Review — OpenAI Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
OpenAI Whisper for Speech-to-Text (STT)
Robust Speech Recognition via Large-Scale Weak Supervision
Whisper, by OpenAI
2023 ICML, Over 2000 Citations (Sik-Ho Tsang @ Medium)Acoustic Model / Automatic Speech Recognition (ASR) / Speech-to-Text (STT)
1991 … 2020 [FAIRSEQ S2T] [PANNs] [Conformer] [SpecAugment & Adaptive Masking]
==== My Other Paper Readings Are Also Over Here ====
- 680,000 hours of multilingual and multitask supervision results in models which are able to generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zero-shot transfer setting without fine-tuning.
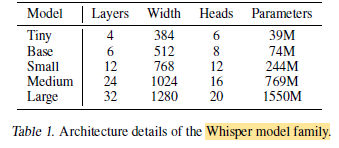
Whisper Versions
- There are multiple versions of Whisper: September 2022 (original series), December 2022 (large-v2), and November 2023 (large-v3).
Whisper-v2
large-v2model has been trained for 2.5 times more epochs, with SpecAugment, stochastic depth, and BPE dropout for regularization. Other than the training procedure, the model architecture and size remained the same as the originallargemodel, which is now renamed tolarge-v1.
Whisper-v3
- For
large-v3, Whisper-v3 has the same architecture as the previouslargemodels except the following minor differences:
- The input uses 128 Mel frequency bins instead of 80;
- A new language token for Cantonese;
- The
large-v3model is trained on 1 million hours of weakly labeled audio and 4 million hours of pseudo-labeled audio collected usinglarge-v2. The model was trained for 2.0 epochs over this mixture dataset.
Outline
- Whisper (Original Whisper-v1 in the paper)
- Results
1. Whisper (Original Whisper-v1 in the paper)

1.1. Dataset
The dataset is constructed from audio that is paired with transcripts on the Internet. This results in a very diverse dataset covering a broad distribution of audio from many different environments, recording setups, speakers, and languages. Diversity in audio quality can help train a model.
- Several automated filtering methods are used to improve transcript quality.
- An audio language detector is used, which was created by fine-tuning a prototype model trained on a prototype version of the dataset on VoxLingua107 to ensure that the spoken language matches the language of the transcript according to CLD2. If the two do not match, the (audio, transcript) pair is not included.
- hours of X!en translation data. We
Audio files are broken into 30-second segments.
Of those 680,000 hours of audio, 117,000 hours cover 96 other languages. The dataset also includes 125,000 hours of X > en translation data.
- For an additional filtering pass, after training an initial model information about its error rate is aggregated. Low-quality audios are identified and removed.
- (There are still many other steps here.)
1.2. Pre-processing
All audio is re-sampled to 16,000 Hz, and an 80-channel log-magnitude Mel spectrogram representation is computed on 25-millisecond windows with a stride of 10 milliseconds.
- For feature normalization, the input is globally scaled to be between -1 and 1 with approximately zero mean across the pre-training dataset.
1.3. Model
- An encoder-decoder Transformer is used.
- The encoder processes this input representation with a small stem consisting of two convolution layers with a filter width of 3 and the GELU activation where the second convolution layer has a stride of two.
- Sinusoidal position embeddings are then added to the output of the stem.
- The Transformer uses pre-activation residual blocks and a final layer normalization is applied to the encoder output.
- The decoder uses learned position embeddings and tied input-output token representations.
- The same byte-level BPE text tokenizer used in GPT-2, is used.
1.4. Multitask Format
- A fully featured speech recognition system can involve many additional components such as voice activity detection, speaker diarization, and inverse text normalization.
- A single model perform the entire speech processing pipeline is preferred.
- The beginning of prediction is started with a <|startoftranscript|> token.
- First, the language being spoken is predicted, which is represented by a unique token for each language in the training set (99 total). These language targets are sourced from the aforementioned VoxLingua107 model.
