Review — ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
From BERT to ALBERT

ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, ALBERT, by Google Research, and Toyota Technological Institute at Chicago
2020 ICLR, Over 2600 Citations (Sik-Ho Tsang @ Medium)
Language Model, Natural Language Processing, NLP, BERT
- Increasing model size become harder due to GPU/TPU memory limitations and longer training times.
- ALBERT, A Lite BERT, proposes two parameter reduction techniques to lower memory consumption and increase the training speed of BERT.
- A self-supervised loss is also used that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks with multi-sentence inputs.
Outline
- Factorized Embedding Parameterization
- Cross-Layer Parameter Sharing
- Inter-Sentence Coherence Loss
- ALBERT Model Variants
- Experimental Results
1. Factorized Embedding Parameterization
1.1. Basic Model Architecture
- The backbone of the ALBERT architecture is similar to BERT in that it uses a Transformer encoder with GELU nonlinearities.
- The BERT notation conventions are followed and the vocabulary embedding size denoted as E, the number of encoder layers is as L, and the hidden size is as H.
- Following BERT, the feed-forward/filter size is set to be 4H and the number of attention heads to be H=64.
1.2. Embedding Factorization
- The WordPiece embedding size E is tied with the hidden layer size H, i.e., E=H, which is sub-optimal. If E=H, then increasing H increases the size of the embedding matrix, which has size V×E.
From a modeling perspective, WordPiece embeddings are meant to learn context-independent representations, whereas hidden-layer embeddings are meant to learn context-dependent representations.
- A more efficient usage is to have H≫E.
- A factorization of the embedding parameters is proposed in ALBERT, decomposing them into two smaller matrices.
Instead of projecting the one-hot vectors directly into the hidden space of size H, ALBERT first projects them into a lower dimensional embedding space of size E, and then projects it to the hidden space.
- By using this decomposition, the embedding parameters are reduced from O(V×H) to O(V×E+E×H). This parameter reduction is significant when H≫E.
- (Similar factorization concept is also used in CNN such as the factorizing convolution in Inception-v3 and depthwise separable convolution in MobileNetV1.)
- (A little bit similar concept is also used in matrix decomposition for recommendation system.)
2. Cross-Layer Parameter Sharing


- In a Transformer layer, there is a attention network and feed-forward network (FFN).
- There are multiple ways to share parameters, e.g., only sharing FFN parameters across layers, or only sharing attention parameters.
The default decision for ALBERT is to share all parameters across layers.
3. Inter-Sentence Coherence Loss
- In addition to the masked language modeling (MLM) loss, BERT uses an additional loss called next-sentence prediction (NSP) where NSP is a binary classification loss for predicting whether two segments appear consecutively in the original text.
- However, subsequent studies found that NSP’s impact unreliable and decided to eliminate it. It is conjectured that the main reason behind NSP’s ineffectiveness is its lack of difficulty as a task, as compared to MLM.
- ALBERT maintains that inter-sentence modeling is an important aspect of language understanding, but a loss based primarily on coherence is proposed.
- That is, for ALBERT, a sentence-order prediction (SOP) loss is used, which avoids topic prediction and instead focuses on modeling inter-sentence coherence.
The SOP loss uses as positive examples the same technique as BERT (two consecutive segments from the same document), and as negative examples the same two consecutive segments but with their order swapped.
This forces the model to learn finer-grained distinctions about discourse-level coherence properties.
4. ALBERT Model Variants

- ALBERT models have much smaller parameter size compared to corresponding BERT models.
- For example, ALBERT-large has about 18× fewer parameters compared to BERT-large, 18M versus 334M.
- An ALBERT-xlarge configuration with H=2048 has only 60M parameters and an ALBERT-xxlarge configuration with H=4096 has 233M parameters, i.e., around 70% of BERT-large’s parameters.
- Note that for ALBERT-xxlarge, a 12-layer network is used because a 24-layer network (with the same configuration) obtains similar results but is computationally more expensive.
This improvement in parameter efficiency is the most important advantage of ALBERT’s design choices.
5. Experimental Results
5.1. Overall Comparison between BERT and ALBERT

