BloombergGPT: A Large Language Model for Finance
BloombergGPT 50B, Curate Financial Data for Training, Outperforms Other LLMs Trained by General Data

BloombergGPT: A Large Language Model for Finance,
BloombergGPT, by Bloomberg, and Johns Hopkins University,
2023 arXiv v1 (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] [Chinchilla] [PaLM] [AlexaTM] [BLOOM] [AlexaTM 20B] [OPT] [Switch Transformers] [LaMDA] [LoRA] [Galactica] 2023 [GPT-4] [LLaMA] [LIMA] [Koala]
==== My Other Paper Readings Are Also Over Here ====
- BloombergGPT, a 50 billion parameter language model, is proposed that is trained on a wide range of financial data.
- A 363 billion token dataset is constructed based on Bloomberg’s extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets.
Outline
- BloombergGPT Dataset
- BloombergGPT Model
- Results
1. BloombergGPT Dataset

To train BloombergGPT, “FinPile” is constructed, which is a comprehensive dataset consisting of a range of English financial documents including news, filings, press releases, web-scraped financial documents, and social media drawn from the Bloomberg archives.
- General-purpose dataset, which is used by many LLMs, is also included so that there are half domain-specific text (51.27%) and half general-purpose text (48.73%).
2. BloombergGPT Model
- The model is a decoder-only causal language model based on BLOOM.
- The model contains L=70 layers of Transformer decoder blocks. It has an additional layer normalization after token embeddings.
- Based on scaling law by Chinchilla, with L=70, 40 heads, each having a dimension of 192, resulting in a total hidden dimension of D=7680 and a total of 50.6B parameters.
- A total of 512 40GB A100 GPUs are used. 139,200 steps (~53 days) are used for training.
3. Results
3.1. Bits Per Byte

BloombergGPT consistently outperforms GPT-Neo-X, OPT-66B, and BLOOM-176B.
3.2. Finance-Specific and General-Purpose
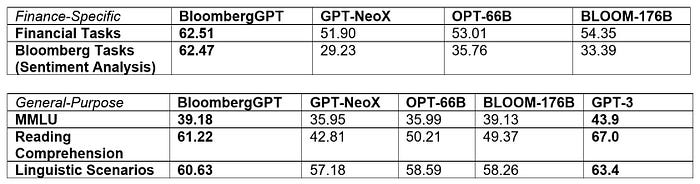
BloombergGPT obtains the best results on finance-specific tasks.
BloombergGPT also obtains the best results under similar model size, only underperforms GPT-3, while GPT-3 has 176B model size, which is much larger.