- If there is no speech in an audio segment, the model is trained to predict a <|nospeech|> token.
- The next token specifies the task (either transcription or translation) with an <|transcribe|> or <|translate|> token.
- After this, Whisper specifies whether to predict timestamps or not by including a <|notimestamps|>.
- For timestamp prediction, the time relative to the current audio segment is predicted, quantizing all times to the nearest 20 milliseconds.
- These additional tokens are added to the vocabulary for each of these.
- Ttheir prediction are interleaved with the caption tokens: the start time token is predicted before each caption’s text, and the end time token is predicted after.
- Lastly, a <|endoftranscript|> token is added.
- The above figure shows an example.
1.5. Training Details
- Data parallelism is used across accelerators using FP16 with dynamic loss scaling and activation checkpointing.
- A batch size of 256 segments was used, and the models are trained for 2²⁰ updates which is between 2 and 3 passes over the dataset.
- No augmentation and no regularization, purely depends on diverse data.
2. Results
2.1. Zero-shot Evaluation


- Zero-shot Whisper model has a relatively unremarkable LibriSpeech clean-test WER of 2.5, which is roughly the performance of modern supervised baseline or the mid-2019 state of the art.
Zero-shot Whisper models have very different robustness properties than supervised LibriSpeech models and out-perform all benchmarked LibriSpeech models by large amounts on other datasets.
When compared to a human in Figure 2, the best zero-shot Whisper models roughly match their accuracy and robustness.
- zero-shot and out-of-distribution evaluations of models, particularly when attempting to compare to human performance, to avoid overstating the capabilities of machine learning systems due to misleading comparisons.
2.2. Multilingual Speech Recognition
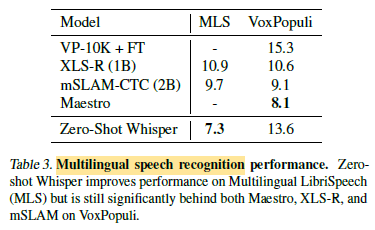
Whisper performs well on Multilingual LibriSpeech (MLS), outperforming XLS-R, mSLAM and Maestro in a zero-shot setting.

Figure 3: Strong squared correlation coefficient of 0.83 between the log of the word error rate and the log of the amount of training data per language. Checking
2.3. Speech Translation
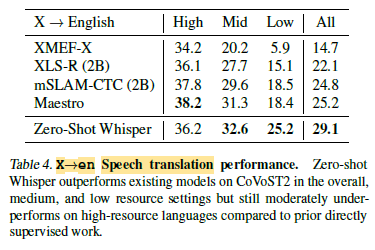
Figure 4: While there is a clear trend of improvement with increasing training data, the squared correlation coefficient is much lower than the 0.83 observed for speech recognition and only 0.24.
2.4. Language Identification
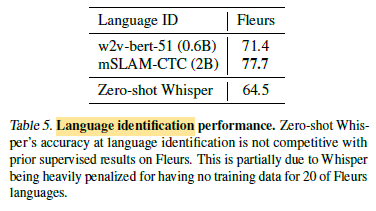
The zero-shot performance of Whisper is not competitive with prior supervised work here and underperforms the supervised SOTA by 13.6% on Fleurs, since the Whisper dataset contains no training data for 20 of the 102 languages in Fleurs.
2.5. Robustness to Additive Noise
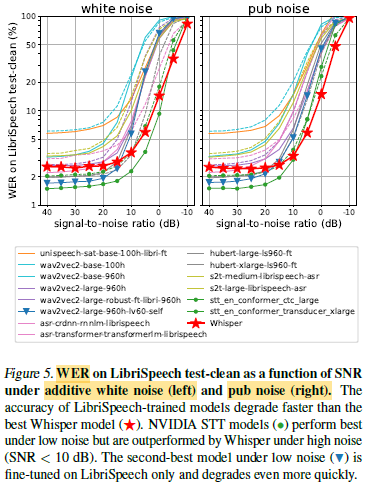
- All models quickly degrade as the noise becomes more intensive.
