Review — Scaling Vision Transformers
2-Million-Parameter ViT-G Obtained by Model Scaling, Outperforms ViT, SimCLRv2, BYOL, DINO
Scaling Vision Transformers
ViT-G, by Google Research, Brain Team, Zürich
2022 CVPR, Over 100 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT, Model Scaling, Data Scaling
- Scaling for ViT is not addressed before. In this paper, ViT models and data, are both scaled up and down, where
- The architecture and training of ViT are refined for reducing memory consumption and increasing accuracy.
- Finally, a ViT model with two billion parameters, ViT-G, is evaluated and compared with other state-of-the-art approaches.
1. Improvements to the ViT model and Training

- Different ViT models are trained as above.
- Among them, ViT-G/14 is the largest one, which contains nearly two billion parameters.
1.1. Decoupled weight decay for the “head”

- Weight decay has a drastic effect on model adaptation in the low-data regime.
- One can benefit from decoupling weight decay strength for the final linear layer (“head”), and for the remaining weights (“body”) in the model.
- Left and Middle: A collection ViT-B/32 models on JFT-300M is evaluated, each cell corresponds to the performance of different head/body weight decay values.
High weight decay in the head decreases performance on the pre-training (upstream) task (not shown), despite improving transfer performance.
1.2. Saving Memory by Removing [class] Token
- ViT models have an extra [class] token, which is used to produce the final representation, bringing the total number of tokens to 257 (256 visual tokens + 1 class token).
- Global average pooling (GAP) and multihead attention pooling (MAP) [24] are tried to aggregate representation from all patch tokens, as an alternative of extra class token.
- To further simplify the head design, the final non-linear projection before the final prediction layer is also removed.
- Right: All heads perform similarly, while GAP and MAP are much more memory efficient, and the non-linear projection can be safely removed. Finally, MAP is adopted.
1.3. Scaling Up Data

- The proprietary JFT-3B dataset, a larger version of the JFT-300M, is used, which has 3B images.
Both small and large models benefit from scaling up data, by an approximately constant factor, both for linear few-shot evaluation (left) and transfer using the full dataset (right).
1.4. Others
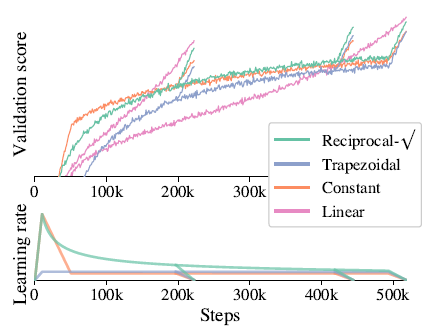
- The proposed largest model, ViT-G, has roughly two billion parameters, which occupies 8 GiB of device memory.
- Memory-efficient optimizers are used.
- Learning-rate schedules that, with warmup phase in the beginning, and a cooldown phase at the end of training, is introduced.
- The above figure the validation score (higher is better) for each of these options and their cooldowns, together with two linear schedules for reference.
- (Please feel free to read the paper directly.)
2. ViT Variants Analysis
2.1. Scaling Up Compute, Model and Data Together

- Several ViT models are trained on both public ImageNet-21k dataset and privately gathered images, up to three billion weakly-labelled images.
- The architecture size, number of training images, and training duration are varied. All models are trained on TPUv3, thus total compute is measured in TPUv3 core-days.
Left and Center: the lower right point shows the model with the largest size, dataset size and compute achieving the lowest error rate.
- However, it appears that at the largest size the models starts to saturate, and fall behind the power law frontier.
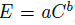
- i.e. the straight line in log-log plot.
Top-Right: The representation quality can be bottlenecked by model size.
- The large models benefit from additional data, even beyond 1B images.
Bottom-Right: The largest models even obtain a performance improvement the training set size grows from 1B to 3B images.
- In terms of the law, this saturation corresponds to an additive constant c to the error rate:
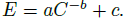
- There is also a x-axis shift, d:
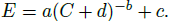
- This constant indicates that the zero-compute model will still obtain non-zero accuracy.
2.2. Big Models are More Sample Efficient
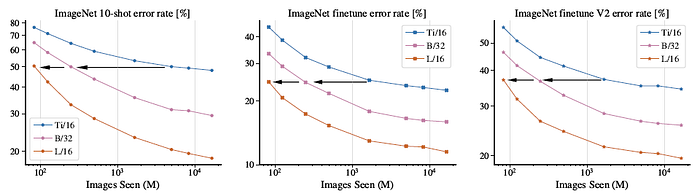
- Big models are more sample efficient, which is consistent across diverse setups: Few-shot transfer on the frozen representations, fine-tune the network on ImageNet, and evaluate the fine-tuned models on the v2 test set.
The above results suggested that with sufficient data, training a larger model for fewer steps is preferable.
2.3. Do Scaling Laws Still Apply on Fewer Images?
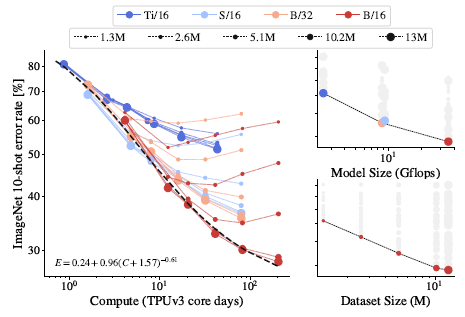
- The study is extended to much fewer images, ranging from one million to 13 millions. (To me, it is still many images, lol)
- Left: The double-saturation power law still applies.
- Right: Similar behaviors are observed that the model performance are bottlenecked by the dataset size.
When scaling up compute, model and data together, one gets the best representation quality.
3. ViT-G Results
3.1. Few-Shot Learning

- For the few-shot learning, ViT-G/14 outperforms the previous best ViT-H/14 model by a large margin (more than 5%), attaining 84.86% accuracy with 10 examples per class. Ten images per class is less than 1% of ImageNet data (13 examples per class).
- ViT-G/14 also outperforms SimCLRv2 and BYOL, using 1% of ImageNet data, and DINO using 20 examples per class. However, that these approaches are quite different: ViT-G/14 uses large source of weakly-supervised data, and is pre-trained only once and transferred to different tasks.
3.2. Other SOTA Comparisons
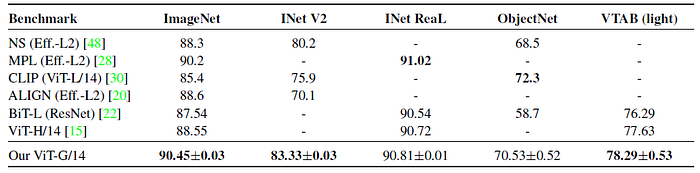
- ViT-G/14 achieves 90.45% top-1 accuracy on ImageNet, setting the new state-of-the art.
- Other datasets are also evaluated. Only a bit worse result is obtained on ObjectNet dataset.
ViT-G studies the data scaling and model scaling in a very comprehensive way, which consumes a lot of TPU days.
Reference
[2022 CVPR] [ViT-G]
Scaling Vision Transformers
1.1. Image Classification
1989 … 2022 [ConvNeXt] [PVTv2] [ViT-G]
