Review — DINO: Emerging Properties in Self-Supervised Vision Transformers
DINO, A Form of Self-Distillation with No Labels

Emerging Properties in Self-Supervised Vision Transformers
DINO, by Facebook AI Research, Inria, and Sorbonne University
2021 ICCV, Over 400 Citations (Sik-Ho Tsang @ Medium)
Self-Supervised Learning, Teacher Student, Image Classification, Vision Transformer, ViT
- Self-supervised method is applied onto Vision Transformer (ViT), which forms DINO, a form of self-Distillation with no labels.
- It is found that the self-supervised ViT features contain explicit information about the semantic segmentation of an image, as shown above. And the extracted features are also excellent k-NN classifiers.
Outline
- DINO (self-DIstillation with NO labels) Framework
- DINO Network Architecture & Centered EMA for Teacher Update
- Experimental Results
1. DINO (self-DIstillation with NO labels) Framework

1.1. DINO Framework
- DINO is inspired from BYOL.
- In DINO, the model passes two different random transformations of an input image to the student network gθs and teacher network gθt.
- Both student and teacher networks have the same architecture but different parameters.
- The output of the teacher network is centered with a mean computed over the batch.
- Each networks outputs a K dimensional feature denoted by Ps and Pt, i.e. output probability distributions, which are normalized with a temperature softmax τs over the feature dimension:

- With a fixed teacher, their similarity is then measured with a cross-entropy loss:

- where

1.2. Local-to-Global Correspondence
More precisely, from a given image, a set V of different views is generated. This set contains two global views, xg1 and xg2 and several local views of smaller resolution.
All crops are passed through the student while only the global views are passed through the teacher, therefore encouraging “local-to-global” correspondences.
- The loss is minimized:

- In practice, the standard setting for multi-crop by using 2 global views at resolution 224² covering a large (for example greater than 50%) area of the original image, and several local views of resolution 96² covering only small areas (for example less than 50%) of the original image.
2. DINO Network Architecture & Centered EMA for Teacher Update
2.1. DINO Architecture Details

The neural network g is composed of a backbone f (ViT or ResNet), and of a projection head h: g=h○f.
The features used in downstream tasks are the backbone f output.
- The projection head consists of a 3-layer multi-layer perceptron (MLP) with hidden dimension 2048 followed by l2 normalization and a weight normalized fully connected layer (Weight Norm) with K dimensions, which is similar to the design from SwAV [9].
- DINO does NOT use a predictor, resulting in the exact same architecture in both student and teacher networks.
ViT architectures do not use batch normalizations (BN) by default. Therefore, when applying DINO to ViT does not include any BN in the projection heads, making the system entirely BN-free.
- The ViT architecture takes as input a grid of non-overlapping contiguous image patches of resolution N×N. In this paper we typically use N=16 (“/16”) or N=8 (“/8”). The patches are then passed through a linear layer to form a set of embeddings. An extra learnable token is added to the sequence. The role of this token is to aggregate information from the entire sequence and the projection head h is attached at its output.
2.2. Exponential Moving Average (EMA) to Update Teacher for Avoiding Collapse
Model collapse is avoided with only a centering and sharpening of the momentum teacher outputs.
- Centering prevents one dimension to dominate but encourages collapse to the uniform distribution, while the sharpening has the opposite effect. Applying both operations balances their effects.
- A stop-gradient (sg) operator is applied on the teacher to propagate gradients only through the student. The teacher parameters are updated with an exponential moving average (ema) of the student parameters.
- The centering operation only depends on first-order batch statistics and can be interpreted as adding a bias term c to the teacher:
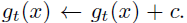
- The center c is updated with an exponential moving average (EMA), which allows the approach to work well across different batch sizes:
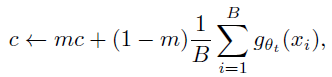
- where m>0 is a rate parameter and B is the batch size.
- Output sharpening is obtained by using a low value for the temperature τt in the teacher softmax normalization.
3. Experimental Results
3.1. SOTA Comparison on ImageNet

- k-NN is to use the nearest neighbor classifier. The feature of an image is matched to the k nearest stored features that votes for the label. 20-NN is consistently working the best for most of the runs.
- DINO performs on par with the state of the art on ResNet-50, validating that DINO works in the standard setting.
When it is switched to a ViT architecture, DINO outperforms BYOL, MoCo v2 and SwAV by +3.5% with linear classification and by +7.9% with k-NN evaluation.
- More surprisingly, the performance with a simple k-NN classifier is almost on par with a linear classifier (74.5% versus 77.0%). This property emerges only when using DINO with ViT architectures, and does not appear with other existing self-supervised methods nor with a ResNet-50.
A base ViT with 8×8 patches trained with DINO achieves 80.1% top-1 in linear classification and 77.4% with a k-NN classifier with 10× less parameters and 1.4× faster run time than previous state of the art SimCLRv2 [12].
3.2. Image Retrieval
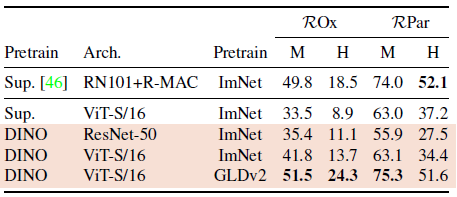
- DINO is trained on the 1.2M clean set from Google Landmarks v2 (GLDv2) [59], a dataset of landmarks designed for retrieval purposes.
- DINO ViT features trained on GLDv2 are remarkably good, outperforming previously published methods based on off-the-shelf descriptors.
3.3. Probing the Self-Attention Maps

- Different heads can attend to different semantic regions of an image, even when they are occluded (the bushes on the third row) or small (the flag on the second row).
3.4. Transfer Learning

For ViT architectures, self-supervised pretraining transfers better than features trained with supervision. Finally, self-supervised pretraining greatly improves results on ImageNet (+1–2%).
3.5. Ablation Study
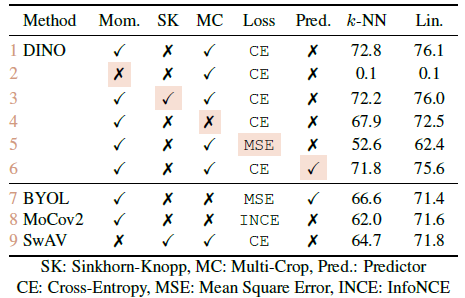
- First, in the absence of momentum, DINO does not work (row 2).
- More advanced operations, SK for example, are required to avoid collapse (row 9).
- However, with momentum, using SK has little impact (row 3).
- In addition, comparing rows 3 and 9 highlights the importance of the momentum encoder for performance.
- Second, in rows 4 and 5, multi-crop training and the cross-entropy loss in DINO are important components to obtain good features.
- It is also observed that adding a predictor to the student network has little impact (row 6) while it is critical in BYOL to prevent collapse.

- The performance greatly improves as the size of the patch is decreasing. It is interesting to see that performance can be greatly improved without adding additional parameters.
- However, the performance gain from using smaller patches comes at the expense of throughput: when using 5×5 patches, the throughput falls to 44 im/s, vs 180 im/s for 8×8 patches.
