Review — GLM: General Language Model Pretraining with Autoregressive Blank Infilling
GLM, Fill in the Blanks Autoregressively. Later, GLM-130B is Built Based on GLM and Accepted in 2023 ICLR

GLM: General Language Model Pretraining with Autoregressive Blank Infilling, GLM, by Tsinghua University, Beijing Academy of Artificial Intelligence (BAAI), MIT CSAIL, and Shanghai Qi Zhi Institute,
2022 ACL, Over 15 Citations (Sik-Ho Tsang @ Medium)2.1. Language Model / Sequence Model
1991 … 2022 [GPT-NeoX-20B] [InstructGPT] [GLM]
==== My Other Paper Readings Are Also Over Here ====
- General Language Model (GLM) is proposed based on autoregressive blank infilling.
- GLM improves blank filling pretraining by adding 2D positional encodings and allowing an arbitrary order to predict spans.
- Meanwhile, GLM can be pretrained for different types of tasks by varying the number and lengths of blanks.
- Later on, GLM-130B is Built Based on GLM and Accepted in 2023 ICLR. And ChatGLM is established based on GLM-130B.
Outline
- GLM Pretraining
- GLM Model Architecture
- Results
1. GLM Pretraining

- GLM formulates NLU tasks as cloze questions that contain task descriptions, which can be answered by autoregressive generation.
1.1. Autoregressive Blank Infilling

- Given an input text x=[x1, …, xn], multiple text spans {s1, …, sm} are sampled, where each span si corresponds to a series of consecutive tokens [s_i,1;… ; s_i,li] in x.
- Each span is replaced with a single [MASK] token, forming a corrupted text xcorrupt.
When predicting the missing tokens in a span, the model has access to the corrupted text and the previously predicted spans.
- The order of the spans is randomly permuted, similar to the permutation language model (XLNet). Formally, let Zm be the set of all possible permutations of the length-m index sequence [1, 2, , …, m], and s_z<i be [s_z1, …, s_zi-1], the pretraining objective is defined as:

- The tokens in each blank are always generated following a left-to-right order, i.e. the probability of generating the span si is factorized as:


- The input x is divided into two parts: Part A is the corrupted text xcorrupt, and Part B consists of the masked spans.

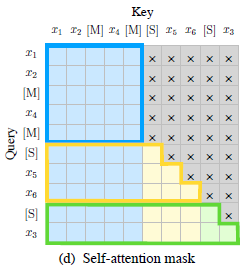
Part A tokens can attend to each other, but cannot attend to any tokens in B. Part B tokens can attend to Part A and antecedents in B, but cannot attend to any subsequent tokens in B.
- To enable autoregressive generation, each span is padded with special tokens [START] and [END], for input and output respectively.
In this way, GLM automatically learns a bidirectional encoder (for Part A) and a unidirectional decoder (for Part B) in a unified model.
- Spans of length are randomly sampled, drawn from a Poisson distribution with λ=3. New spans are repeatedly sampled until at least 15% of the original tokens are masked. Empirically, 15% ratio is critical for good performance on downstream NLU tasks.
1.2. Multi-Task Pretraining
- Authors are interested in pretraining a single model that can handle both NLU and text generation.
- A multi-task pretraining setup is studied, in which a second objective of generating longer text is jointly optimized with the blank infilling objective. The following two objectives are considered:
- Document-level: A single span is sampled whose length is sampled from a uniform distribution over 50%–100% of the original length. The objective aims for long text generation.
- Sentence-level: It is restricted that the masked spans must be full sentences. Multiple spans (sentences) are sampled to cover 15% of the original tokens. This objective aims for seq2seq tasks whose predictions are often complete sentences or paragraphs.
- Their only difference is the number of spans and the span lengths.
2. GLM Model Architecture
2.1. Model Architecture