The above figure showcases Whisper’s robustness to noise (Red Star Line, The Lower, The Better), especially under more natural distribution shifts like the pub noise.
2.6. Long-form Transcription
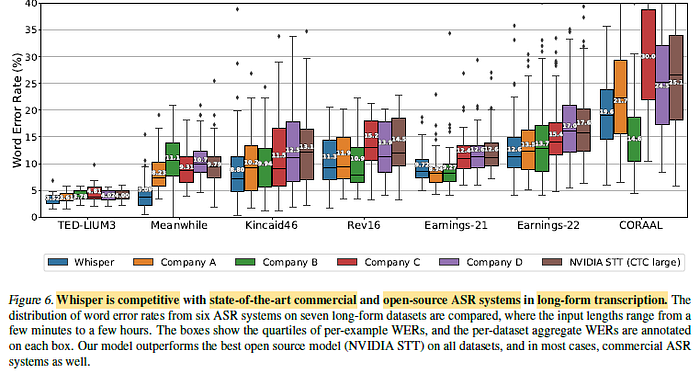
- A strategy is developed to perform buffered transcription of long audio by consecutively transcribing 30-second segments of audio and shifting the window according to the timestamps predicted by the model.
- It is crucial to have beam search and temperature scheduling based on the repetitiveness and the log probability of the model predictions in order to reliably transcribe long audio.
Whisper performs better than the compared models on most datasets, especially on the Meanwhile dataset which is heavy with uncommon words.
- Yet, it is noted that the possibility that some of the commercial ASR systems have been trained on some of these publicly available datasets, and therefore these results may not be accurately reflecting the relative robustness of the systems.
2.7. Comparison with Human Performance
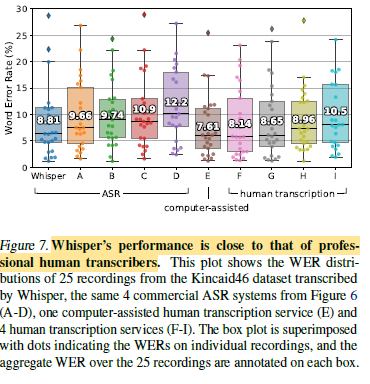
The pure-human performance is only a fraction of a percentage point better than Whisper’s. Whisper’s English ASR performance is not perfect but very close to human-level accuracy.
2.8. Model Scaling
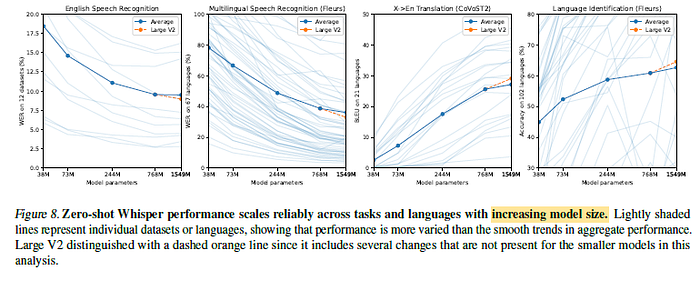
With the exception of English speech recognition, performance continues to increase with model size across multilingual speech recognition, speech translation, and language identification.
2.9. Dataset Scaling
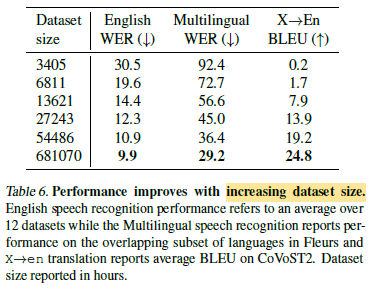
- At 680,000 hours of labeled audio, the Whisper dataset is one of the largest ever created in supervised speech recognition.
- 0.5%, 1%, 2%, 4%, and 8% of the full dataset size are trained.
All increases in the dataset size result in improved performance on all tasks.
- (There are still other experiments, please feel free to read the paper directly if interested.)
