Brief Review — Bidirectional LSTM
The First Paper Proposing Bidirectional LSTM
1) Framewise Phoneme Classification with Bidirectional LSTM Networks, by IDSIA, 2) Bidirectional LSTM Networks for Improved Phoneme Classification and Recognition, by IDSIA, and TU München, and 3) Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, by IDSIA, and TU München
Bidirectional LSTM (BLSTM), 1) 2005 IJCNN, Over 470 Citations, 2) 2005 ICANN, Over 770 Citations, 3) 2005 JNN, Over 4000 Citations (Sik-Ho Tsang @ Medium)
LSTM, Sequence Model, RNN
- We always hear about bidirectional LSTM, but which is the first paper proposing bidirectional LSTM?
- In 1) 2005 IJCNN, authors mentions: “In this paper, we apply bidirectional training to a Long Short Term Memory (LSTM) network for the first time.”;
- In 2) 2005 ICANN, the same group of authors, extend the work of 1) 2005 IJCNN.
- In 3) 2005 JNN, it is an invited paper talking about bidirectional LSTM, which gains the highest number of citations.
- So, these three papers, coming from the same research group, should be probably the first work having the bidirectional LSTM.
Outline
- Bidirectional LSTM (2005 ICANN)
- Results in 2005 ICANN
- Results in 2005 JNN
1. Bidirectional LSTM (2005 ICANN)

- (It is assumed LSTM is understood, which is a memory cell for sequence model, better backpropagation capability compared with vanilla RNN.)
- Four models are evaluated: Bidirectional LSTM (BLSTM), unidirectional LSTM (LSTM), bidirectional standard RNN (BRNN), and unidirectional RNN (RNN).
- The LSTM (BLSTM) hidden layers contained 140 (93) blocks of one cell in each, and the RNN (BRNN) hidden layers contained 275 (185) units. This gave approximately 100,000 weights for each network.
- All LSTM blocks had the following activation functions: logistic sigmoids in the range [−2, 2] for the input and output squashing functions of the cell , and in the range [0, 1] for the gates.
- The non-LSTM net had logistic sigmoid activations in the range [0, 1] in the hidden layer.
- As is standard for 1 of K classification, the output layers had softmax activations, and the cross entropy objective function was used for training. There were 61 output nodes, one for each phonemes.
2. Results in 2005 ICANN
- All experiments were carried out on the TIMIT database. TIMIT contain sentences of prompted English speech, accompanied by full phonetic transcripts. It has a lexicon of 61 distinct phonemes.
- The training and test sets contain 4620 and 1680 utterances respectively. For all experiments we used 5% (184) of the training utterances as a validation set and trained on the rest.
- All the audio data is preprocessed into frames using 12 Mel-Frequency Cepstrum Coefficients (MFCCs) from 26 filter-bank channels. The log-energy and the first order derivatives of it and the other coefficients are extracted, giving a vector of 26 coefficients per frame in total.

Bidirectional nets outperformed unidirectional ones in framewise classification.
- The LSTM nets were 8 to 10 times faster to train than the standard RNNs, as well as slightly more accurate.
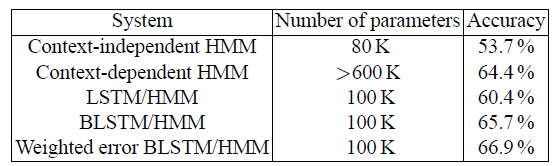
For BLSTM, this advantage carried over into phoneme recognition.
3. Results in 2005 JNN

- The above table contains the outcomes of 7, randomly initialized, training runs with BLSTM. The standard deviation in the test set scores (0.2%).
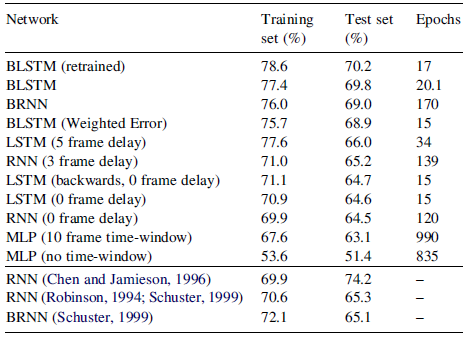
- BRNN took more than 8 times as long to converge as BLSTM.
- The training time of 17 epochs for the proposed most accurate network (retrained BLSTM) is remarkably fast, needing just a few hours on an ordinary desktop computer.
Overall BLSTM outperformed any neural network in the literature on this task.
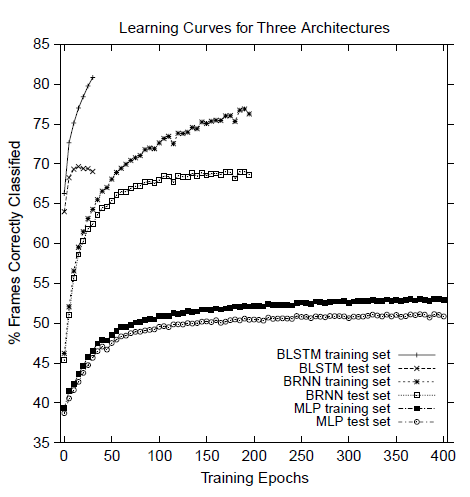
- The above figure shows the corresponding learning curve.
If I am wrong about the first paper publishing bidirectional LSTM, please feel free to tell me. :)
References
[2005 IJCNN] [Bidirectional LSTM (BLSTM)]
Framewise Phoneme Classification with Bidirectional LSTM Networks
[2005 ICANN] [Bidirectional LSTM (BLSTM)]
Bidirectional LSTM Networks for Improved Phoneme Classification and Recognition
[2005 JNN] [Bidirectional LSTM (BLSTM)]
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
Language Model / Sequence Model
1997 … 2005 [Bidirectional LSTM (BLSTM)] … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT]
