Review — LXMERT: Learning Cross-Modality Encoder Representations from Transformers
LXMERT, A Vision Language Model for VQA, GQA, NLVR²
LXMERT: Learning Cross-Modality Encoder Representations from Transformers, LXMERT, by UNC Chapel Hill
2019 EMNLP, Over 1000 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, BERT, Transformer, Faster R-CNN
- LXMERT (Learning Cross-Modality Encoder Representations from Transformers, pronounced: ‘leksmert’) pretraining framework is proposed to learn the vision-and-language connections.
- After learning both intra-modality and cross-modality relationships, it is used for fine-tuning.
Outline
- LXMERT Model Architecture
- LXMERT Pretraining Losses
- LXMERT Pretraining Datasets & Details
- Experimental Results
1. LXMERT Model Architecture

- The above figure shows the overall framework. Below sub-sections will be described part by part. (It is assumed BERT and Transformer are known before reading this.)
1.1. Inputs
1.1.1. Word-Level Sentence Embeddings

- A sentence is split with words {w1, …, wn} with length n by WordPiece tokenizer used in BERT.
- The word wi and its index i (wi’s absolute position in the sentence) are projected to vectors by embedding sub-layers, and then added to the index-aware word embeddings:

1.1.2. Object-Level Image Embeddings

- Faster R-CNN is used to detect m objects {o1, …, om}. Then the features of detected objects are used as the embeddings of images. Each object oj is represented by its position feature (i.e., bounding box coordinates) pj and its 2048-dimensional region-of-interest (RoI) feature fj. A position-aware embedding vj is learnt by adding outputs of 2 fully-connected layers:

1.2. Single-Modality Encoders
- Each layer in a single-modality encoder contains a self-attention (‘Self’) sub-layer and a feed-forward (‘FF’) sub-layer.
- A residual connection and layer normalization (+) are added after each sub-layer.
1.2.1. Language Encoder

- There are NL layers in the language encoder.
1.2.2. Object-Relationship Encoder
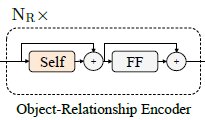
- There are NR layers in the language encoder.
1.3. Cross-Modality Encoder

- Each consists of two self-attention sub-layers, one bi-directional cross-attention sublayer, and two feed-forward sub-layers.
- There are NX layers.
- Inside the k-th layer, the bi-directional cross-attention sub-layer (‘Cross’) is first applied, which contains two unidirectional cross-attention sub-layers, one from language to vision and one from vision to language:
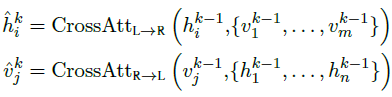
- where h and v are referred to language and vision features respectively as mentioned in Section 1.1.
The cross-attention sub-layer is used to exchange the information and align the entities between the two modalities.
- For further building internal connections, the self-attention sub-layers (‘Self’) are then further applied:
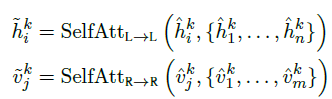
- Lastly, the k-th layer output {hki} and {vkj}are produced by feed-forward sub-layers (‘FF’) on top of {^hki} and {^vkj}.
- A residual connection and layer normalization (+) are added after each sub-layer.
1.4. Outputs
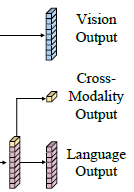
- LXMERT cross-modality model has three outputs for language, vision, and cross-modality, respectively. For the cross-modality output, following the practice in BERT, a special token [CLS] is appended before the sentence words.
2. LXMERT Pretraining Losses

