Review — Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Switch Transformer, Mixture of Experts (MoE) With 1 Expert Selected
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity,
Switch Transformer, by Google
2022 JMLR, Over 660 Citations (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] [Chinchilla] [PaLM] [AlexaTM] [BLOOM] [AlexaTM 20B] [OPT] 2023 [GPT-4]
==== My Other Paper Readings Are Also Over Here ====
- Mixture of Experts (MoE) is select different parameters for each incoming example, which is a sparsely-activated model with an outrageous number of parameters, but a constant computational cost. However, MoE is adoption has been hindered by complexity, communication costs, and training instability.
- Switch Transformer is proposed, which simplifies the MoE routing algorithm and intuitive improved models are designed with reduced communication and computational costs.
Outline
- Switch Transformer
- Improved Training and Fine-Tuning Techniques
- Downstream Results
1. Switch Transformer
1.1. Prior Mixture-of-Experts (MoE)
- MoE layer takes as an input a token representation x and then routes this to the best determined top-k experts, selected from a set {Ei(x)} for i from 1 to N of N experts.
- The router variable Wr produces logits h(x)=Wr⋅x which are normalized via a softmax distribution over the available N experts at that layer.
- The gate-value for expert i is given by:

- If T is the set of selected top-k indices then the output computation of the layer is the linearly weighted combination of each expert’s computation on the token by the gate value:

- (Please feel free to read MoE if interested.)
1.2. Proposed Switch Routing: Rethinking MoE

- Switch layer is proposed, which is a simplified strategy where input is routed to only a single expert, i.e. k=1. This simplification preserves model quality, reduces routing computation and performs better.
- The benefits for the Switch layer are three-fold:
- The router computation is reduced as a token is only routed to a single expert.
- The batch size (expert capacity) of each expert can be at least halved.
- The routing implementation is simplified and communication costs are reduced.
- Mesh-TensorFlow (MTF) (Shazeer et al., 2018) is used, which is a library, with similar semantics and API to TensorFlow that facilitates efficient distributed data and model parallel architectures.
1.3. Expert Capacity

- If the tokens are unevenly dispatched then certain experts will overflow (denoted by dotted red lines), resulting in these tokens not being processed by this layer. A larger capacity factor alleviates this overflow issue, but also increases computation and communication costs (depicted by padded white/empty slots).
- One important technical consideration is how to set the expert capacity:
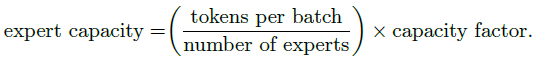
- A capacity factor greater than 1.0 creates additional buffer to accommodate for when tokens are not perfectly balanced across experts.
Empirically, it is found ensuring lower rates of dropped tokens are important for the scaling of sparse expert-models.
1.4. Loss Function
- For each Switch layer, this auxiliary loss is added to the total model loss during training. Given N experts indexed by i = 1 to N and a batch B with T tokens, the auxiliary loss is computed as the scaled dot-product between vectors f and P:
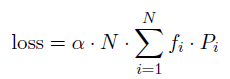
- where fi is the fraction of tokens dispatched to expert i:
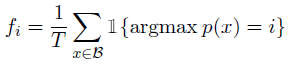
- and Pi is the fraction of the router probability allocated for expert i:
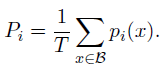
- α=10^(-2) such that the auxiliary loss is small enough to not to overwhelm the primary cross-entropy objective.
- Masked language modeling task is used as in BERT, with 15% token masked.
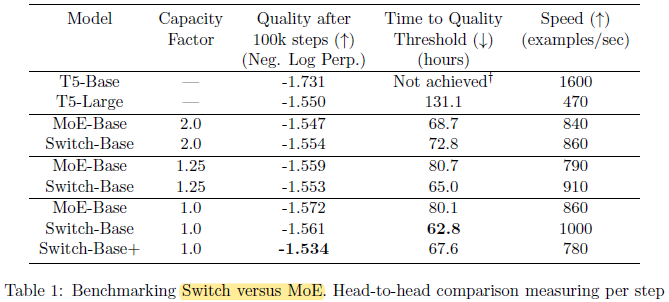
- MoE model going from capacity factor 2.0 to 1.25 actually slows down (840 to 790).
1) Switch Transformers outperform both carefully tuned dense models and MoE Transformers on a speed-quality basis.
2) The Switch Transformer has a smaller computational footprint than the MoE counterpart.
3) Switch Transformers perform better at lower capacity factors (1.0, 1.25).
2. Improved Training and Fine-Tuning Techniques
2.1. Selective Precision

- The router input is casted to float32 precision. The float32 precision is only used within the body of the router function.
- The resulting dispatch and combine tensors are recast to bfloat16 precision at the end of the function, no expensive float32 tensors are broadcast.
Selective precision obtains higher or comparable quality.
2.2. Reduce Initialization
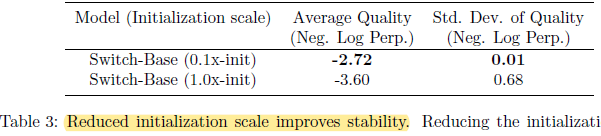
There is improvement of the model quality and reduction of the variance (Smaller variance when weight initialization) early in training.
2.3. Dropout
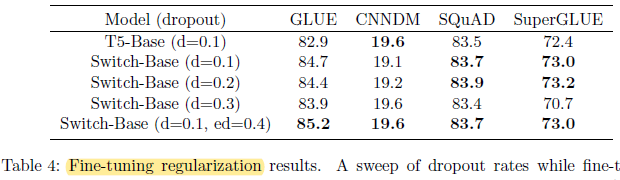
- Overfitting arises since many fine-tuning tasks have very few examples.
The Dropout inside the experts, i.e. expert Dropout (ed), is increased, to improve the performance.
3. Scaling

