Review — FCOS: Fully Convolutional One-Stage Object Detection
FCOS: Training Without the Use of Anchor Boxes

In this paper, FCOS: Fully Convolutional One-Stage Object Detection, by The University of Adelaide, is reviewed. In this paper:
FCOS is designed in which it is anchor box free, as well as proposal free.
- FCOS completely avoids the complicated computation related to anchor boxes such as calculating overlapping during training.
- It also avoids all hyper-parameters related to anchor boxes.
- FCOS encourages to rethink the need of anchor boxes.
This is a paper in 2019 ICCV with over 1000 citations. (Sik-Ho Tsang @ Medium)
Outline
- FCOS: Network Architecture
- Multi-level Prediction with FPN for FCOS
- Ablation Study
- SOTA Comparison
1. FCOS: Network Architecture

1.1. Notations, Inputs, Outputs
- Let Fi (Size of H×W×C) be the feature maps at layer i of a backbone CNN and s be the total stride until the layer.
- The ground-truth bounding boxes for an input image are defined as {Bi}, where Bi=(x(i)0, y(i)0, x(i)1, y(i)1, c(i)) where {x(i)0, y(i)0}, {x(i)1, y(i)1} are the the coordinates of the left-top and right-bottom corners of the bounding box respectively. c(i) is the object class.
- C is the total number of classes. e.g.: C=80 in MS COCO.
- Specifically, location (x, y) is considered as a positive sample if it falls into any ground-truth box and the class label c* of the location is the class label of the ground-truth box. Otherwise it is a negative sample and c*=0 (background class).
- A 4D real vector t*=(l*, t*, r*, b*) being the regression targets for the location, as shown in the first figure at the top of the story. Here l*, t*, r*, b* are the distances from the location to the four sides of the bounding box.
- Formally, if location (x, y) is associated to a bounding box Bi, the training regression targets for the location can be formulated as (Eq. (1)):

- The final layer of our networks predicts an 80D vector p of classification labels and a 4D vector t = (l, t, r, b) bounding box coordinates.
- C binary classifiers are trained.
- 4 convolutional layers are added after the feature maps of the backbone networks respectively for classification and regression branches.
- Since the regression targets are always positive, exp(x) is employed to map any real number to (0,∞) on the top of the regression branch.
It is worth noting that FCOS has 9× fewer network output variables than the popular anchor-based detectors [15, 24] (RetinaNet [15]) with 9 anchor boxes per location.
1.2. Loss Function
- The loss function is (Eq. (2)):
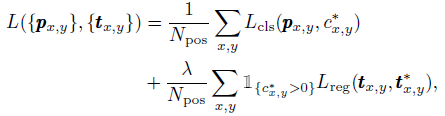
- where Lcls is focal loss in RetinaNet. Lreg is the IoU loss. Npos denotes the number of positive samples and λ being 1 in this paper is the balance weight for Lreg.
- The summation is calculated over all locations on the feature maps Fi. 1{c*i>0} is the indicator function, being 1 if c*i> 0 and 0 otherwise.
1.3. Inference
- Given an input images, the image goes through the network and obtain the classification scores px,y and the regression prediction tx,y for each location on the feature maps Fi.
- Following RetinaNet, we choose the location with px,y > 0.05 as positive samples and invert Eq. (1) to obtain the predicted bounding boxes.
2. Multi-level Prediction with FPN for FCOS
2.1. Multi-level Prediction with FPN
- If a location falls into multiple bounding boxes, it is considered as an ambiguous sample. We simply choose the bounding box with minimal area as its regression target.
Multi-level Prediction with FPN can reduce the number of ambiguous samples significantly.
- Unlike anchor-based detectors, which assign anchor boxes with different sizes to different feature levels, the range of bounding box regression is directly limited for each level.
- The range mi is the maximum distance that feature level i needs to regress. In this work, m2, m3, m4, m5, m6 and m7 are set as 0, 64, 128, 256, 512 and ∞, respectively.
- More specifically, we firstly compute the regression targets l*, t*, r*, b* for each location on all feature levels. Next, if a location satisfies max(l*, t*, r*, b*) > mi or max(l*, t*, r*, b*) < mi−1, it is set as a negative sample and is thus not required to regress a bounding box anymore.
- If a location, even with multi-level prediction used, is still assigned to more than one ground-truth boxes, the ground-truth box with minimal area is simply chosen as its target.
- The heads are shared between different feature levels, not only making the detector parameter-efficient but also improving the detection performance.
- As different feature maps target for different object sizes, exp(si × x) with a trainable scalar si to automatically adjust the base of the exponential function for feature level Pi, instead of exp(x), improve a bit of accuracy performance.
2.2. Center-ness for FCOS

