Review — WideNet: Go Wider Instead of Deeper
Using Mixture-of-Experts (MoEs) For Wider Network
Go Wider Instead of Deeper,
WideNet, by National University of Singapore,
2022 AAAI (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer] [CrossFormer++]
Language Model
1991 … 2023 [GPT-4] [LLaMA] [LIMA] [Koala] [BloombergGPT]
==== My Other Paper Readings Are Also Over Here ====
- WideNet, a parameter-efficient framework, is proposed which is going wider instead of deeper.
- The model is scaled along width by replacing feed-forward network (FFN) with mixture-of-experts (MoE).
- Individual layer normalizations are used to transform various semantic representations, instead of sharing.
Outline
- Brief Review of Mixture-of-Experts (MoE)
- WideNet
- Results (CV & NLP)
1. Brief Review of Mixture-of-Experts (MoE)
1.1. Conditional Computation
For each input, only a part of hidden representations are fed to be processed into the selected experts.
- As in MoE, given E trainable experts and input representation x, the output of MoE model can be formulated as:

- where e(.)i is a non-linear transformation of i-th expert. and g(.)i is i-th element of the output of trainable router g(.).
- When g(.) is a sparse vector, only part of experts would be activated.
- In this paper, for both vanilla MoE and the proposed WideNet, each expert is an FFN layer.
1.2. Routing
To ensure a sparse routing g(.), TopK() is used to select the top ranked experts:

- where f(.) is routing linear transformation. ε is Gaussian noise for exploration. When K<<E, most elements of g(x) would be zero.
1.3. Balanced Loading
- To optimize MoE, two things need to avoid:
- Too many tokens dispatched to one single expert, and
- Too few tokens received by one single expert.
To solve the first issue, buffer capacity B is required. That is, for each expert, only at most B token is preserved for each expert. If more than B=CKNL, all remaining tokens are dropped.
- where C= 1.2 ∈ [1, 2], K is the number of selected experts for each token. N is the batch size on each device. L is the sequence length.
- Yet, the above constraint on B still cannot ensure all experts to receive enough token to train.
- In this paper, Switch Transformer is followed, a differentiable load balance loss is used.
- The auxiliary loss is added to the total model loss during training:

- where m is vector. i-th element is the fraction of tokens dispatched to expert i:

- where h(.) is a index vector selected by TopK. h(xj)i is i-th element of h(xj).

- And Pi is i-th element of routing linear transformation after softmax.
The goal of load balancing loss is to achieve a balanced assignment. When lbalance is minimize, both m and P would close to a uniform distribution.
2. WideNet

2.1. Same Router & Experts in Different Transformer Blocks
- WideNet adopts parameter sharing across Transformer blocks to improve parameter efficiency, and MoE layer is used to improve model capacity.
- WideNet uses the same router and experts in different Transformer blocks.
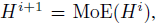
- which is different from existing MoE:
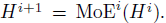
2.2. Individual Layer Normalization
- Existing works like ALBERT for parameter sharing, share all weights across Transformer blocks.
- For shared Layer Normalization, the input of MHA and MoE layer are more similar in different Transformer blocks.
In this paper, only multi-head attention layer and FFN (or MoE) layer are shared, which means trainable parameters of layer normalization are different across blocks.
- In summary, i-th Transformer block in the proposed framework can be written as:
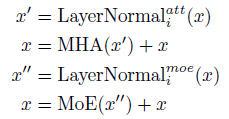
- The Layer Normalization layer LayerNormal(.) is:
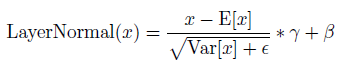
- where γ and β are trainable vectors.
Layer Normalization only requires these two small vectors so individual normalization would just add few trainable parameters into the proposed framework.
2.3. Loss Function
- Although the trainable parameters of the router are reused in every Transformer block, the assignment would be different due to different input representations.
- Therefore, given T times routing operation with the same trainable parameters, the following loss is used for optimization:
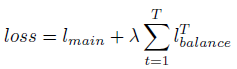
- where λ=0.01 is used as a hyperparameter to ensure a balanced assignment.
- lmain is the main target of the Transformer. For example, on supervised image classification, lmain is cross-entropy loss.
3. Results (CV & NLP)
3.1. ImageNet-1K (CV)

