Brief Review — Imbalanced Image Classification with Complement Cross Entropy
Complement Cross Entropy (CCE) for Data Imbalance Dataset

Imbalanced Image Classification with Complement Cross Entropy
Complement Cross Entropy (CCE), by Gwangju Institute of Science and Technology (GIST)
2021 Pattern Recognition Letter, Over 60 Citations (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer] [CrossFormer++] [FastViT] [EfficientFormerV2] [MobileViTv2] [ConvNeXt V2] [SwiftFormer] 2024 [FasterViT]
==== My Other Paper Readings Are Also Over Here ====
- A simple but effective loss named complement cross entropy (CCE) is proposed, which makes the ground truth class overwhelm the other classes in terms of softmax probability, by neutralizing probabilities of incorrect classes, without additional training procedures.
- Along with it, this loss facilitates the models to learn key information especially from samples on minority classes.
Outline
- Problem in Cross Entropy (CE)
- Complement Cross Entropy (CCE)
- Results
1. Problem in Cross Entropy (CE)
- The softmax cross entropy, H(y, ^y) is defined as:

- where N is the number of examples, K is the number of categories, y(i) is the true distribution, and ^y(i) is the softmax multinomial prediction distribution.
However, this loss might be insufficient to explicitly minimize the predicted probabilities of incorrect classes, particularly for minority classes.
All softmax probabilities on incorrect classes are ignored in Eq. (1), because y(i)[j≠g] (where g denotes the ground truth index) is always zero when y(i) is a one-hot represented vector.
It means that y(i)[j≠g] in Eq. (1) is totally ignored, so inaccurately predicted probabilities may produce a cumulative error, particularly in the class-imbalanced distribution.
- Hence, CCE is proposed to tackle such performance degradation problem on imbalanced dataset.
2. Complement Cross Entropy (CCE)
2.1. CCE Loss
Complement entropy is designed to encourage models to learn enhanced representations by assisting the primary training objective, cross entropy (CE).
It is calculated as a mean of Shannon’s entropies on incorrect classes of the whole examples.
- The complement entropy, C(^y) is formulated as:

- where g represents the ground truth index.
The inverse of (1 — y(i)[g] normalizes ^y(i)[j] to make C(^y) imply the information underlying probability distribution on just incorrect classes.
The purpose of this entropy is to encourage the predicted probability of the ground truth class (^y(i)[g]) to be larger among the other incorrect classes.
- Further, a balanced complement entropy is introduce:
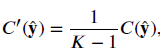
- where 1/(K — 1) is the balancing factor.
2.2. Total Loss
- Cross entropy loss and complement entropy loss are summed into a single entropy loss, with γ to weight the CCE loss:
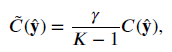
- Finally, the proposed loss, named complement cross entropy (CCE), is defined as:
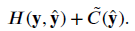

- The above pseudo codes show the CCE loss implementation.
3. Results
3.1. Imbalance Setting

- On CIFAR, Fashion MNIST and Tiny ImageNet, their underlying class distributions are balanced.
- Basically, imbalanced variants are constructed by randomly removing examples per each class, includes long-tail and step versions.
- Balanced accuracy (bACC) is measured by average recall for all classes.
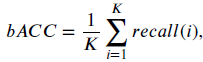
3.2. Performance
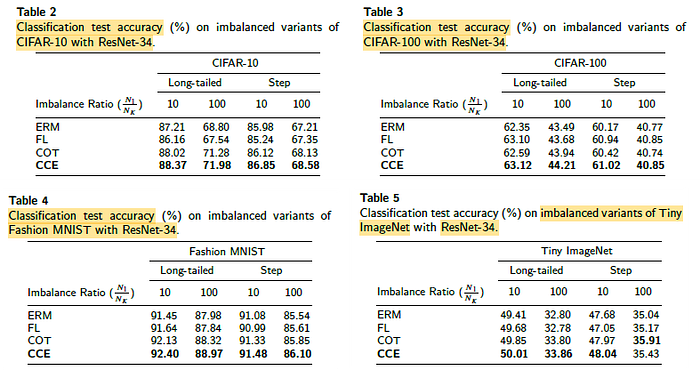
CCE performs the best among other losses on different datasets.
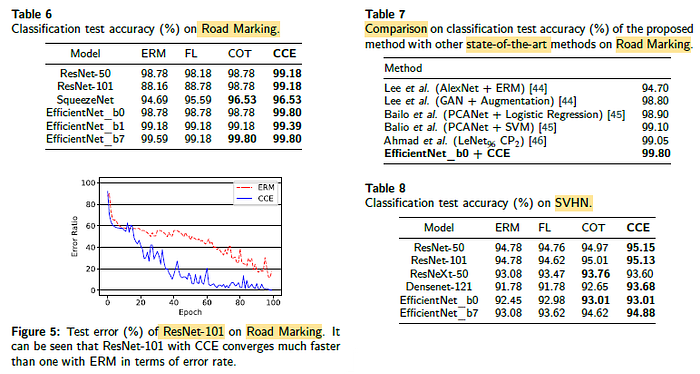
Different networks using CCE also got improvements.
