Review — LLaMA: Open and Efficient Foundation Language Models
LLaMA-65B, Surpasses PaLM, LaMDA, Chinchilla, Gopher, GPT-3.
LLaMA: Open and Efficient Foundation Language Models,
LLaMA, by Meta AI,
2023 arXiv v1, Over 20 Citations (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] [Chinchilla] [PaLM] [AlexaTM] [BLOOM] [AlexaTM 20B] [OPT] [Switch Transformers] [LaMDA] [LoRA] 2023 [GPT-4]
==== My Other Paper Readings Are Also Over Here ====
- LLaMA, a collection of foundation language models ranging from 7B to 65B parameters, is proposed.
- The models are trained on trillions of tokens, using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets.
- In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B.
Outline
- LLaMA
- Results
1. LLaMA
1.1. Pretraining Data

- The training dataset is a mixture of several sources, with the restriction of only using data that is publicly available, and compatible with open sourcing.
- English CommonCrawl [67%]: Five CommonCrawl dumps, ranging from 2017 to 2020, with the CCNet pipeline, with preprocessing.
- C4 [15%]: The publicly available C4 dataset.
- Github [4.5%]: Public GitHub dataset available on Google BigQuery.
- Wikipedia [4.5%]: Wikipedia dumps from the June-August 2022 period, covering 20 languages, which use either the Latin or Cyrillic scripts: bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk.
- Gutenberg and Books3 [4.5%]: Two book copora includings the Gutenberg Project, and Books3 section of ThePile.
- ArXiv [2.5%]: arXiv Latex files are added to include scientific data.
- Stack Exchange [2%]: A dump of Stack Exchange, a website of high quality questions and answers that covers a diverse set of domains, ranging from computer science to chemistry.
- The Byte Pair Encoding (BPE) algorithm using SentencePiece is used. The entire training dataset contains roughly 1.4T tokens after tokenization.
1.2. Model Architecture

- Transformer, with various improvements, is used.
- Pre-normalization [GPT-3]: To improve the training stability, the input of each Transformer sub-layer is normalized, instead of normalizing the output. RMSNorm normalizing function is used.
- SwiGLU activation function [PaLM]: ReLU is replaced by SwiGLU. A dimension of (2/3)*4d instead of 4d as in PaLM.
- Rotary Embeddings [GPT-Neo]: The absolute positional embeddings are removed. Instead, rotary positional embeddings (RoPE) is added, at each layer of the network.
- The details of different models are shown as in the above table.
- When training a 65B-parameter model, the code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over the proposed dataset containing 1.4T tokens takes approximately 21 days.
1.3. Evaluation
- A total of 20 benchmarks is evaluated using:
- Zero-shot: A textual description of the task and a test example is provided. The model either provides an answer using open-ended generation, or ranks the proposed answers.
- Few-shot: A few examples of the task (between 1 and 64) and a test example are provided.
2. Results
2.1. Common Sense Reasoning

LLaMA-65B outperforms Chinchilla-70B on all reported benchmarks but BoolQ. Similarly, this model surpasses PaLM-540B everywhere but on BoolQ and WinoGrande. LLaMA-13B model also outperforms GPT-3 on most benchmarks despite being 10× smaller.
2.2. Closed-book Question Answering
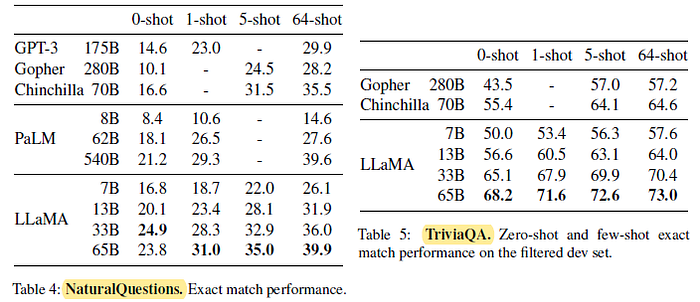
On both benchmarks, LLaMA-65B achieve state-of-the-arts performance in the zero-shot and few-shot settings.
More importantly, the LLaMA-13B is also competitive on these benchmarks with GPT-3 and Chinchilla, despite being 5–10× smaller. This model runs on a single V100 GPU during inference.