2.1. Language Task: Masked Cross-Modality LM
- Words are randomly masked with p=0.15, which is similar to BERT.
Different from BERT, masked words are predicted from both the non-masked words in the language modality and the visual modality, to resolve ambiguity.
- As shown above, it is hard to determine the masked word ‘carrot’ from its language context but the word choice is clear if the visual information is considered.
2.2. Vision Task: Masked Object Prediction
- Objects are randomly mask with p=0.15, i.e. RoI features set to 0.
Two sub-tasks are performed: RoI-Feature Regression regresses the object RoI feature fj with L2 loss, and Detected-Label Classification learns the labels of masked objects with cross-entropy loss.
2.3. Cross-Modality Tasks
2.3.1. Cross-Modality Matching
- For each sentence, p=0.5, it is replaced with a mismatched sentence.
- Then, a classifier is trained to predict whether an image and a sentence match each other. This task is similar to ‘Next Sentence Prediction’ in BERT.
2.3.2. Image Question Answering (QA)
- In order to enlarge the pre-training dataset, around 1/3 sentences in the pre-training data are questions about the images.
- The model is asked to predict the answer to these image-related questions when the image and the question are matched.
3. LXMERT Pretraining Datasets & Details
3.1. Pretraining Data
- Pre-training data are aggregated from five vision-and-language datasets whose images come from MS COCO or Visual Genome. Besides the above two original captioning datasets, three large image question answering (image QA) datasets are aggregated: VQA v2.0, GQA balanced version, and VG-QA. Only train and dev data is used.
- Thus, there are in total 9.18M image-and-sentence pairs on 180K distinct images. The pre-training data contain around 100M words and 6.5M image objects.
3.2. Pretraining Details
- Faster R-CNN is pretrained on Visual Genome, and then frozen as feature extractor. Only m=36 objects are kept.
- The numbers of layers NL, NX, and NR are set to 9, 5, and 5 respectively.
- The hidden size is 768, and pretrained from scratch.
- LXMERT is pre-trained with multiple pre-training tasks and hence multiple losses are involved. Equal weights are used.
4. Experimental Results
4.1. SOTA Comparisons

- On NLVR², there are 2 images for 1 sentence. The task is to predict the label y given the images and the statement. Thus, x0 and x1 which are output from LXMERT, are concatenated, input to a weight layer, GELU, layer norm, then another weight layer and softmax:
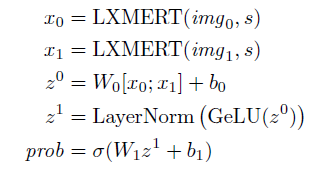
- On VQA, LXMERT improves the SotA overall accuracy (‘Accu’) by 2.1% and has 2.4% improvement on the ‘Binary’/‘Other’ question sub-categories.
- On VQA, there are 3.2% accuracy gain over the SotA.
- On NLVR², LXMERT significantly improves the accuracy (‘Accu’ of 76.2%) by 22%.
4.2. Comparison with BERT
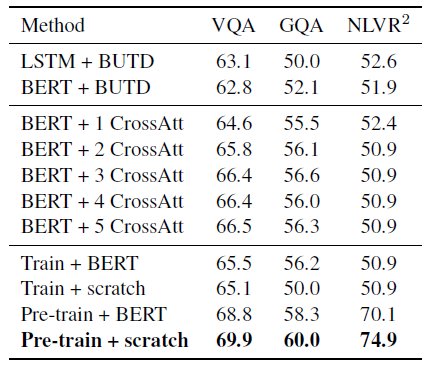
- Try loading BERT parameters into LXMERT, and use it in model training. It shows weaker results than the full model.
4.3. Ablation Study

- The 2.1% improvement on NLVR² shows the stronger representations learned with image-QA pre-training, since all data (images and statements) in NLVR² are not used in pre-training.
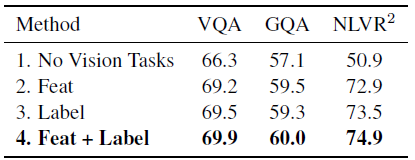
- The two visual pre-training tasks (i.e., RoI-feature regression and detected-label classification) could get reasonable results on their own, and jointly pre-training with these two tasks achieves the highest results.
[2019 EMNLP] [LXMERT]
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Visual/Vision/Video Language Model (VLM)
2019 [VideoBERT] [VisualBERT] [LXMERT] 2020 [ConVIRT]