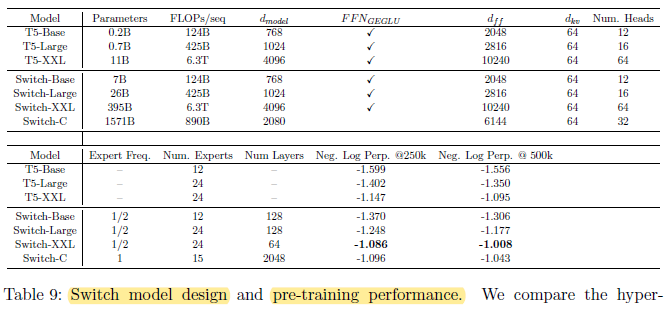
- The large C4 corpus with over 180B target tokens is used for training.
- Left: Consistent scaling properties (with fixed FLOPS per token) between sparse model parameters and test loss.
Right: Increasing the number of experts (e) leads to more sample efficient models.
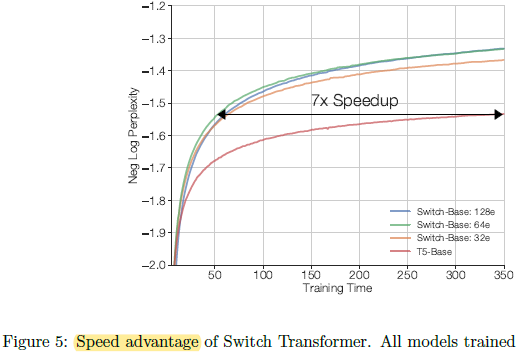
Switch-Base 64 expert model at step 60k achieves the same performance of the T5-Base model at step 450k, which is a 7.5× speedup in terms of step time.
4. Downstream Results
4.1. Fine-Tuning

Significant downstream improvements are obtained across many natural language tasks. Notable improvements come from SuperGLUE.
4.2. Distillation
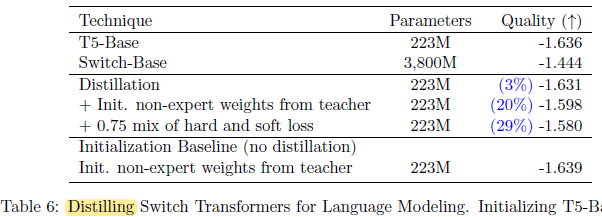
- Initializing the dense model with the non-expert weights yields a modest improvement.
A distillation improvement is observed using a mixture of 0.25 for the teacher probabilities and 0.75 for the ground truth label.
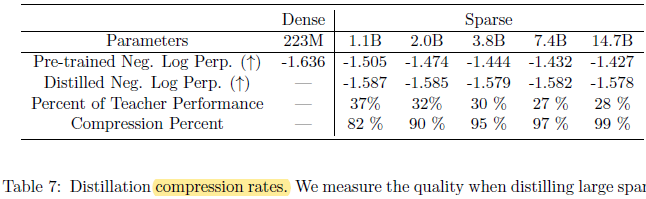
Through distillation, 37% of the quality gain of the 1.1B parameter model can be preserved while compressing 82%.
- At the extreme, compressing the model 99%, the model is still able to maintain 28% of the teacher’s model quality improvement.
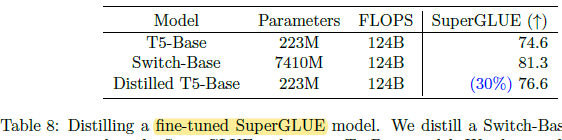
- Distilling a 7.4B parameter Switch-Base model, which is fine-tuned on the SuperGLUE task, obtain 76.6 on SuperGLUE.
4.3. Multilingual
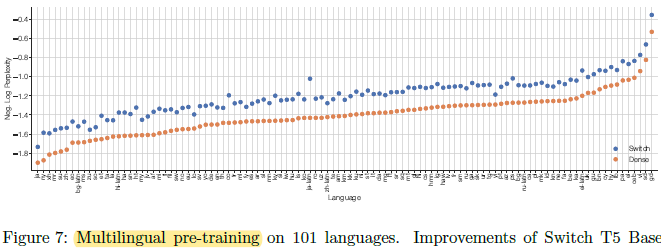
- The multilingual variant of the Common Crawl data set (mC4) spanning 101 languages, is used for pretraining.
On all 101 languages considered, Switch Transformer increases the final negative log perplexity over the baseline (dense).
More: Data, Model, and Expert-Parallelism

- When combining both model and expert-parallelism, all-to-all communication costs are still needed from routing the tokens to the correct experts along with the internal all-reduce communications from the model parallelism.
- Balancing the FLOPS, communication costs and memory per core becomes quite complex when combining all three methods where the best mapping is empirically determined.
- (Please feel free to read section 5.6. of the paper directly for this part if interested.)
