Brief Review — GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Grouped-Query Attention (GQA), Outperforms Multi-Query Attention (MQA), Faster Than Conventional MHA in Transformer
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Grouped-Query Attention (GQA), by Google Research
2023 EMNLP, Over 80 Citations (Sik-Ho Tsang @ Medium)Language Model (LM)
2007 … 2022 [GLM] [Switch Transformers] [WideNet] [MoEBERT] [X-MoE] [sMLP] [LinkBERT, BioLinkBERT] [AlphaCode] 2023 [ERNIE-Code]
==== My Other Paper Readings Are Also Over Here ====
- Uptraining is proposed to uptrain existing multi-head language model checkpoints into models with Multi-Query Attention (MQA) using 5% of original pre-training compute.
- Grouped-Query Attention (GQA) is introduced, a generalization of multi-query attention, which uses an intermediate (more than one, less than number of query heads) number of key-value heads.
Outline
- Grouped-Query Attention (GQA)
- Results
1. Grouped-Query Attention (GQA)
1.1. Uptraining

Generating a multi-query model (MQA model) from a multi-head model (Conventional MHA model) takes place in two steps: first, converting the checkpoint, and second, additional pre-training for a small proportion α=0.05 of its original training steps.
- It is found that it works better than selecting a single key and value head or randomly initializing new key and value heads from scratch.
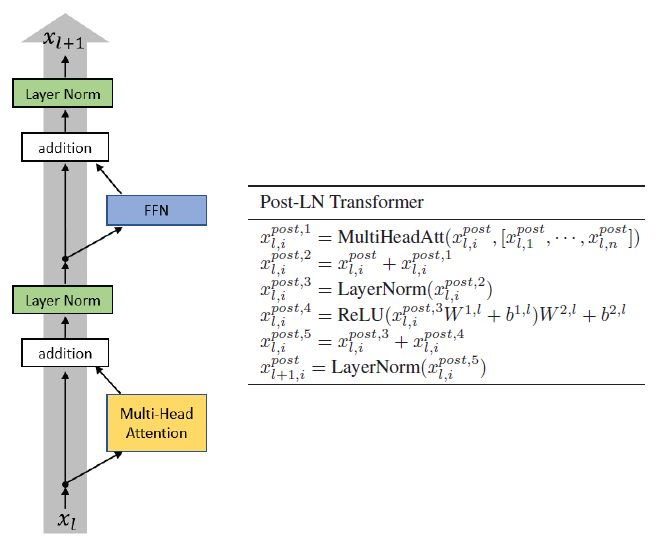
1.2. Grouped-Query Attention (GQA)

GQA-G refers to grouped-query with G groups.
- GQA-1, with a single group and therefore single key and value head, is equivalent to MQA.
- GQA-H, with groups equal to number of heads, is equivalent to MHA.
When converting a MHA checkpoint to a GQA checkpoint, each group key and value head are constructed by mean-pooling all the original heads within that group.
An intermediate number of groups leads to an interpolated model that is higher quality than MQA but faster than MHA.
1.3. Model
T5 Large and XXL with multi-head attention, as well as uptrained versions of T5 XXL with multi-query and grouped-query attention, are considered.
2. Results


GQA achieves significant additional quality gains, achieving performance close to MHA-XXL with speed close to MQA.