Review — MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
MobileBERT, by Carnegie Mellon University, and Google Brain
2020 ACL, Over 300 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, BERT
- MobileBERT is proposed for compressing and accelerating the popular BERT model.
- MobileBERT is a thin version of BERTLARGE, while equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks.
- To train MobileBERT, an inverted-bottleneck incorporated BERTLARGE model is first trained as a specially designed teacher model. Then, knowledge is transferred from this teacher to MobileBERT.
Outline
- MobileBERT Architecture
- MobileBERT Training Loss & Strategy
- Experimental Results
1. MobileBERT Architecture


1.1. Bottleneck Student
- The architecture of MobileBERT is illustrated in Figure 1(c). It is as deep as BERTLARGE; but each building block is made much smaller.
- As shown in Table 1, the hidden dimension of each building block is only 128. On the other hand, two linear transformations are introduced for each building block to adjust its input and output dimensions to 512. This is analogue to the bottleneck structure in ResNet.
1.2. Inverted-Bottleneck Teacher
- To overcome the training issue, a teacher network is first constructed and it is trained until convergence, and knowledge transfer is then conducted from this teacher network to MobileBERT.
- As in Figure 1(b), the teacher network is just BERTLARGE while augmented with inverted-bottleneck structures (MobileNetV2) to adjust its feature map size to 512.
1.3. Stacked Feed-Forward Networks
- In original BERT, the ratio of the parameter numbers in Multi-Head Attention (MHA) and Feed-Forward Network (FFN) is always 1:2.
- But in the bottleneck structure, the inputs to the MHA are from wider feature maps (of inter-block size), while the inputs to the FFN are from narrower bottlenecks (of intra-block size). This results in that the MHA modules in MobileBERT relatively contain more parameters.
- To rebalance the MHA-FFN ratio, in Figure 1(c), each MobileBERT layer contains one MHA but several (F) stacked FFN. Specifically, F=4 stacked FFN are used after each MHA.
1.4. MobileBERTTINY

- A tiny version of MobileBERT is further designed.
- The reduced intra-block feature maps are used as key, query, and values in MHA for MobileBERTTINY. This can effectively reduce the parameters in MHA modules, but might harm the model capacity.
1.4. Operational Optimizations
- Layer Normalization and GELU activation accounted for a considerable proportion of total latency.
- 1.4.1. Remove Layer Normalization: The layer normalization of a n-channel hidden state h is replaced with an element-wise linear transformation:
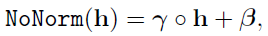
- where ○ is the Hadamard product (element-wise multiplication).
- 1.4.2. Use ReLU Activation: The GELU activation is replaced with simpler ReLU activation.
1.5. Embedding Factorization
- The embedding dimension is reduced to 128 in MobileBERT.
- Then, a 1D convolution is applied with kernel size 3 on the raw token embedding to produce a 512 dimensional output.
2. MobileBERT Training Loss & Strategy
2.1. Feature Map Transfer (FMT)
- The feature maps of each layer should be as close as possible to those of the teacher.
- In particular, the mean squared error between the feature maps of the MobileBERT student and the IB-BERT teacher is used as the knowledge transfer objective:
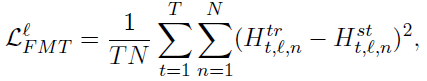
- where l is the index of layers, T is the sequence length, and N is the feature map size. In practice, decomposing this loss term into normalized feature map discrepancy and feature map statistics discrepancy can help stabilize training.
2.2. Attention Transfer (AT)
- The attention mechanism greatly boosts the performance of NLP.
- The KL-divergence between the per-head self-attention distributions of the MobileBERT student and the IB-BERT teacher is minimized:
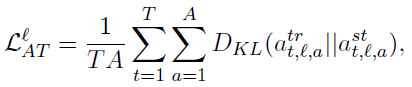
- where A is the number of attention heads.
2.3. Pre-training Distillation (PD)
- The knowledge distillation loss is a linear combination of the original masked language modeling (MLM) loss, next sentence prediction (NSP) loss, and the new MLM Knowledge Distillation (KD) loss:
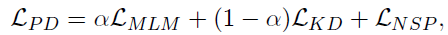
- where α is a hyperparameter in (0, 1).
- (LMLM and LNSP are the losses used in BERT. Please feel free to read BERT.)
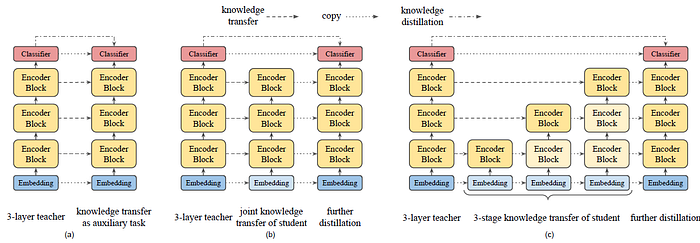
2.4. Auxiliary Knowledge Transfer (AKT)
- As in Figure 2(a), the intermediate knowledge transfer is regarded as an auxiliary task for knowledge distillation.
- A single loss is used, which is a linear combination of knowledge transfer losses from all layers as well as the pre-training distillation loss.
2.5. Joint Knowledge Transfer (JKT)
- However, the intermediate knowledge of the IB-BERT teacher (i.e. attention maps and feature maps) may not be an optimal solution for the MobileBERT student.
- Therefore, as in Figure 2(b), MobileBERT proposes that these two loss terms are separated, where MobileBERT is first trained with all layer-wise knowledge transfer losses jointly, and then it is further trained by pre-training distillation.
2.6. Progressive Knowledge Transfer (PKT)
- One may concern that the errors from the lower layers may affect the knowledge transfer in the higher layers.
- Therefore, as in Figure 2(c), MobileBERT proposes that each layer is progressively trained in the knowledge transfer. The progressive knowledge transfer is divided into L stages, where L is the number of layers.
- For PKT, while training the l-th layer, all the trainable parameters in the layers below are frozen. Or it can be soften by using smaller learning rate for layers below.
- For JKT and PKT, there is no knowledge transfer for the beginning embedding layer and the final classifier in the layer-wise knowledge transfer stage. They are copied from the IB-BERT teacher to the MobileBERT student.
3. Experimental Results
3.1. Architecture Search for IB-BERTLARGE

