[Review] SPG: Self-Produced Guidance (Weakly Supervised Object Localization)
Outperforms ACoL, Hide-and-Seek & CAM
Published in
6 min readDec 12, 2020

In this story, Self-produced Guidance for Weakly-supervised Object Localization, SPG, by University of Technology Sydney, and University of Illinois Urbana-Champaign, is shortly presented.
Weakly Supervised Object Localization (WSOL) is to have object localization while without object bounding box labels, but with only image-level label, for training. In this story:
- Self-produced Guidance (SPG) masks are proposed, which separate the foreground i.e., the object of interest, from the background to provide the classification networks with spatial correlation information of pixels.
- The SPG masks are progressively learned and auxiliary supervised for further improvement in producing high-quality object localization maps.
This is a paper in 2018 ECCV with over 70 citations. (Sik-Ho Tsang @ Medium)
Outline
- Self-Produced Guidance (SPG) Overview
- SPG Learning
1. Self-Produced Guidance (SPG) Overview

1.1. Stem
- Stem: is a fully convolutional network for feature extraction. It can be VGGNet or GoogLeNet, etc. The extracted feature maps FStem are then fed into the following component SPG-A.
1.2. SPG-A
- SPG-A is a network for image-level classification, which is consisted of four convolutional blocks (i.e.A1, A2, A3 and A4), a global average pooling (GAP) layer [19] and a softmax layer.
- This part is similar to CAM.
1.3. SPG-B
- SPG-B is leveraged to learn Self-produced guidance masks by using the seeds of foreground and background generated from attention maps.
- Particularly, the output features maps FA1 and FA2 of A1 and A2 are fed into the two blocks in SPG-B, respectively.
- Each block of SPG-B contains three convolutional layers followed by a sigmoid layer. The output of SPG-B are denoted as FB1 and FB2 for the two branches, respectively.
1.4. SPG-C
- SPG-C contains two convolutional layers with 3×3 and 1×1 kernels, followed by a sigmoid layer.
- The component SPG-C uses the auxiliary SPG supervision to encourage the SPG-A to learn pixel-level correlations.
2. SPG Learning

2.1. Learning
- For any image, its attention map O is extracted from A4 by simply from a classification network. This attention map usually highlights the most discriminative regions of object. (That is the one used in CAM.)
- The initial object and background seeds can be easily obtained according to the scores in the attention maps, i.e. the binarized SPG mask:
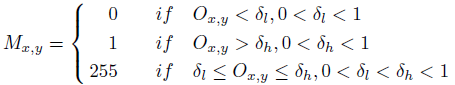
- M = 0: The regions with very low scores are considered as background.
- M = 1: The regions with very high scores are considered as foreground.
- M = 255: The rest regions are ignored during the learning process.
- B2 is supervised by the seed map and it can learn the patterns of foreground and background.
- The same strategy is used to find the foreground and background seeds in the output map of B2, which are used to train the B1 branch.
- B2 is applied to learn better self-produced maps supervised by the seed map. The ignored pixels do not contribute to the loss and their gradients do not back-propagated.
- The output of B2 is then further applied as attention maps, and better self-produced supervision masks can be calculated using the above equation.
- The second and third layers share parameters between B1 and B2.
- After obtaining output maps of B1 and B2, these two maps are fused to generated the final self-produced supervision map. Particularly, the average of the two maps is used to generate the self-produced guidance Mfuse.
2.2. Network Variants
- SPG uses Inception-v3 as backbone/stem.
- SPG-plain: Adding two convolutional layers of kernel size 3×3, stride 1, pad 1 with 1024 filters and a convolutional layer of size 1×1, stride 1 with 1000 units (200 for CUB-200–2011). Finally, a GAP layer and a softmax layer are added on the top.
- SPG-B and SPG-C: Plain network is updated by adding these two components.
3. Experimental Results

- SPG-plain model achieves 53.71% and 41.81% of Top-1 and Top-5 localization error, mainly attribute to the structure of the Inception-v3 network.
- The SPG strategy further reduces the localization error to Top-1 51.40% and Top-5 40.00%, outperforms GAP (CAM), Hide-and-Seek (HaS), and ACoL.
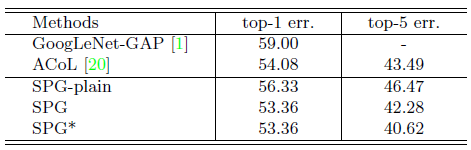
- The SPG approach achieves the localization error of Top-1 53.36%.
- For SPG*, two bounding boxes are selected from the top 1st and 2nd predicted classes, and one is selected from the 3rd class. By this way, the Top-5 localization error on ILSVRC is improved to 35.05%, and that on CUB-200–2011 is improved to 40.62%.
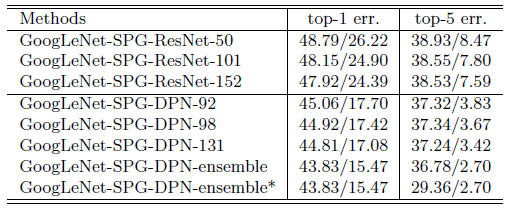
- Further improvement of the localization performance is achieved by combining our localization results with the state-of-the-art classification results, i.e., ResNet and DPN.
3.2. Visualization