- GLM uses a single Transformer with several modifications to the architecture: (1) The order of layer normalization and the residual connection is reaaranged, which has been shown critical for large-scale language models to avoid numerical errors (as in Megatron-LM); (2) A single linear layer for the output token prediction; (3) ReLUs are replaced with GELUs.
2.2. 2D Positional Encoding
- Each token is encoded with two positional ids.
- The first positional id represents the position in the corrupted text xcorrupt. For the masked spans, it is the position of the corresponding [MASK] token.
- The second positional id represents the intra-span position.
- For tokens in Part A, their second positional ids are 0. For tokens in Part B, they range from 1 to the length of the span.
- The two positional ids are projected into two vectors via learnable embedding tables, which are both added to the input token embeddings.
2.3. Finetuning GLM
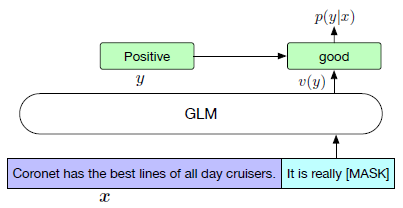
- Typically, for downstream NLU tasks, a linear classifier is added on top of the model, leading to inconsistency between pretraining and finetuning.
- Here, NLU classification tasks is reformulated as generation tasks of blank infilling, as above.
- Specifically, given a labeled example (x, y), the input text x is converted to a cloze question c(x) via a pattern containing a single mask token.
- The conditional probability of predicting y given x is:

- As an example in the figure, the labels “positive” and “negative” are mapped to the words “good” and “bad”. In this case, GLM is fine-tuned with a cross-entropy loss.
3. Results
3.1. SuperGLUE

- The pretrained GLM models are fine-tuned on each task.
GLM consistently outperforms BERT on most tasks with either base or large architecture. On average, GLMBase scores 4.6% higher than BERTBase, and GLMLarge scores 5.0% higher than BERTLarge.
- In the setting of RoBERTaLarge, GLMRoBERTa can still achieve improvements over the baselines, but with a smaller margin.
- Specifically, GLMRoBERTa outperforms T5Large but is only half its size.
- With multi-task pretraining, within one training batch, short spans and longer spans (document-level or sentence-level) are sampled with equal chances.
GLMDoc and GLMSent perform slightly worse than GLMLarge, but still outperform BERTLarge and UniLMLarge. Among multitask models, GLMSent outperforms GLMDoc by 1.1% on average.
3.2. Sequence-to-Sequence
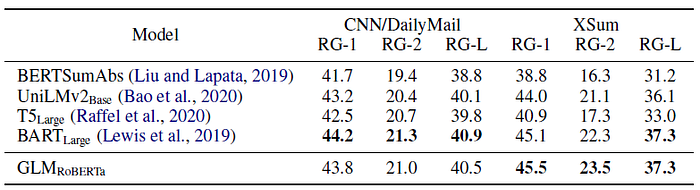
GLMRoBERTa can achieve performance matching the Seq2Seq BART model, and outperform T5 and UniLMv2.
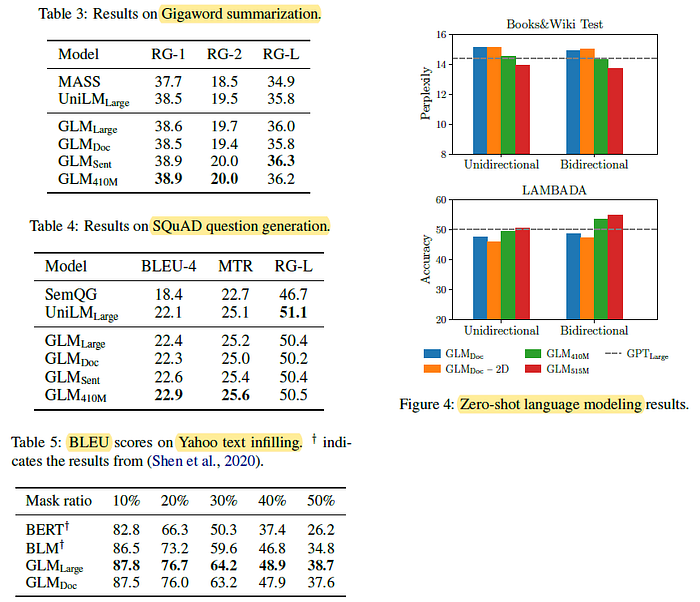
Tables 3 & 4: GLMLarge can achieve performance matching the other pretraining models on the two generation tasks. GLMSent can perform better than GLMLarge, while GLMDoc performs slightly worse than GLMLarge.
3.3. Text Filling
Table 5: GLM outperforms previous methods by large margins (1.3 to 3.9 BLEU) and achieves the state-of-the-art result on this dataset.
3.4. Language Modeling
- Figure 4: All the models are evaluated in the zero-shot setting.
Increasing the model’s parameters to 410M (1.25 of GPTLarge) leads to a performance close to GPTLarge.
- (There are also ablation experiments, please feel free to read the paper directly if you’re interested.)
