Brief Review — TED-LIUM 3: Twice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation
TED-LIUM 3, With Better Alignment

TED-LIUM 3: Twice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation
TED-LIUM 3, by Ubiqus, and University of Le Mans
2018 SPECOM, Over 350 Citations (Sik-Ho Tsang @ Medium)Acoustic Model / Automatic Speech Recognition (ASR) / Speech-to-Text (STT)
1991 … 2020 [FAIRSEQ S2T] [PANNs] [Conformer] [SpecAugment & Adaptive Masking] [Multilingual LibriSpeech (MLS)] 2023 [Whisper]
==== My Other Paper Readings Are Also Over Here ====
- TED-LIUM release 3 corpus is released, which multiplies the available data to train acoustic models in comparison with TED-LIUM 2, by a factor of more than two.
Outline
- TED-LIUM 3
- Results
1. TED-LIUM 3
- (As there are a lot of new datasets already, here, I just present this paper in a very brief way.)
1.1. Maximizing Alignment

- To maximize the quality of alignments, the best model (at the time of corpus preparation) is trained on the previous release of the TED-LIUM corpus. This model achieved a WER of 9.2% on both development and test sets without any rescoring.
- This means the ratio of aligned speech versus audio from the original 1,495 talks of releases 1 and 2 has changed, as well as the quantity of words retained. It increased the amount of usable data from the same basis les by around 40% (Table 1).

As shown above, with better alignment, more data is obtained, WER is reduced using HMM models.
1.2. Datasets

The whole corpus is released named as a legacy version. The aligned speech (including some noises and silences) represents around 82.6% of audio duration (540 hours).

- Speaker adaptation of acoustic models (AMs) is an important mechanism to reduce the mismatch between the AMs and test data from a particular speaker.
These datasets are obtained from the proposed TED-LIUM 3 training corpus, but the development and test sets are more balanced and representative in characteristics (number of speakers, gender, duration) than the original sets.
2. Results
2.1. Models

- There are 2 kinds of models for evaluation.
- HMM: At that moment, HMM still outperforms end-to-end DNN approach.
- Fully ASR end-to-end system: This architecture is composed of nc convolution layers (CNN), followed by nr uni or bidirectional recurrent layers, a lookahead convolution layer, and one fully connected layer just before the softmax layer. CTC loss function is used. In this paper, two CNN layers and six bidirectional recurrent layers with batch normalization is used.
2.2. Performance
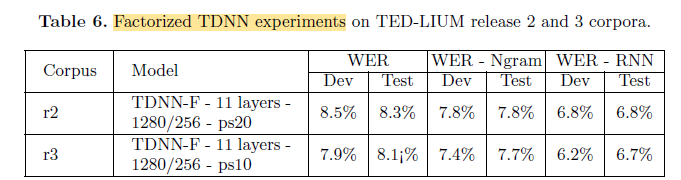
Using r3 (TED-LIUM 3), lower WERs are obtained.
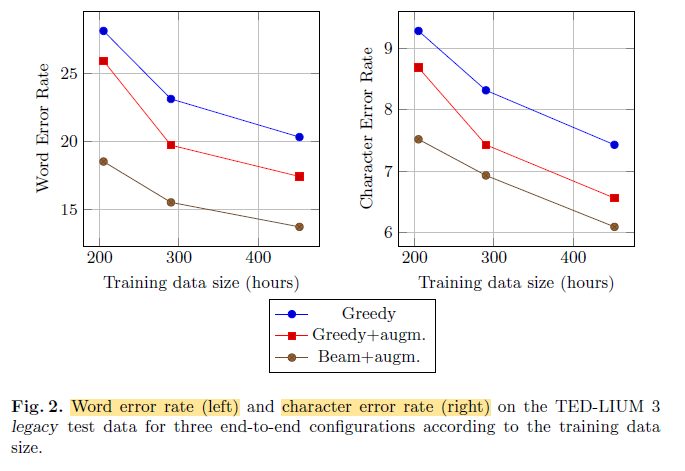
It is observed that at the very end, with TED-LIUM 3, the Greedy+augmentation con guration gets a lower WER than the Beam+augmentation one when trained with the original TED-LIUM 2 data.
- This shows that increasing the training data size for the pure end-to-end architecture offers a higher potential for WER reduction.
