SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode
Small-Fast-YOLOv5 for Small Object Detection
SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode,
SF-YOLOv5, by Qilu University of Technology, and Dalhousie University,
2022 MDPI J. Sensors (Sik-Ho Tsang @ Medium)Object Detection
2014 … 2020 [EfficientDet] [CSPNet] [YOLOv4] [SpineNet] [DETR] [Mish] [PP-YOLO] [Open Images] 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] [HRNetV2, HRNetV2p] 2022 [PVTv2] [Pix2Seq] [MViTv2] 2023 [YOLOv7]
==== My Other Paper Readings Are Also Over Here ====
- An improved YOLOv5, Small-Fast-YOLOv5 (SF-YOLOv5), is proposed for small object detection.
- By reasonably clipping the feature map output of the large object detection layer, the computing resources required by the model were significantly reduced and the model becomes more lightweight.
- An improved feature fusion method (PB-FPN) for small object detection based on PANet and BiFPN (EfficientDet) is also proposed, which effectively increased the detection ability for small object of the algorithm.
- Spatial pyramid pooling (SPP) but fast version, namely SPPF, is introduced to connect the feature fusion network with the model prediction head, to enhance the performance.
Outline
- Brief Review of YOLOv5
- SF-YOLOv5
- Results
1. Brief Review of YOLOv5

- The image was processed through a input layer (input) and sent to the backbone for feature extraction.
- The backbone obtains feature maps of different sizes, and then fuses these features through the feature fusion network (neck) to finally generate three feature maps P3, P4, and P5 (in the YOLOv5, the dimensions are expressed with the size of 80×80, 40×40 and 20×20) to detect small, medium, and large objects in the picture, respectively.
- After the three feature maps were sent to the prediction head (head), the confidence calculation and bounding-box regression were executed for each pixel in the feature map using the preset prior anchor, so as to obtain a multi-dimensional array (BBoxes) including object class, class confidence, box coordinates, width, and height information.
- By setting the corresponding thresholds (confthreshold, objthreshold) to filter the useless information in the array, and performing a non-maximum suppression (NMS) process, the final detection information can be output.
- (Please feel free to read YOLOv5 for more details if interested.)
2. SF-YOLOv5
2.1. Feature Map Clipping

- The backbone is CSPDarknet53.
- The main structure is the stacking of multiple CBS (Conv + BatchNorm + SiLU) modules and C3 modules, and finally one SPPF module is connected.
- CBS module is used to assist C3 module in feature extraction, while SPPF module enhances the feature expression ability of the backbone.
C7 and C8 layers correspond to output C5 feature maps. Yet, the parameters of C7 and C8 occupies large amount of parameters within the backbone.
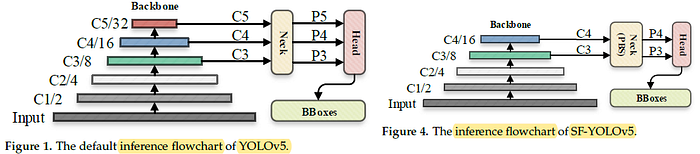
For the purpose of being lightweight, the default C5 feature map of the traditional YOLOv5 is deleted, as in Figure 4.
2.2. Feature Fusion Path (PB-FPN)
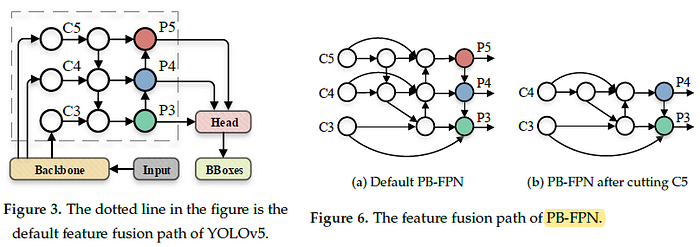
- A new feature fusion path is additionally introduced to further integrate the features from the high-level into the bottom.
New branches are set horizontally to participate in the fusion process of the bottom, which further enhances the detection effect of the algorithm for small targets.
2.3. Improved Feature Fusion Network (SPPF)
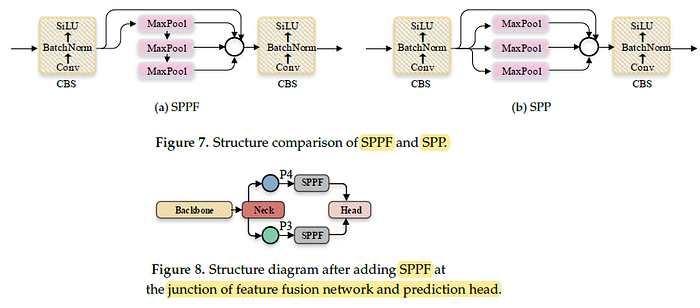
- YOLOv5 uses the SPPF (SPP-Fast) module.
- By simplifying the pooling process, SPPF avoided the repeated operation of SPP, as in SPPNet, and significantly improved the running speed of the module.
In this paper, SF-YOLOv5 introduces several SPPF modules at the connection between the feature fusion network and the model prediction head, in order to further tap the feature expression potential of the finally output feature map by the neck and sent to the head, and further enhance the performance of the model.
3. Results
3.1. WIDER FACE Dataset

