Brief Review — TPH-YOLOv5++: Boosting Object Detection on Drone-Captured Scenarios with Cross-Layer Asymmetric Transformer
TPH-YOLOv5++, Improves TPH-YOLOv5

TPH-YOLOv5++: Boosting Object Detection on Drone-Captured Scenarios with Cross-Layer Asymmetric Transformer,
TPH-YOLOv5++, by Beihang University,
2022 MDPI J. Remote Sensing (Sik-Ho Tsang @ Medium)Object Detection
2014 … 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] [HRNetV2, HRNetV2p] [MDETR] [TPH-YOLOv5] 2022 [PVTv2] [Pix2Seq] [MViTv2] [SF-YOLOv5] [GLIP] 2023 [YOLOv7]
==== My Other Paper Readings Are Also Over Here ====
- TPH-YOLOv5++ is proposed to significantly reduce the computational cost and improve the detection speed of TPH-YOLOv5.
- In TPH-YOLOv5++, cross-layer asymmetric Transformer (CA-Trans) is designed to replace the additional prediction head while maintain the knowledge of this head.
- By using a sparse local attention (SLA) module, the asymmetric information between the additional head and other heads can be captured efficiently, enriching the features of other heads.
Outline
- Problems of TPH-YOLOv5
- TPH-YOLOv5++
- Results
1. Problems of TPH-YOLOv5
1.1. TPH-YOLOv5

- TPH-YOLOv5 introduces an additional head, Transformer prediction head (TPH), and convolutional block attention module (CBAM).
- Four prediction heads are named tiny, small, medium, and large heads.
1.2. Problems at Tiny Head

At top left of the figure, the confidences of all boxes at tiny head are shown. It produces plenty of wrong boxes with relatively large confidence, especially between 0.2 and 0.6.

- The average confidence value of each pixel is estimated. If the average confidence is high, the color tends towards red, otherwise it tends towards blue.
- It is found that the small prediction head also captures objects of considerable proportions that are contained by the results predicted by the additional tiny head.
2. TPH-YOLOv5++
2.1. Pipeline

- Instead of small path and tiny path for predicting objects individually, these two paths are fused together via proposed CA-Trans:
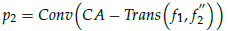
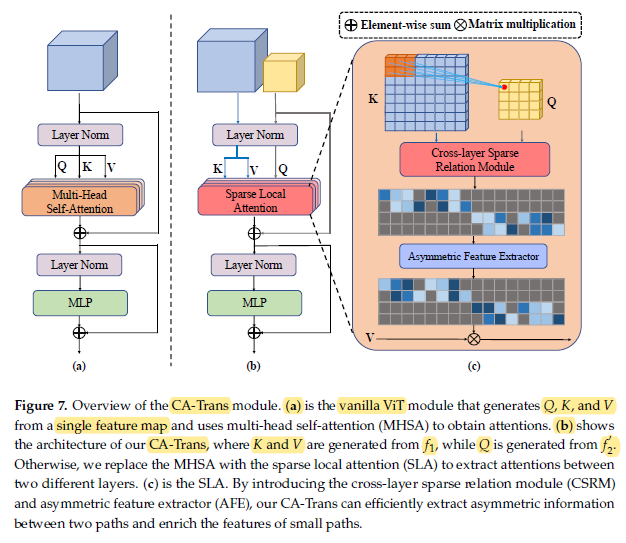
- where CA-Trans, taking f1 and f’2 as inputs and getting f’’2 . CA — Trans( , ) denotes the cross-layer asymmetric Transformer module.
2.2. CA-Trans

