Brief Review — On the Relationship between Self-Attention and Convolutional Layers
Self-Attention Layers Attend to Pixel-Grid Patterns Similarly to CNN Layers

On the Relationship between Self-Attention and Convolutional Layers,
Cordonnier ICLR’20, by École Polytechnique Fédérale de Lausanne (EPFL)
2020 ICLR, Over 200 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Self-Attention, Transformer
- Do self-attention layers process images in a similar manner to convolutional layers? This work provides evidence that attention layers can perform convolution.
Outline
- Proof of Lemma
- Results
1. Proof of Lemma
- This paper focus on mathematical proof and experimental analysis whether the self-attention layer can perform like a convolutional layer.
- (To post all here, it involves many preliminaries on both self-attention and convolution, which makes the story long. Thus, I don’t want to focus too much on the equation. But I can show one lemma proof in a very brief way.
- For mathematical proof, it is much much better to read the paper directly, following the flow by author.)
1.1. Lemma 1

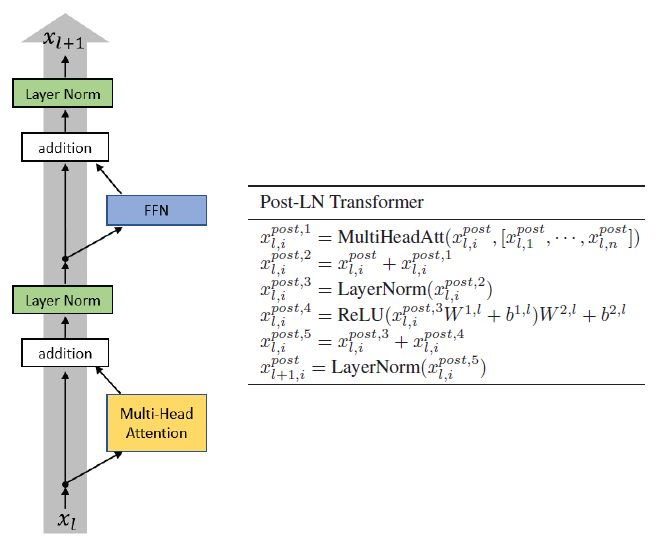
- First, Multi-Head Self-Attention (MHSA) is reworked:

- Assuming that Dh≥Dout, each pair of matrices can be replaced by a learned matrix W(h) for each head. One output pixel of the multi-head self-attention is considered as:

- Due to the conditions of the Lemma, for the h-th attention head the attention probability is one when k=q-f(h) and zero otherwise. The layer’s output at pixel q is thus equal to:

For K=√(Nh), MHSA can be seen to be equivalent to a convolutional layer. i.e. in the form of ΣXW+b.
1.2. Lemma 2

- (There is also Lemma 2 for relative encoding scheme as shown above, please read the paper directly for more details if interested.)
2. Results
- This paper, as said by the paper title, authors want to analyze the relationship between self-attention and convolutional layers. They do not focus on boosting the accuracy.
2.1. Classification Accuracy
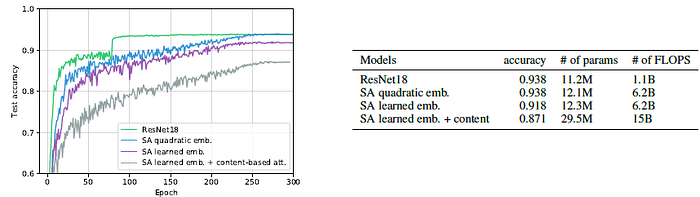
- Standard ResNet-18 is used for comparison on the CIFAR-10. A 2×2 invertible down-sampling, used in iRevNet, is applied on the input to reduce the size of the image because full attention cannot be applied to bigger images due to large memory consumption.
- The ResNet is faster to converge.
It is observed that learned embeddings with content-based attention were harder to train probably due to their increased number of parameters. The performance gap can be bridged to match the ResNet performance, but this is not the focus of this work.
2.2. Analysis
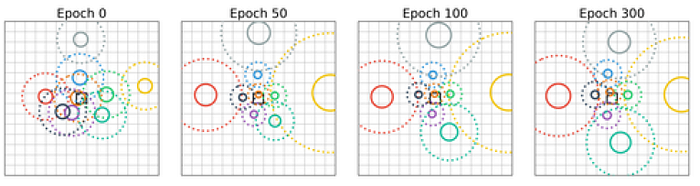
Self-Attention applied to images learns convolutional filters around the queried pixel is confirmed.

- The above figure shows all attention head at each layer of the model at the end of the training.
In the first few layers the heads tend to focus on local patterns (layers 1 and 2), while deeper layers (layers 3–6) also attend to larger patterns by positioning the center of attention further from the queried pixel position.
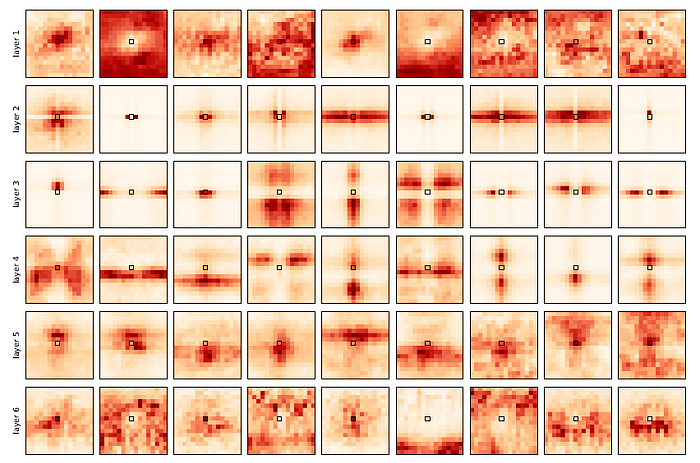
Certain self-attention heads only exploit position-based attention to attend to distinct pixels at a fixed shift from the query pixel reproducing the receptive field of a convolutional kernel.
Authors also provide a GitHub website. From there, we can have more understanding by visually watching the interaction of attention weights on different locations of some sample images, which is interesting.
References
[2020 ICLR] [Cordonnier ICLR’20]
On the Relationship between Self-Attention and Convolutional Layers
[GitHub]
https://epfml.github.io/attention-cnn/
1.1. Image Classification
1989 … 2020 [Cordonnier ICLR’20] … 2022 [ConvNeXt] [PVTv2] [ViT-G]