- The design philosophy for the teacher model is to use as small inter-block hidden size (feature map size) as possible, as long as there is no accuracy loss.
Reducing the inter-block hidden size doesn’t damage the performance of BERT until it is smaller than 512. 512 is chosen for inter-block hidden size.
- When the intra-block hidden size is reduced, the model performance is dramatically worse. Thus, it keeps unchanged.
3.2. Architecture Search for MobileBERT
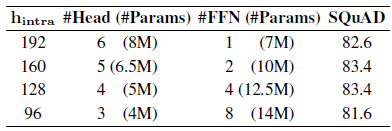
- MobileBERT models all with approximately 25M parameters but different ratios of the parameter numbers in MHA and FFN are tried to select a good MobileBERT student model.
- Model performance reaches the peak when the ratio of parameters in MHA and FFN is 0.4~0.6.
The architecture with 128 intra-block hidden size, 4 stacked FFNs, 4 heads are chosen as the MobileBERT student model in consideration of model accuracy and training efficiency.
3.3. SOTA Comparison on GLUE

- IB-BERTLARGE is trained on 256 TPU v3 chips for 500k steps with a batch size of 4096 and LAMB optimizer. The same training schedule is applied on MobileBERT during pre-training distillation stage. Additional 240k steps are used for PKT, JKT, or AKT.
From the table, we can see that MobileBERT is very competitive on the GLUE benchmark. MobileBERT achieves an overall GLUE score of 77.7, which is only 0.6 lower than BERTBASE, while being 4.3× smaller and 5.5× faster than BERTBASE.
Moreover, It outperforms the strong OpenAI GPT baseline by 0.8 GLUE score with 4.3× smaller model size.
3.4. SOTA Comparison on SQuAD
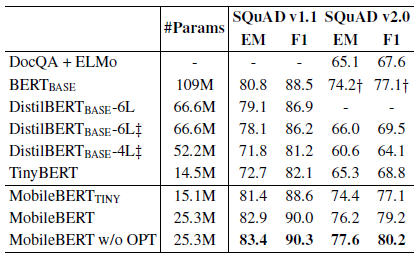
MobileBERT outperforms a large margin over all the other models with smaller or similar model sizes.
3.5. Quantization
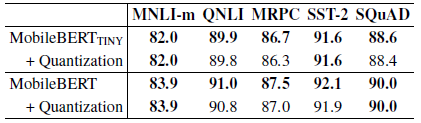
- The standard post-training quantization in TensorFlow Lite is applied to MobileBERT.
While quantization can further compress MobileBERT by 4, there is nearly no performance degradation from it. This indicates that there is still a big room in the compression of MobileBERT.
3.6. Ablation Studies
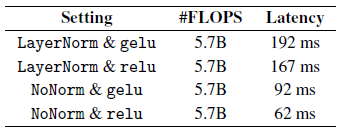
NoNorm and ReLU are very effective in reducing the latency of MobileBERT.
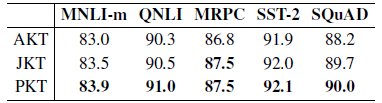
Progressive knowledge transfer (PKT) consistently outperforms the other two strategies.
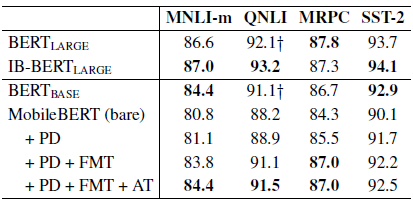
- Feature Map Transfer contributes most to the performance improvement of MobileBERT, while Attention Transfer and Pre-training Distillation also play positive roles.
IB-BERTLARGE teacher is as powerful as the original IB-BERTLARGE while MobileBERT degrades greatly when compared to its teacher. So it is believed that there is still a big room in the improvement of MobileBERT.
Reference
[2020 ACL] [MobileBERT]
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Language/Sequence Model
2007 … 2019 [T64] [Transformer-XL] [BERT] [RoBERTa] [GPT-2] [DistilBERT] [MT-DNN] [Sparse Transformer] [SuperGLUE] [FAIRSEQ] 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT]