CA-Trans takes f1 and f’2 as inputs and generates f’’2.
Then, K and Q are generated from f1:
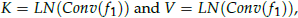
- where LN is Layer Norm.
Similar to K and V, Q is generated from f’2:
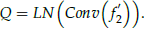
2.3. Sparse Local Attention (SLA)
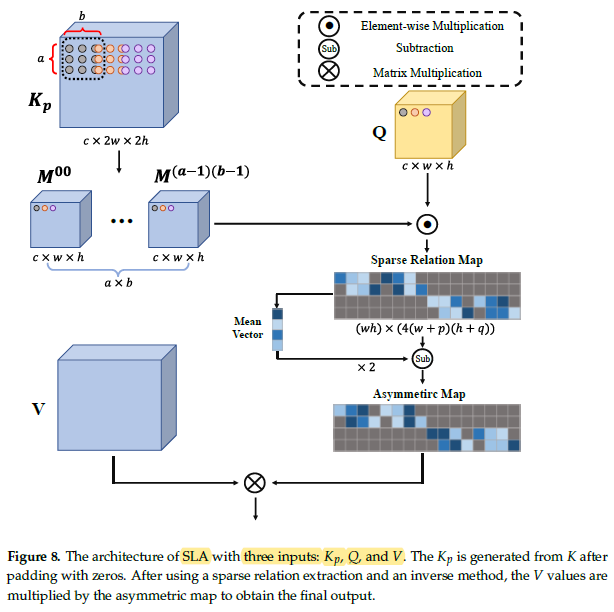
- After obtaining Q, K, and V, we use the sparse local attention (SLA) module to calculate sparse attentions between features of two different layers.
- First, neighborhood area of Kp for each pixel in Q is obtained. Therefore, a neighborhood set for Q is obtained:
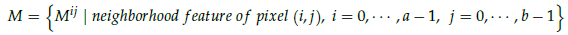
- where M is the set of neighborhood features of all pixels in Q, and Mij contains the (i, j) neighborhood feature of each pixel in Q.
- The transformation of each pixel from Kp to Mij:
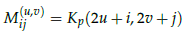
- where u and v are the coordinates of pixel in Mij.
- All the neighborhood features are concatenated as Ksparse:
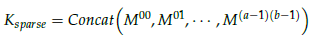
- The sparse relation map R is then calculated:
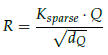
- where dQ is the channel dimension of Q.
- Then asymmetric feature extractor (AFE) is used to obtain the asymmetric map:
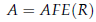
- where the value at each location of A is:
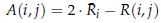
- where Ri denotes the average of the i-th row of R.
- The asymmetric map is applied to V to extract the features:
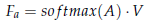
- where Fa denotes the asymmetric feature output from the SLA and softmax(.) is the softmax operation along each row of A.
- Finally, the output Fout of CA-Trans can be formulated as:
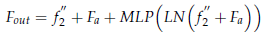
3. Results
3.1. SOTA Comparisons

Compared to TPH-YOLOv5, TPH-YOLOv5++ is about 1% lower on three metrics but still gets higher AP and AP75 than other methods.

- ViT-YOLO [61], which also wins 2nd place in the VisDrone Challenge 2021, achieves the SOTA results. (Hope I can read about ViT-YOLO later.)
Compared to other methods, TPH-YOLOv5 and TPH-YOLOv5++ have comparable results.
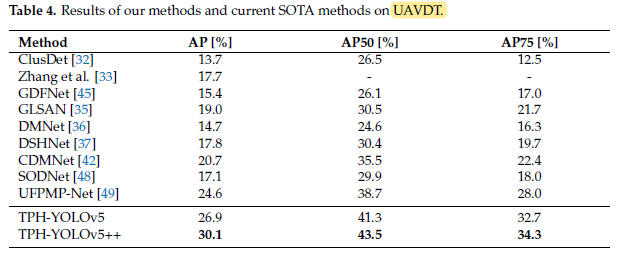
- TPH-YOLOv5 obtains more than a 2% performance gain at least, and is even 4.7% higher than UFPMPNet [49] on AP75.
Based on TPH-YOLOv5, TPH-YOLOv5++ further improves the performance to 30.1%, 43.5%, and 34.3% on these three metrics, which mean 3.2%, 2.2%, and 1.5% gains.
For datasets with less high-density scenes like UAVDT, TPH-YOLOv5++ can significantly overcome the shortcomings of TPH-YOLOv5.
3.2. Visualizations


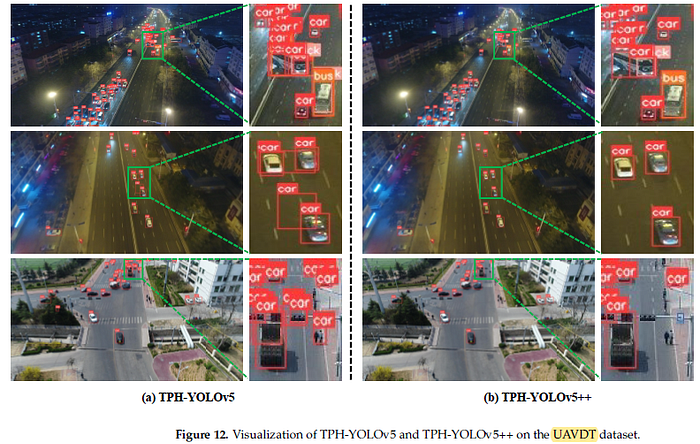
- For example, on the first row, the TPH-YOLOv5 detects the bus as multiple objects, while TPH-YOLOv5 can significantly decrease these wrong bounding boxes.
- On the second row, TPH-YOLOv5 detects a bounding box across the top two cars. By contrast, TPH-YOLOv5++ correctly predicts two cars.
- (For ablation studies, please feel free to read about the paper directly.)