- This dataset contains the annotation information of 393,703 faces. The dataset is highly variable in scale, posture, angle, light, and occlusion. The dataset is complex and includes a great quantity of dense small targets.
- In total, 4441 images were used to train the algorithm and 1123 images were used to verify the algorithm.

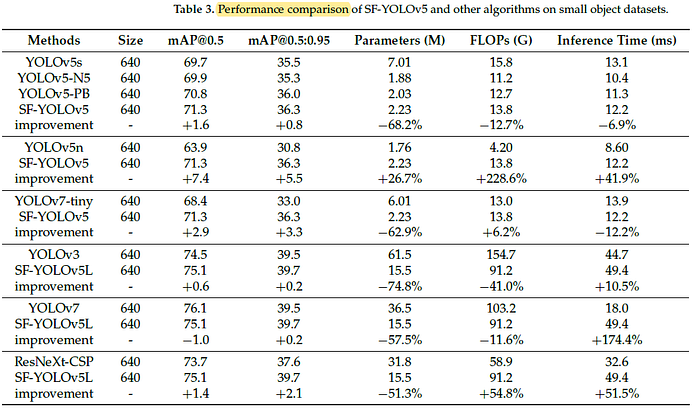
Compared with the traditional algorithm YOLOv5s, the mAP@0.5 and mAP@0.5:0.95 of SF-YOLOv5 has been increased by 1.6 and 0.8, respectively, which proved the improvement in comprehensive detection performance of SF-YOLOv5.
- At the same time, the parameters (M) value and FLOPs (G) value of SF-YOLOv5 are reduced by 68.2% and 12.7%, respectively, indicating that SF-YOLOv5 can further decrease the number of parameters and lessen computing power required for model operation.
On the whole, SF-YOLOv5L is better than YOLOv3, ResNeXt-CSP, and its performance is close to that of the latest YOLOv7.
3.2. Other Datasets

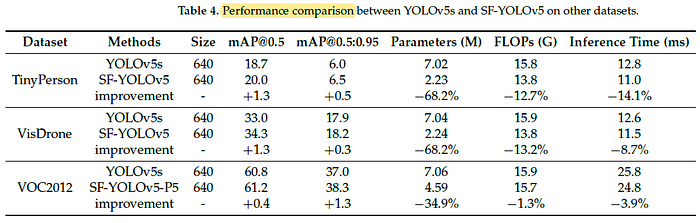
To sum up, SF-YOLOv5 still achieved improvement in detection accuracy and comprehensive performance on TinyPerson, VisDrone and VOC2012 datasets.