2.3. Reading Comprehension
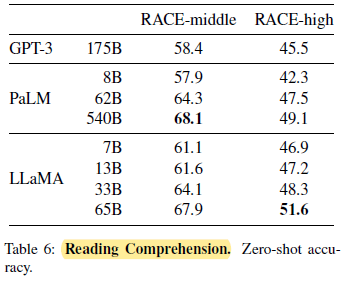
On these benchmarks, LLaMA-65B is competitive with PaLM-540B, and, LLaMA-13B outperforms GPT-3 by a few percents.
2.4. Mathematical Reasoning
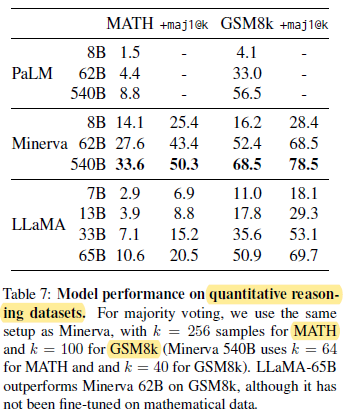
On GSM8k, LLaMA-65B outperforms Minerva-62B, although it has not been fine-tuned on mathematical data.
2.5. Code Generation
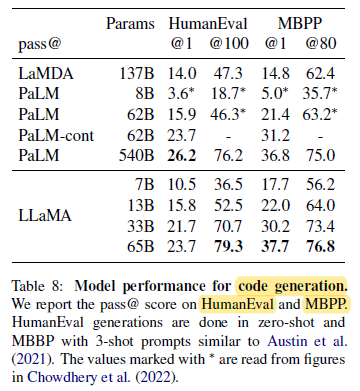
For a similar number of parameters, LLaMA outperforms other general models such as LaMDA and PaLM, which are not trained or finetuned specifically for code.
LLaMA with 13B parameters and more outperforms LaMDA 137B on both HumanEval and MBPP.
LLaMA 65B also outperforms PaLM 62B, even when it is trained longer.
2.6. Massive Multitask Language Understanding (MMLU)
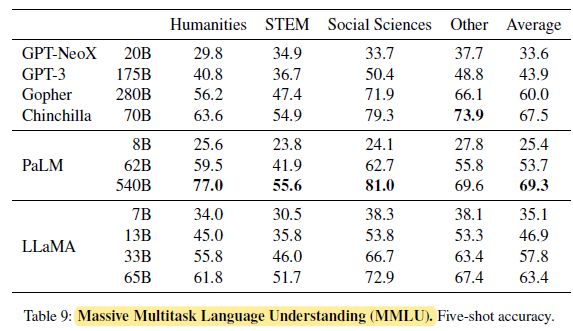
LLaMA-65B is behind both Chinchilla-70B and PaLM-540B by a few percent in average, and across most domains. A potential explanation is that a limited amount of books and academic papers is used in the pretraining data, i.e., ArXiv, Gutenberg and Books3, that sums up to only 177GB, while these models were trained on up to 2TB of books.
2.7. Evolution of Performance During Training
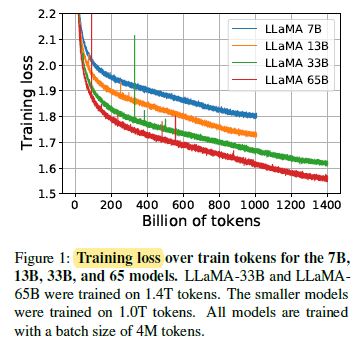
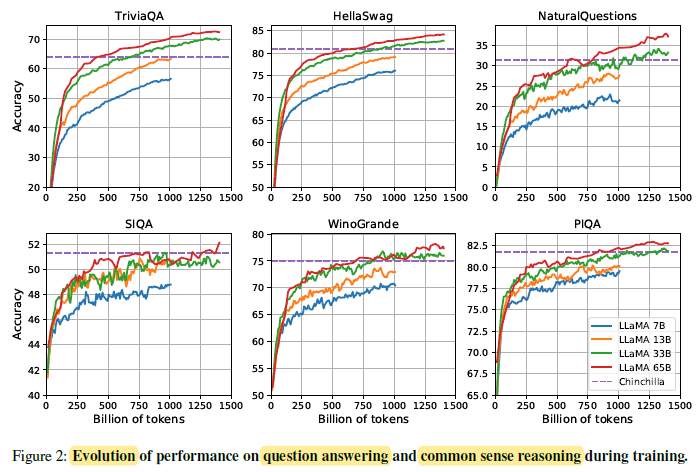
On most benchmarks, the performance improves steadily, and correlates with the training perplexity of the model.
