[Paper] DB-CNN: Deep Bilinear Convolutional Neural Network (Image Quality Assessment)
1 CNN for Synthetic Distortions, 1 CNN for Authentic Distortions, Outperforms DeepIQA (DIQaM & WaDIQaM)
5 min readNov 8, 2020

In this story, Blind Image Quality Assessment Using A Deep Bilinear Convolutional Neural Network (DB-CNN), by Wuhan University, New York University, and University of Waterloo, is presented. I read this because I recently study IQA/VQA. In this paper:
- For synthetic distortions, a CNN is pre-trained to classify image distortion type and level.
- For authentic distortions, a pretrained CNN for image classification is adopted.
- The features from the two CNNs are pooled bilinearly into a unified representation for final quality prediction.
- The entire model is fine-tuned on target subject-rated databases.
This is a paper in 2020 TCVST where TCSVT has a high impact factor of 4.133. (Sik-Ho Tsang @ Medium)
Outline
- CNN for Synthetic Distortions
- CNN for Authentic Distortions
- DB-CNN by Bilinear Pooling
- Ablation Study
- Experimental Results
1. CNN for Synthetic Distortions

- A CNN is pre-trained to classify the distortion type and the degradation level. This pre-training strategy is to offer perceptually more meaningful initializations.
- M-class one-hot vector is used as ground-truth. In this case, M = 39, which corresponds to seven distortion types with five levels and two distortion types with two levels.

- Inspired by the VGG-16 network architecture [21], a CNN for synthetic distortions (S-CNN) is designed with a similar structure subject to some modifications.
- All convolutions have a kernel size of 3×3.
- Cross-entropy loss is used.
2. CNN for Authentic Distortions
- VGG-16 that has been pre-trained for the image classification task on ImageNet, is used to extract relevant features for authentically distorted images.
3. DB-CNN by Bilinear Pooling

- Bilinear pooling to combine S-CNN for synthetic distortions and VGG-16 for authentic distortions into one unified model.
- Denote the representations from S-CNN and VGG-16 by Y1 and Y2, the bilinear pooling of Y1 and Y2 is formulated as:

- Then B is fed to a fully connected layer with one output value to predict the image quality score.
4. Ablation Study

- S-CNN or VGG-16 alone is act as baseline. S-CNN and VGG-16 can only deliver promising performance on synthetic and authentic databases, respectively.
- DB-CNN with concatenation used instead of bilinear pooling.
- Two DB-CNN models are trained, one from scratch and the other using the distortion type information only during pre-training S-CNN.
- It can be seen that, with perceptually more meaningful initializations, DB-CNN achieves better performance. DB-CNN is capable of handling both synthetic and authentic distortions.
5. Experimental Results
5.1. SOTA Comparison

- LIVE contains 779 distorted images synthesized from 29 reference images with five distortion types.
- CSIQ is composed of 866 distorted images generated from 30 reference images, including six distortion types.
- TID2013 consists of 3; 000 distorted images from 25 reference images with 24 distortion types at five degradation levels.
- LIVE MD contains 450 images generated from 15 source images under two multiple distortion scenarios.
- LIVE CL is an authentic IQA database, which contains 1,162 images captured from diverse real-world scenes by numerous photographers.
- Two splits are used. 80% is used for fine-tuning DB-CNN. 20% is used for testing.
- While all competing models, such as DeepIQA (DIQaM & WaDIQaM) achieve comparable performance on LIVE, their results on CSIQ and TID2013 are rather diverse.
- DB-CNN performs favorably although it does not include multiply distorted images for pre-training, indicating that DB-CNN generalizes well to slightly different distortion scenarios.
- The success of DB-CNN on LIVE Challenge verifies the relevance between the high-level features from VGG-16 and the authentic distortions.
In summary, DB-CNN achieves superior performance on both synthetic and authentic IQA databases.
5.2. Individual Distortion Types
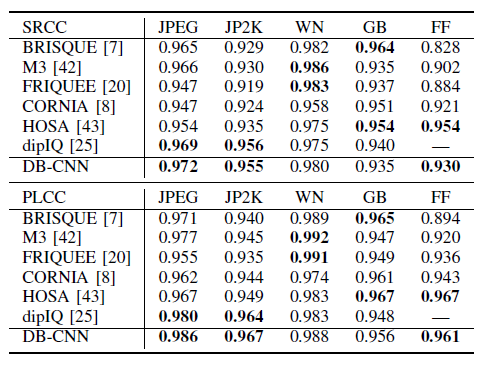
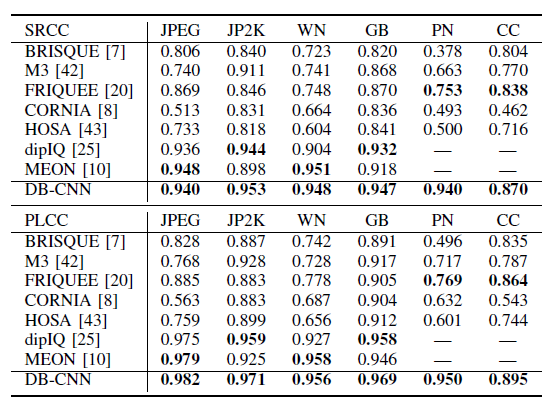

- On CSIQ, DB-CNN outperforms other counterparts by a large margin, especially for pink noise and contrast change, validating the effectiveness of pre-training in DB-CNN.
- Although many distortion types are not synthesized as in TID2013, it can be found that DB-CNN performs well on unseen distortion types that exhibit similar artifacts in our pre-training set.
- DB-CNN generalizes well to unseen distortions with similar perceived artifacts. In addition, all other non-reference (NR) models fail in three distortion types on TID2013.
5.3. Across Different Databases

- It can be seen that models trained on LIVE are much easier to generalize to CSIQ and vice versa than other cross-database pairs.
- When trained on TID2013 and tested on the other two synthetic databases, DB-CNN significantly outperforms the rest models.
- Models trained on synthetic databases do not generalize to the authentic LIVE Challenge Database. Despite this, DB-CNN still achieves higher prediction accuracies under such a challenging experimental setup.
5.4. Waterloo Exploration Database
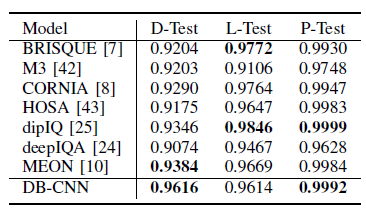
- Authors also propose a database, Waterloo Exploration Database.
- Waterloo Exploration Database and the PASCAL VOC Database, are used, where the images are synthesized with nine distortion types and two to five distortion levels.
- The pristine/distorted image discriminability test (D-Test), the list-wise ranking consistency test (L-Test), and the pairwise preference consistency test (P-Test), are performed.
- To ensure the independence of image content during training and testing, the S-CNN stream is re-trained in DB-CNN using the distorted images generated from the PASCAL VOC Database only.
- It is observed that DB-CNN is competitive in all the three tests.
References
[2020 TCSVT] [DB-CNN]
Blind Image Quality Assessment Using A Deep Bilinear Convolutional Neural Network
[Waterloo Exploration Database]
https://ece.uwaterloo.ca/~k29ma/exploration/
Image Quality Assessment (IQA)
FR: [DeepSim] [DeepIQA]
NR: [IQA-CNN] [IQA-CNN++] [DeepCNN] [DeepIQA] [DeepBIQ] [MEON] [DB-CNN]
