GLIP: Grounded Language-Image Pre-training
GLIP, Uses Phrase Grounding As Pretraining Task for Object Detection

Grounded Language-Image Pre-training,
GLIP, by UCLA, Microsoft Research, University of Washington, University of Wisconsin-Madison, Microsoft Cloud and AI, and International Digital Economy Academy,
2022 CVPR, Over 200 Citations (Sik-Ho Tsang @ Medium)Vision Language Model (VLM) / Foundation Model
2017 … 2021 [CLIP] [VinVL] [ALIGN] [VirTex] [ALBEF] [Conceptual 12M (CC12M)] 2022 [FILIP] [Wukong] [LiT] [Flamingo] [FLAVA] [SimVLM] [VLMo] [BEiT-3] 2023 [GPT-4]
Object Detection
2014 … 2020 [EfficientDet] [CSPNet] [YOLOv4] [SpineNet] [DETR] [Mish] [PP-YOLO] [Open Images] [YOLOv5] 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] [HRNetV2, HRNetV2p] [MDETR] 2022 [PVTv2] [Pix2Seq] [MViTv2] [SF-YOLOv5] 2023 [YOLOv7]
==== My Other Paper Readings Are Also Over Here ====
- A grounded language-image pretraining (GLIP) model is proposed, which unifies object detection and phrase grounding for pre-training. The unification brings two benefits:
- It allows GLIP to learn from both detection and grounding data to improve both tasks and bootstrap a good grounding model.
- GLIP can leverage massive image-text pairs by generating grounding boxes in a self-training fashion, making the learned representations semantic-rich.
Outline
- GLIP
- Results
- Prompt Tuning & Its Results
1. GLIP
1.1. Conventional Object Detection
- A standard object detection loss is the sum of classification loss and localization loss, as below:

- With the image img as input, O are the obtained object/region/box features. W is the weight matrix of the box classifier C, Scls are the output classification logits, and T is the target matching between regions and classes:

1.2. Object Detection as Phrase Grounding
Phrase grounding is a task of identifying the fine-grained correspondence between phrases in a sentence and objects (or regions) in an image.
- One simple way is to have a prompt in which each class name is a candidate phrase to be grounded.

- In a grounding model, the alignment scores Sground are computed between image regions and words in the prompt:

- where P is the contextual word/token features from the language encoder and plays a similar role to the weight matrix W as in conventional object detection task.
- The classification logits Scls is replaced with the region-word alignment scores Sground.
1.3. Language-Aware Deep Fusion

Deep fusion between the image and language encoders is introduced, which fuses the image and text information in the last few encoding layers.
- DyHead [10] is used as the image encoder. BERT is used as the text encoder, the deep-fused encoder is:
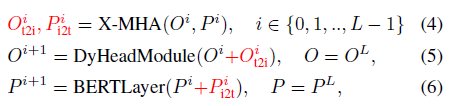
- where L is the number of DyHeadModules in DyHead [10], BERTLayer is newly-added BERT Layers on top of the pretrained BERT, O0 denote the visual features from the vision backbone, and P0 denote the token features from the language backbone (BERT).
- The cross-modality communication is achieved by the cross-modality multi-head attention module (X-MHA) (4), followed by the single modality fusion and updated in (5) & (6), as above.
- In the cross-modality multi-head attention module (X-MHA) (4), each head computes the context vectors of one modality by attending to the other modality:
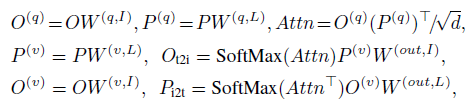
The deep-fused encoder (4)-(6) brings two benefits: 1) It improves the phrase grounding performance. 2) It makes the learned visual features language-aware.
1.4. Model Variants
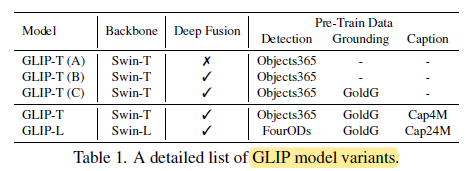
- Based on different backbone and pretraining data used, different variants are generated as above.
- Teacher student paradigm is also used.
- A teacher GLIP with gold (human-annotated) detection and grounding data is firstly trained.
- Then, a student GLIP is trained with both the gold data and the generated pseudo grounding data by teacher.
2. Results
2.1. COCO

