Brief Review — TED-LIUM: an Automatic Speech Recognition dedicated corpus
Digging Into Early Research Development for ASR/STT
4 min readNov 20, 2024
TED-LIUM: an Automatic Speech Recognition dedicated corpus
TED-LIUM, by University of Le Mans,
2012 LREC, Over 320 Citations (Sik-Ho Tsang @ Medium)Acoustic Model / Automatic Speech Recognition (ASR) / Speech-to-Text (STT)
1991 … 2020 [FAIRSEQ S2T] [PANNs] [Conformer] [SpecAugment & Adaptive Masking] [Multilingual LibriSpeech (MLS)] 2023 [Whisper]
==== My Other Paper Readings Are Also Over Here ====
- This paper presents the corpus developed by the LIUM for Automatic Speech Recognition (ASR), based on the TED Talks. This corpus was built during the IWSLT 2011 Evaluation Campaign, and is composed of 118 hours of speech with its accompanying automatically aligned transcripts.
- This paper describes the content of the corpus, how the data was collected and processed, how it will be publicly available and how an ASR system built using this data leading to a WER score of 17.4%.
- Later, there are TED-LIUM 2 in 2014 LREC and TED-LIUM 3 in 2018 SPECOM published.
Outline
- The TED-LIUM ASR corpus
- ASR Architecture
- Results
1. The TED-LIUM ASR corpus
1.1. Corpus

- In brief, the first step is to generate proper alignments between the speech and the closed captions, using different software tools for segmentation, clustering, and alignment. This helped to remove the worst-aligned talks, and left with 794 talks representing 135 hours of speech: 91 hours of male and 44 hours of female.

- This first iteration (the bootstrap) led to train new acoustic models based on these 135 hours of speech. Then, by performing a forced alignment and decoding all of the speech data again, a more accurate set of reference STM files is generated. At this stage, there were 779 talks, for an amount of speech of 152 hours, 106 hours of male and 46 hours of female.
- Starting from this data, and for a third time, a new acoustic model are trained.
In the end, the TED corpus is composed of a total of 774 talks, representing 118 hours of speech: 82 hours of male and 36 hours of female.
1.2. Development corpus for ASR
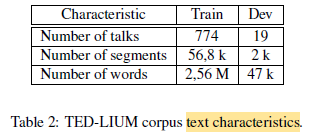
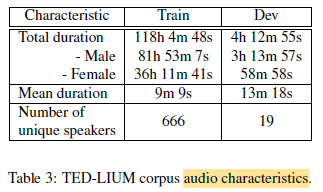
- The corpus is divided into training set and development set as above.
- (At that moment, it seems that there was no test set concept?)
2. ASR Architecture
- Vocabulary: To select the optimal vocabulary, unigram language models are trained on each monolingual corpus proposed for the IWSLT 2011 task, plus TED and HUB4.
- Language Model: Several 4-gram LMs are trained.
- Acoustic Model: The acoustic models were trained where in a multi-layer perceptron (MLP) using the bottleneck feature extraction is added.
- The input speech representation of MLP is a concatenation of nine frames of thirty-nine MFCC coefficients. The topology of the MLP is the following: the first hidden layer is composed of 4000 neurons, the second one, used as the decoding output, of 40 neurons and the third one, used for training, of 123 neurons (41 phonemes, 3 states per phoneme).
- For the decoding, a Principal Components Analysis (PCA) transformation on the 40 parameters is first performed. The second one is made of 39 standard PLP features.
- At the end, a 5-pass model is proposed, which composed of the above models with additional decoding steps. (Please see the paper if interested.)
3. Results

- The best performing one, from MIT, used similar collection technique as authors, except that they filtered utterances with a Word Error Rate superior to 20%. This yielded 164 hours of audio data from TED talks (Aminzadeh et al., 2011).
- The second best performing system, used about 450 hours of audio from various sources (EPPS, HUB4, Quaero…) but no TED audio data.
The proposed 5-pass model ranked third in the IWSLT 2011 evaluation campaign. (17.4 percent WER).
