Brief Review — ATSS: Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
ATSS, Improves the Positive Sample Selection Process
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
ATSS, by CBSR, NLPR, CASIA; SAI, UCAS; AIR, CAS; BUPT; Westlake University
2020 CVPR, Over 1100 Citations (Sik-Ho Tsang @ Medium)Object Detection
2014 … 2022 [Pix2Seq] [MViTv2] [SF-YOLOv5] [GLIP] [TPH-YOLOv5++] 2023 [YOLOv7]
==== My Other Paper Readings Are Also Over Here ====
- Authors point out that the essential difference between anchor-based detection, RetinaNet, and anchor-free detection, FCOS, is actually how to define positive and negative training samples.
- The, an Adaptive Training Sample Selection (ATSS) is proposed to automatically select positive and negative samples according to statistical characteristics of object.
Outline
- Closing the GAP Between Anchor-based and Anchor-free Detection
- Adaptive Training Sample Selection (ATSS)
- Results
1. Closing the GAP Between Anchor-based and Anchor-free Detection

- FCOS outperforms RetinaNet. However, there many advanced FCOS components in FCOS which makes the comparison between anchor-based and anchor-free approaches unfair.
- These advanced FCOS components: Group Norm in heads, using the GIoU regression loss function, limiting positive samples in the ground-truth box, introducing the center-ness branch, and adding a trainable scalar for each level feature pyramid, are added to RetinaNet.
These differences improve the anchor-based RetinaNet to 37.0%, which still has a gap of 0.8% to the anchor-free FCOS.
2. Adaptive Training Sample Selection (ATSS)
2.1. Positive and Negative Samples Defintion in RetinaNet and FCOS

- RetinaNet utilizes IoU to divide the anchor boxes from different pyramid levels into positives and negatives.
- FCOS uses spatial and scale constraints to divide the anchor points from different pyramid levels.

- RetinaNet regresses from the anchor box with four offsets between the anchor box and the object box.
- FCOS regresses from the anchor point with four distances to the bound of object.

- There is no obvious difference in final performance, no matter regressing starting from a point or a box.
The essential difference is actually how to define positive and negative training samples.
2.2. Proposed ATSS

- For each ground-truth box g on the image, we first find out its candidate positive samples.
- Line 3 to 6: On each pyramid level, we select k anchor boxes whose center are closest to the center of g based on L2 distance. Supposing there are L feature pyramid levels, the ground-truth box g will have k×L candidate positive samples. k=9 is the best choise.
- Line 7: After that, the IoU between these candidates and the ground-truth g is computed as Dg.
- Lines 8–9: The mean and standard deviation of Dg are computed as mg and vg.
- Line 10: With these statistics, the IoU threshold for this ground-truth g is obtained as tg=mg+vg.
- Lines 11–15: Finally, these candidates are selected, whose IoU are greater than or equal to the threshold tg as final positive samples.
- Line 12: Notably, the positive samples’ center is limited to the ground-truth box.
- Line 17: Besides, if an anchor box is assigned to multiple ground-truth boxes, the one with the highest IoU will be selected. The rest are negative samples.
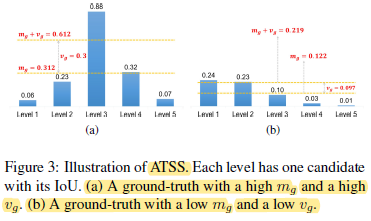
Figure 3(a) indicates it has high-quality candidates and the IoU threshold is supposed to be high.
A low mg as shown in Figure 3(b) indicates that most of its candidates are low-quality and the IoU threshold should be low.
3. Results

The adaptive way in ATSS (FCOS+ATSS) is better than the fixed way in FCOS to select positives from candidates along the scale dimension.

ATSS with ResNet-101 achieves 43.6% AP without any bells and whistles, which is better than all the methods with the same backbone.
- The AP accuracy of the proposed method is further improved to 45.1% and 45.6% by using larger backbone networks ResNeXt-32x8d-101 and ResNeXt-64x4d-101.
- DCN consistently improves the AP performances.
- The best result 47.7% is achieved with single-model and single-scale testing, outperforming all the previous detectors by a large margin.
Finally, with the multi-scale testing strategy, the best model achieves 50.7% AP.
