Review — CornerNet: Detecting Objects as Paired Keypoints (Object Detection)
Detecting Corners, Outperforms Mask R-CNN, Faster R-CNN, CoupleNet, G-RMI, FPN, TDM, YOLOv2, DSOD, GRF-DSOD, SSD, DSSD, RetinaNet, RefineDet
Published in
6 min readApr 6, 2021

In this story, CornerNet: Detecting Objects as Paired Keypoints, (CornerNet), by University of Michigan, is reviewed. In this paper:
- An object bounding box is detected as a pair of keypoints, the top-left corner and the bottom-right corner, eliminating the need for designing a set of anchor boxes commonly used in prior single-stage detectors.
This is a paper in 2018 ECCV with over 900 citations. (Sik-Ho Tsang @ Medium)
Outline
- CornerNet: Network Architecture
- Corner Detection (Heatmaps & Offsets)
- Corner Grouping (Embeddings)
- Corner Pooling
- Comparisons with State-Of-The-Art Detectors
1. CornerNet: Network Architecture

- The hourglass network used in Newell ECCV’16, which is originally used for human pose estimation, is used as backbone.
- Using Newell ECCV’16 as backbone probably because right now CornerNet is going to detect keypoints, similar to the purpose of networks for human pose estimation.

- Each keypoint is predicted as a heat map.
- Here, corners are treated as a keypoints.
- In Newell ECCV’16, head, shoulder, hand palm, etc are treated as keypoints.
- The hourglass network is followed by two prediction modules.
- One module is for the top-left corners, while the other one is for the bottom-right corners.
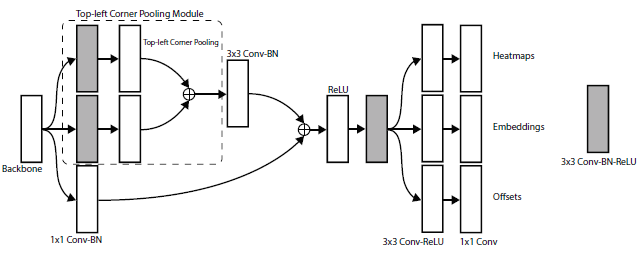
- Each module has its own corner pooling module, as shown above, to pool features from the hourglass network then predicting the heatmaps, embeddings and offsets.
- The depth of the hourglass network is 104.
- Unlike many other state-of-the -art detectors, only the features from the last layer of the whole network are used to make predictions.
- The full training loss is:

- where Ldet is the detection loss for heatmap, Lpull and Lpush are the losses for embedding, and Loff is the loss for offsets. These losses will be described in more details below.
- α and β set to 0.1 and γ sets to 1.
2. Corner Detection (Heatmap & Offsets)
- Each set of heatmaps has C channels, where C is the number of categories, and is of size H×W.
- Let pcij be the score at location (i, j) for class c in the predicted heatmaps, and let ycij be the “ground-truth” heatmap augmented with the unnormalized Gaussians, as similar to human pose estimation.
- With also the use of focal loss in RetinaNet, the detection loss Ldet is:

- where N is the number of objects in an image, α=2, and β=4.
- Remapping the locations from the heatmaps to the input image, some precision may be lost, which can greatly affect the IoU of small bounding boxes with their ground truths.
- Hence, Location offsets are predicted to slightly adjust the corner locations before remapping them to the input resolution.

- where ok is the offset, xk and yk are the x and y coordinate for corner k.
- Smooth L1 Loss, as in Fast R-CNN, at ground-truth corner locations, is used:
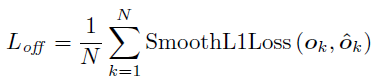
3. Corner Grouping (Embedding)

- Inspired by the associate embedding in Newell ECCV’16, CornerNet predicts an embedding vector for each detected corner such that if a top-left corner and a bottom-right corner belong to the same bounding box, the distance between their embeddings should be small.
- The actual values of the embeddings are unimportant. Only the distances between the embeddings are used to group the corners.
- Let etk be the embedding for the top-left corner of object k and ebk for the bottom-right corner.
- The “pull” loss is used to train the network to group the corners and the “push” loss is used to separate the corners:
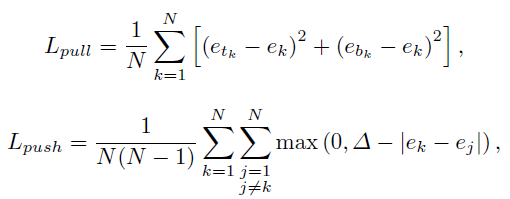
- where ek is the average of etk and ebk. Δ=1.
- Similar to the offset loss, the losses are only applied at the ground-truth corner location.

- Using the ground-truth heatmaps alone improves the AP from 38.5% to 74.0%.
- Replace the predicted offsets with the ground-truth offsets, the AP further increases by 13.1% to 87.1%.
- This suggests that although there is still ample room for improvement in both detecting and grouping corners, the main bottleneck is detecting corners.
3. Corner Pooling

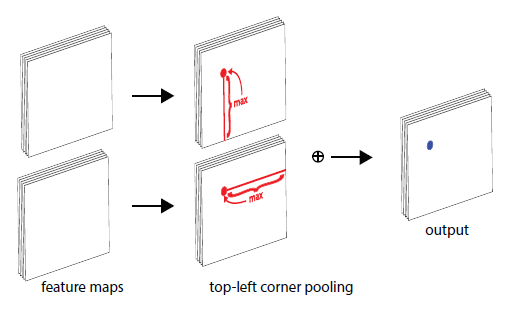
- As shown above, there is often no local visual evidence for the presence of corners.
- Corner pooling is proposed to better localize the corners by encoding explicit prior knowledge.
- It can be formulated as the below equation:
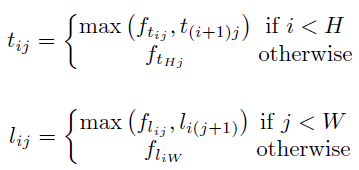
- An example is illustrated below:

- The top-left corner pooling layer can be implemented very efficiently.
- The feature map is scanned from right to left for the horizontal max-pooling and from bottom to top for the vertical max-pooling.
- Then two max-pooled feature maps are added.

- With corner pooling, there is significant improvement: 2.0% on AP, 2.1% on AP50 and 2.2% on AP75.
4. Comparisons with State-Of-The-Art Detectors

- With multi-scale evaluation, CornerNet achieves an AP of 42.1%, outperforms the state of the art among existing one-stage methods such as YOLOv2, DSOD, GRF-DSOD, SSD, DSSD, RefineDet.
- CornerNet also is competitive with two-stage methods such as Cascade R-CNN, and outperforms Mask R-CNN, Faster R-CNN, RetinaNet and CoupleNet.
Reference
[2018 ECCV] [CornerNet]
CornerNet: Detecting Objects as Paired Keypoints
Object Detection
2014: [OverFeat] [R-CNN]
2015: [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net]
2016: [OHEM] [CRAFT] [R-FCN] [ION] [MultiPathNet] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [SSD] [YOLOv1]
2017: [NoC] [G-RMI] [TDM] [DSSD] [YOLOv2 / YOLO9000] [FPN] [RetinaNet] [DCN / DCNv1] [Light-Head R-CNN] [DSOD] [CoupleNet]
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet] [RefineDet] [CornerNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD]