With only around 70% of BERT-large’s parameters, ALBERT-xxlarge achieves significant improvements over BERT-large, as measured by the difference on development set scores for several representative downstream tasks: SQuAD v1.1 (+1.9%), SQuAD v2.0 (+3.1%), MNLI (+1.4%), SST-2 (+2.2%), and RACE (+8.4%).
5.2. Factorized Embedding Parameterization
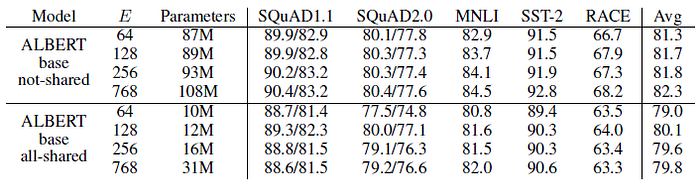
Under the all-shared condition (ALBERT-style), an embedding of size 128 appears to be the best.
- Based on these results, we use an embedding size E=128 in all future settings
5.3. Cross-Layer Parameter Sharing
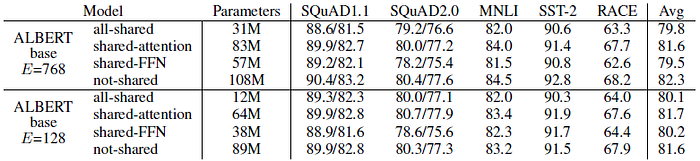
The all-shared strategy hurts performance under both conditions, but it is less severe for E=128 (-1.5 on Avg) compared to E=768 (-2.5 on Avg).
- All-shared strategy is chosen as the default choice.
5.4. Sentence Order Prediction (SOP)

- None (XLNet- and RoBERTa-style), NSP (BERT-style), and SOP (ALBERT-style), using an ALBERT-base configuration, are tried.
The SOP loss appears to consistently improve downstream task performance for multi-sentence encoding tasks (around +1% for SQuAD1.1, +2% for SQuAD2.0, +1.7% for RACE), for an Avg score improvement of around +1%.
5.5. Same Amount of Training Time

- The performance of a BERT-large model after 400k training steps (after 34h of training), roughly equivalent with the amount of time needed to train an ALBERT-xxlarge model with 125k training steps (32h of training).
After training for roughly the same amount of time, ALBERT-xxlarge is significantly better than BERT-large: +1.5% better on Avg, with the difference on RACE as high as +5.2%.
5.6. Additional Data & Dropout


Additional data that used in XLNet and RoBERTa giving a significant boost on MLM accuracy.
- The performance on the downstream tasks is also improved.
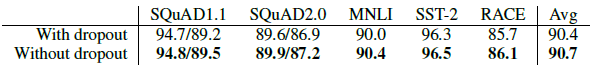
Removing Dropout significantly improves MLM accuracy.
- Removing Dropout also helps the downstream tasks.
5.7. Current SOTA on NLU Tasks
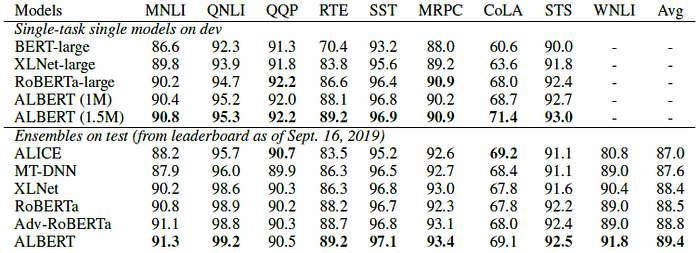
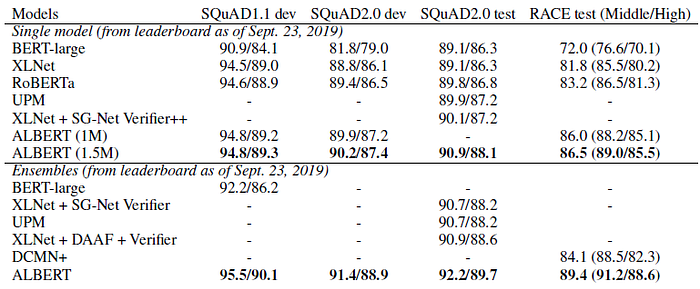
- The single-model ALBERT configuration incorporates the best-performing settings discussed: an ALBERT-xxlarge configuration using combined MLM and SOP losses, and no Dropout.
Both single-model and ensemble results indicate that ALBERT improves the state-of-the-art significantly for all three benchmarks, achieving a GLUE score of 89.4, a SQuAD 2.0 test F1 score of 92.2, and a RACE test accuracy of 89.4.
- The latter appears to be a particularly strong improvement, a jump of +17.4% absolute points over BERT, +7.6% over XLNet, +6.2% over RoBERTa, and 5.3% over DCMN+, an ensemble of multiple models specifically designed for reading comprehension tasks.
The single model achieves an accuracy of 86.5%, which is still 2.4% better than the state-of-the-art ensemble model.
References
[2020 ICLR] [ALBERT]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
[Google AI Blog]
https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [T64] [Transformer-XL] [BERT] [RoBERTa] [GPT-2] [DistilBERT] [MT-DNN] 2020 [ALBERT]