- The above figure shows the attention maps as well as the predicted bounding boxes.
- SPG can highlight nearly the entire object regions and produce precise bounding boxes.
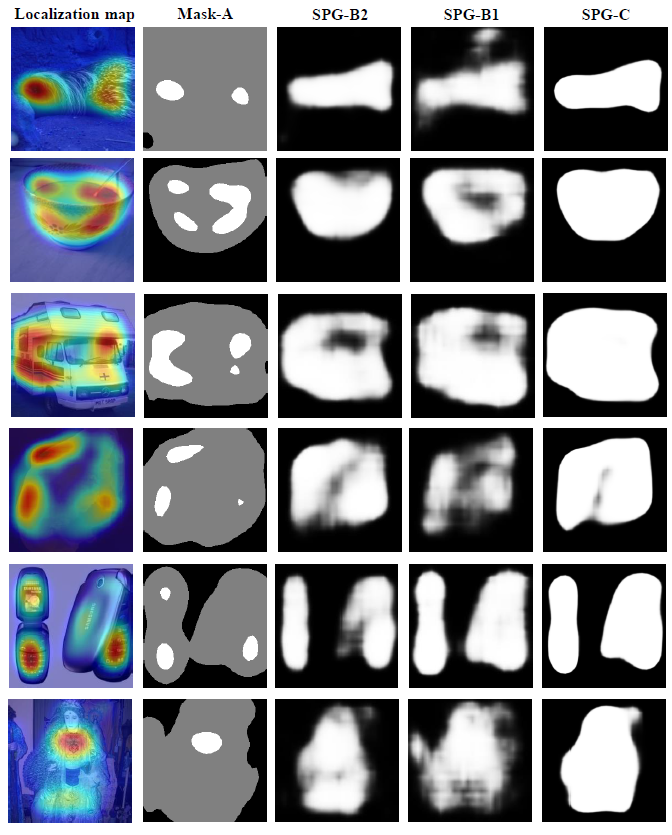
- The above figure visualizes the output of the multiple branches in generating the self-produced guidances.
- It can be observed the seeds usually cover small region of the object and background pixels.
- The produced seed masks (Mask-A) are then utilized as supervision for the B2 branch.
- B2 can learn more confident patterns of foreground and background pixels, and precisely predict the remaining foreground/background regions where leave undefined in Mask-A.
- B1 leverages the lower level feature maps and the supervision from B2 to learn more detailed regions.
- Finally, the self-produced guidance is obtained by fusing the two outputs of B1 and B2.
3.3. Ablation Study
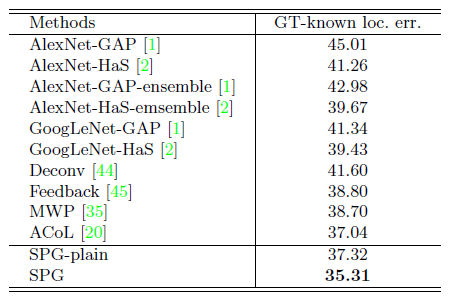
- The Top-1 error of SPG-plain is 37.32%.
- With the assistance of the auxiliary supervision, the localization error with ground-truth labels reduces to 35.31%.
- Without the initial seed masks, only a higher Top-1 error rate of 35.58% is obtained.
- By removing the shared setting, the localization error rate increases from 35.31% to 36.31%.
- After removing SPG-C, the performance becomes worse with the Top-1 error rate of 36.06%. But the localization performance with only using SPG-B is still better than the plain version. So, the branches in SPG-B can also contribute to the improvement of localization accuracy.
Reference
[2018 ECCV] [SPG]
Self-produced Guidance for Weakly-supervised Object Localization
Weakly Supervised Object Localization (WSOL)
2014 [Backprop] 2016 [CAM] 2017 [Hide-and-Seek] 2018 [ACoL] [SPG]

