel convolutions can be highly competitive to variants using self-attention layers while incurring a modest increase in latency.
- Overall, as in Table 1, large kernel convolutions provide 0.9% improvement in Top-1 accuracy on FastViT-S12.
1.5. FastViT Variants
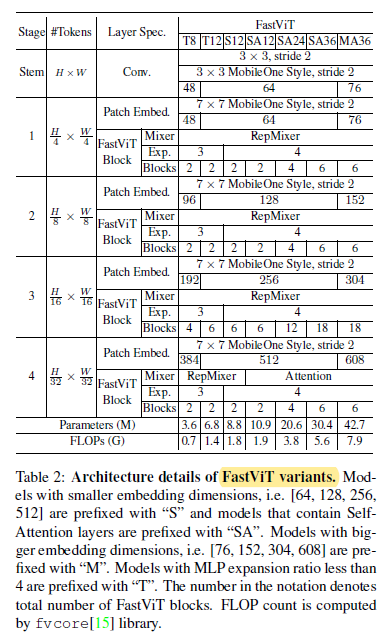
FastViTs of different scales are designed as above.
2. Results

2.1. Image Classification
Table 5: FastViT improve over LITv2 [42] on both parameter count and FLOPs.
- At Top-1 accuracy of 84.9%, FastViT-MA36 is 49.3% smaller and consumes 55.4% less FLOPs than LITv2-B. FastViT-S12 is 26.3% faster than MobileOne-S4 on iPhone 12 Pro and 26.9% faster on GPU.
- At Top-1 accuracy of 83.9%, FastViT-MA36 is 1.9× faster than an optimized ConvNeXt-B model on iPhone 12 Pro and 2.0× faster on GPU.
- At Top-1 accuracy of 84.9%, FastViT-MA36 is just as fast as NFNet-F1 on GPU while being 66.7% smaller and using 50.1% less FLOPs and 42.8% faster on mobile device.
2.2. Knowledge Distillation
Table 6: With Distillation, FastViT-SA24 attains similar performance as EfficientFormer-L7 while having 3.8× less parameters, 2.7× less FLOPs and 2.7× lower latency.
2.3. Robustness Evaluation
Table 7: FastViT is highly competitive to RVT and ConvNeXt, in fact FastViT-M36 has better clean accuracy, better robustness to corruptions and similar outof- distribution robustness as ConvNeXt-S which has 6.1M more parameters and has 10% more FLOPs than our model.
2.4. 3D Hand Mesh Estimation
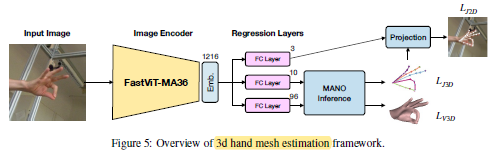
- The 3D hand mesh estimation backbones usually belong to ResNet or MobileNet family of architectures with the exception of METRO and MeshGraphormer which use HRNets.
- With FastViT uses as backbone, authors also replace the complex mesh regression head with a simple regression module.
Table 8: Amongst real-time methods, FastViT outperforms other methods on all joint and vertex error related metrics while being 1.9× faster than MobileHand [16] and 2.8× faster than recent state-of-art MobRecon.

2.5. Semantic Segmentation
Table 9: FastViT-MA36 model obtains 5.2% higher mIoU than PoolFormer-M36 which has higher FLOPs, parameter count and latency on both desktop GPU and mobile device.
2.6. Object Detection and Instance Segmentation
Table 10: FastViT-MA36 model has similar performance as CMT-S, while being 2.4× and 4.3× faster on desktop GPU and mobile device respectively.