- After using multi-level prediction in FCOS, there is still a performance gap between FCOS and anchor-based detectors. It is due to a lot of low-quality predicted bounding boxes produced by locations far away from the center of an object.
- Center-ness is used to solve this problem (Eq. (3)):
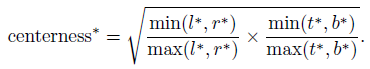
- The center-ness depicts the normalized distance from the location to the center of the object that the location is responsible for.
- The center-ness ranges from 0 to 1 and is thus trained with binary cross entropy (BCE) loss. The loss is added to the loss function Eq. (2).
- When testing, the final score (used for ranking the detected bounding boxes) is computed by multiplying the predicted center-ness with the corresponding classification score. Thus the center-ness can down-weight the scores of bounding boxes far from the center of an object.
3. Ablation Study
3.1. Multi-level Prediction with FPN
- COCO trainval35k split (115K images) is used for training and minival split (5K images) is used for validation.
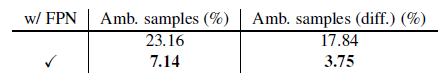
With Multi-level Prediction with FPN, the number of ambiguous sample is largely reduced.
3.2. Center-ness

- The center-ness+ can also be computed with the predicted regression vector without introducing the extra center-ness branch. But it cannot improve AP.
The center-ness branch can boost AP from 33.5 to 37.1%.
3.3. Other Improvements
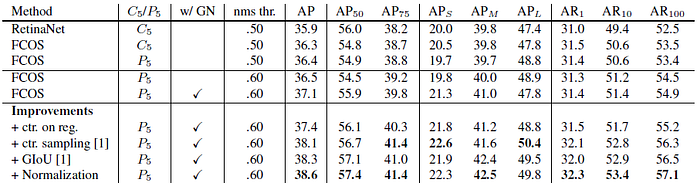
- “ctr. on reg.”: moving the center-ness branch to the regression branch.
- “ctr. sampling”: only sampling the central portion of ground-truth boxes as positive samples.
- “GIoU”: penalizing the union area over the circumscribed rectangle’s area in IoU Loss.
- “Normalization”: normalizing the regression targets in Eq. (1) with the strides of FPN levels
The performance of our anchor-free detector can be improved by a large margin by adding other improvements.
Based on this, authors encourage the community to rethink the necessity of anchor boxes in object detection.
- These improvements are not used in SOTA comparison below. It is found out after the initial submission of the paper.
4. SOTA Comparison
4.1. MS COCO Test-Dev Split

- FCOS with other state-of-the-art object detectors on test-dev split of MS-COCO benchmark.
- With ResNet-101-FPN, FCOS outperforms the RetinaNet with the same backbone ResNet-101-FPN by 2.4% AP.
This is the first time that an anchor-free detector, without any bells and whistles outperforms anchor-based detectors by a large margin.
- FCOS also outperforms other classical two-stage anchor-based detectors such as Faster R-CNN by a large margin.
- With ResNeXt-64x4d-101-FPN as the backbone, FCOS achieves 43.2% in AP. It outperforms the recent state-of-the-art anchor-free detector CornerNet by a large margin while being much simpler.
FCOS is more likely to serve as a strong and simple alternative to current mainstream anchor-based detectors.
- Moreover, FCOS with the improvements in Section 3 achieves 44.7% AP with single-model and single scale testing, which surpasses previous detectors by a large margin.
4.2. Extensions on Region Proposal Networks
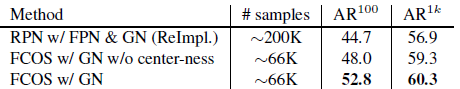
FCOS can be also able to replace the anchor boxes in Region Proposal Networks (RPNs) with FPN.
- Even without the proposed center-ness branch, FCOS already improves both AR100 and AR1k significantly.
- With the proposed center-ness branch, FCOS further boosts AR100 and AR1k respectively to 52.8% and 60.3%, which are 18% relative improvement for AR100 and 3.4% absolute improvement for AR1k over the RPNs with FPN.
Reference
[2019 ICCV] [FCOS]
FCOS: Fully Convolutional One-Stage Object Detection
Object Detection
2014–2017: …
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet] [RefineDet] [CornerNet] [Pelee & PeleeNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD] [CenterNet] [Grid R-CNN] [NAS-FPN] [ASFF] [Bag of Freebies] [VoVNet/OSANet] [FCOS]
2020: [EfficientDet] [CSPNet] [YOLOv4] [SpineNet]
2021: [Scaled-YOLOv4]