WideNet-H achieves the best performance and significantly outperforms ViT and ViT-MoE models on ImageNet-1K.
- Compared with the strongest baseline, WideNet-H outperforms ViT-B by 1.5% with less trainable parameters.
- Even for the smallest model, WideNet-B, it still achieves comparable performance with ViT-L and ViT-MoE-B with over 4× less trainable parameters.
- When scaling up to WideNet-L, it has surpassed all baselines with half trainable parameters of ViT-B and 0.13× parameters of ViT-L.
3.2. GLUE (NLP)
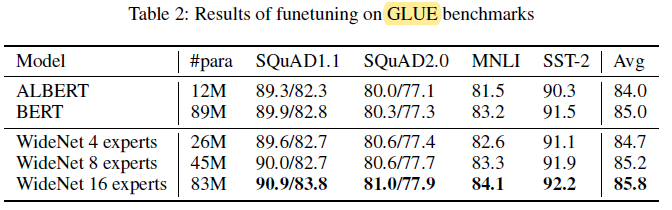
With more experts, WideNet outperforms ALBERT by a large margin.
- For instance, WideNet with 4 experts surpasses ALBERT by 1.2% in average.
- When increasing the number of experts E to 16 to achieve slightly less trainiable parameters than BERT with factorized embedding parameterization, WideNet also outperforms it on all four downstream tasks, which shows the parameter-efficiency and effectiveness of going wider instead of deeper.
3.3. Ablation Study (CV)
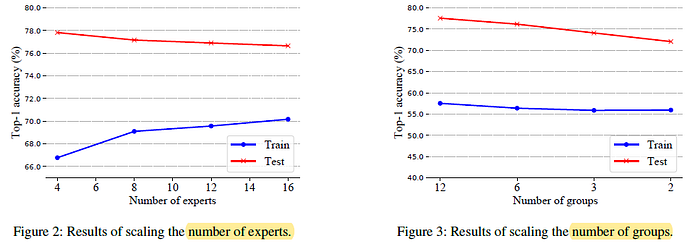
Figure 2 (Left): More experts (trainable parameters) lead to overfitting although more experts mean stronger modeling capacity.
- Figure 3 (Right): Transformer blocks using the same routing assignment that belongs to one group. When using fewer groups, which means fewer routing operations, there is an obvious performance drop. It is suggested less diversified tokens are fed to each expert because fewer groups mean less routing and assignments.

- For i-th element of trainable vector or in j-th block, the distance between this element and all other elements of all vectors from other blocks is computed:
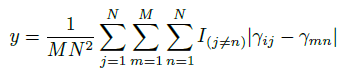
- where N is the number of Transformer blocks, M is the dimension of vector γ or β.
- As shown above, both γ and β in WideNet have larger y than those in ViT, which means MoE receives more diversified input than ViT.
Such result proves that individual Layer Normalization layer can help to model various semantics model with shared large trainable matrices like MoE.
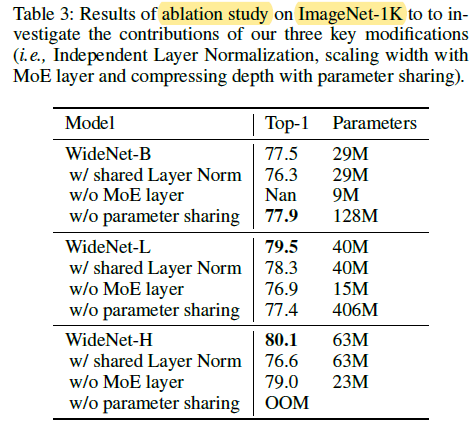
Without parameter sharing across Transformer blocks, it is also observed a slight performance drop and significant parameter increment.
- For WideNet-H without parameter sharing, it encounters out-of-memory when training on 256 TPUv3 cores.
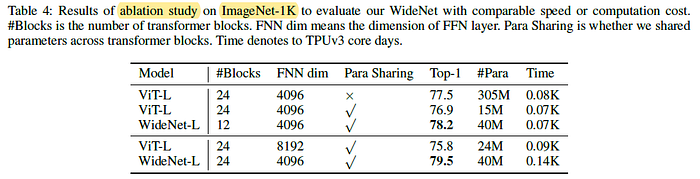
When WideNet-L uses fewer Transformer blocks (i.e., 12 blocks) than ViT-L, WideNet-L outperforms ViT-L by 0.7% with slightly less training time and 13.1% parameters, and, similarly, there is a larger performance improvement than ViT-L with parameter sharing.