The exceptions are SIQA and WinoGrande.
2.8. Instruction Finetuning
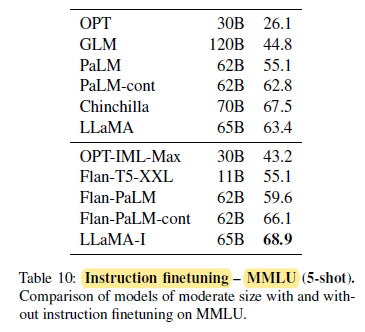
- Briefly finetuning on instructions data rapidly leads to improvements on MMLU.
- Since this is not the focus of this paper, only a single experiment following the same protocol as Chung et al. (2022) is conducted to train an instruct model, LLaMA-I.
Despite the simplicity of the instruction finetuning approach used here, 68.9% is reached on MMLU. LLaMA-I (65B) outperforms on MMLU existing instruction finetuned models of moderate sizes, but are still far from the state-of-the-art, that is 77.4 for GPT code-davinci-002 on MMLU (numbers taken from Iyer et al. (2022)).
2.9. Bias, Toxicity and Misinformation
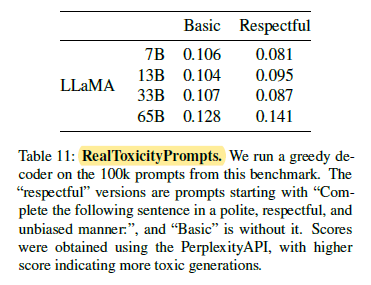
Toxicity increases with the size of the model, especially for Respectful prompts. The larger model, Gopher, has worse performance than Chinchilla, suggesting that the relation between toxicity and model size may only apply within a model family.
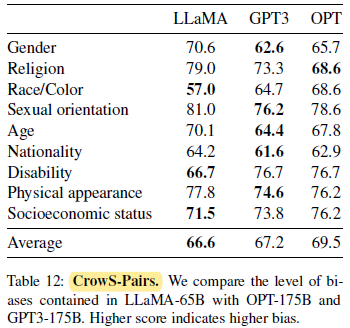
LLaMA compares slightly favorably to both models on average.
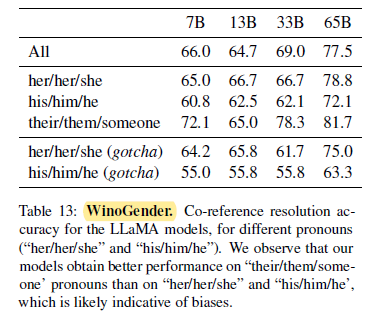
LLaMA-65B, makes more errors on the gotcha examples, clearly showing that it capture societal biases related to gender and occupation. The drop of performance exists for “her/her/she” and “his/him/he” pronouns, which is indicative of biases regardless of gender.
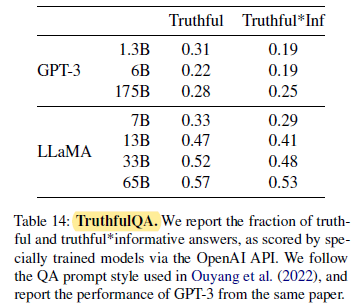
Compared to GPT-3, the model scores higher in both categories, but the rate of correct answers is still low, showing that the proposed model is likely to hallucinate incorrect answers.
2.10. Carbon Footprint
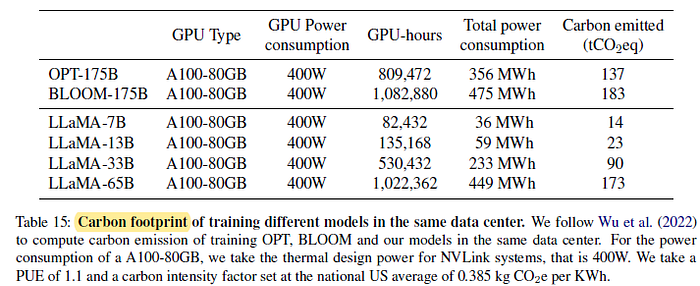
- Developing these models would have cost around 2,638 MWh under the assumptions, and a total emission of 1,015 tCO2eq.
Authors hope that releasing these models will help to reduce future carbon emission since the training is already done.