Overall, GLIP models achieve strong zero-shot and supervised performance. Zero-shot GLIP models rival or surpass well-established supervised models.
- e.g.: With the Swin-Large backbone, GLIP-L surpasses the current SoTA on COCO.
2.2. LVIS

GLIP exhibits strong zero-shot performance on all the categories. GLIP-T is on par with supervised MDETR while GLIP-L outperforms Supervised-RFS by a large margin.
2.3. Flickr30K
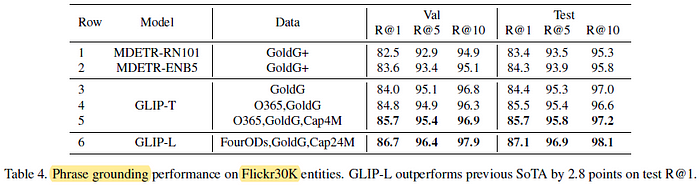
- GLIP-T with GoldG (Row 3) achieves similar performance to MDETR with GoldG+, presumably due to the introduction of Swin Transformer, DyHead module, and deep fusion.
- More interestingly, the addition of detection data helps grounding (Row 4 v.s. 3), showing again the synergy between the two tasks and the effectiveness of the unified loss.
- Image-text data also helps (Row 5 v.s. 4).
Lastly, scaling up (GLIP-L) can achieve 87.1 Recall@1, outperforming the previous SoTA by 2.8 points.
2.4. Data Efficiency
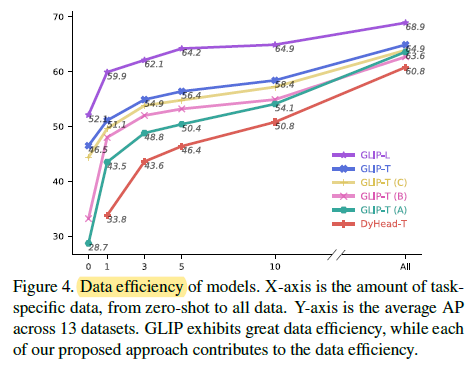
Unified grounding reformulation, deep fusion, grounding data, and model scale-up all contribute to the improved data efficiency (from the bottom red line (Dyhead-T) up to the upper purple line (GLIP-L)).
3. Prompt Tuning & Its Results
3.1. Prompt Tuning

- For example, on the left hand side of Figure 6, the model fails to localize all occurrences of the novel entity “stingray”.
- However, by adding the attributes to the prompt, i.e., “flat and round”, the model successfully localizes all occurrences of stringrays.
With this simple prompt change, we improve the AP50 on stingray from 4.6 to 9.7.
3.2. Results
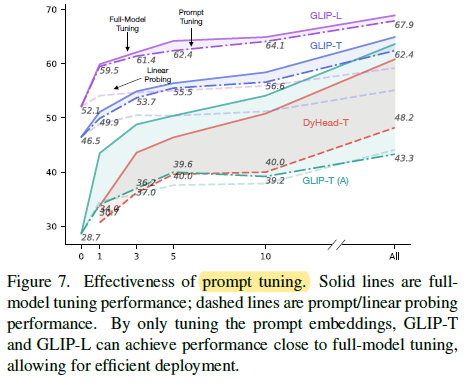
As the model and data size grow larger, the gap between full-model tuning and prompt tuning becomes smaller (GLIP-L v.s. GLIP-T), echoing the findings in NLP literature.
