Review — SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications

SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications
SwiftFormer, by Mohamed bin Zayed University of AI; University of California, Merced; Yonsei University Google Research; Linköping University
2023 ICCV, Over 20 Citations (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer] [CrossFormer++] [FastViT] [EfficientFormerV2] [MobileViTv2] 2024 [FasterViT]
==== My Other Paper Readings Are Also Over Here ====
- Expensive matrix multiplication operations in self-attention within Transformer remain a bottleneck.
- In this work, a novel efficient additive attention mechanism is introduced that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications.
- The proposed design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy.
Outline
- SwiftFormer
- Results
1. SwiftFormer

1.1. Prior Arts
(a): The conventional self-attention can be described as:

(b): In [29], the dot-product operation is applied across the channel dimension instead of the spatial dimension. This allows the model to learn feature maps with implicit contextual representation:

- While this complexity scales linearly with the number of tokens n, it remains quadratic with respect to the feature dimension d. Further, the dot-product operation is still utilized between the query and key matrices.
(c): The separable self-attention mechanism is proposed in MobileViT-v2. First, the query matrix Q is projected to produce a vector q of dimensions n×1, and then fed into Softmax to generate the context scores, which captures the importance of each query element. Then, the context scores are multiplied by the key matrix K and pooled to compute a context vector:

1.2. SwiftFormer Additive Self-Attention
(d): The proposed efficient additive self-attention shows that the key-value interactions can be removed without sacrificing the performance and only focusing on effectively encoding query-key interactions by incorporating a linear projection layer is sufficient to learn the relationship between the tokens
- Specifically, the input embedding matrix x is transformed into query (Q) and key (K) using two matrices Wq, Wk.
- Next, the query matrix Q is multiplied by learnable parameter vector wa to learn the attention weights of the query, producing global attention query vector α:
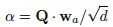
- Then, the query matrix is pooled based on the learned attention weights, resulting in a single global query vector q:
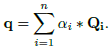
- Next, the interactions between the global query vector q and key matrix K are encoded using the element-wise product to form global context. This matrix shares a similarity with the attention matrix in MHSA and captures information from every token.
- However, it is comparatively inexpensive to compute compared to MHSA.
- The output of the efficient additive attention ˆx can be described as:
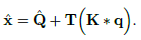
1.3. SwiftFormer Architecture
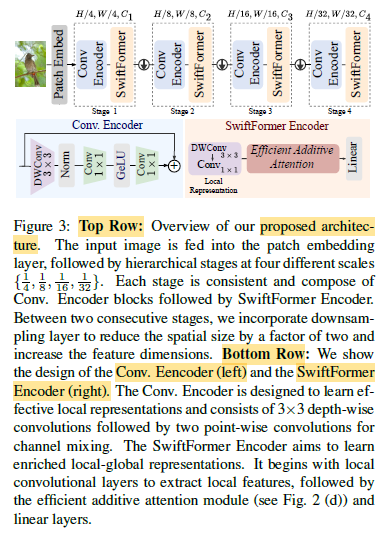
- SwiftFormer is based on the recently introduced EfficientFormer.
- SwiftFormer improves the token mixing by using a simple yet effective Conv. Encoder. This leads to more consistent learning of local-global representations.
- In contrast, SwiftFormer models are built without using any neural architecture search (NAS).
- As shown above, hierarchical features are extracted at four different scales across four stages.
- At the beginning of the network, the input image of size H×W×3 is fed through Patch Embedding layer, implemented with two 3×3 convolutions with a stride of 2.
- Then, the output feature maps are fed into the first stage, which begins with Conv. Encoder to extract spatial features, followed by SwiftFormer to learn the local-global information. Between two consecutive stages, there is a downsampling layer to increase the channel dimension and reduce the token length.
- Hence, each stage learns local-global features at different scales of the input image.
- Effective Conv. Encoder: Specifically, the features maps Xi are fed into 3 × 3 depth-wise convolution (DWConv) followed by Batch Normalization (BN). Then, the resulting features are fed into two point-wise convolutions (Conv1) alongside GeLU activation. The Conv. Encoder is defined as:
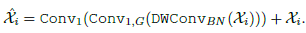
- SwiftFormer Encoder: As shown in Fig. 3, the initial block of the SwiftFormer Encoder is composed of 3 × 3 depth-wise convolution followed by point-wise convolution. Then, the resulting feature maps are fed into the efficient additive attention block.
- Finally, the output feature maps are fed into a Linear block, which composes of two 1×1 point-wise convolution layers, Batch Normalization, and GeLU activation to generate non-linear features. The SwiftFormer Encoder is described as:
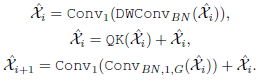
2. Results
2.1. Ablation Study

With all components, accuracy is improved without sacrificing the inference speed.
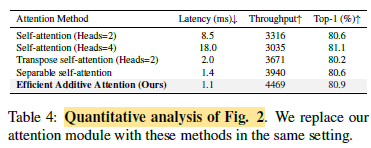
- The proposed efficient additive attention achieves the best trade-off between latency and top-1 accuracy.
2.2. ImageNet
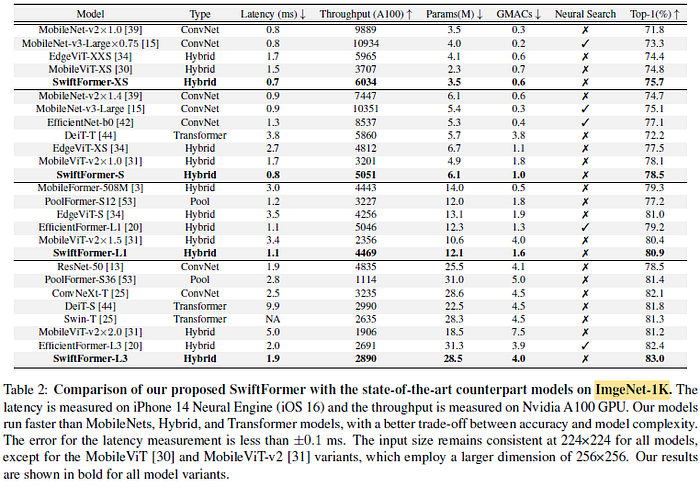
- Comparison with ConvNets: SwiftFormer models surpass the widely used lightweight CNNs counterparts significantly in terms of top-1 accuracy, while running faster than the highly optimized MobileNet-v2 and MobileNet-v3 on an iPhone 14 mobile device.
- Comparison with Transformer models: SwiftFormer-L3 model achieves 1.2% higher accuracy than DeiT-S, while running at the same speed as ResNet-50. Further, SwiftFormer-S model runs approximately 4.7× faster than DeiT-T on an iPhone 14 mobile device and has 6.3% better accuracy.
- Comparison with hybrid models: SwiftFormer-XS has better latency as compared to lightweight CNNs and approximately is 2× faster than EdgeViT-XXS and MobileViT-XS, with an overall 1.3% and 0.9% higher top-1 accuracy respectively. Further, SwiftFormer-L1 model is 3× faster than the stateof- the-art MobileViT-v2×1.5 with 0.5% better top-1 accuracy. SwiftFormer-L3 model achieves 83.0% top-1 accuracy and runs at 1.9 ms, which is 2.6× faster than MobileViT-v2×2.0 with an absolute 1.8% accuracy gain.
- Knowledge distillation (KD): SwiftFormer-L1 achieves 79.8% w/o KD, compared to 80.9% with KD. This shows that the proposed approach achieves a higher absolute gain of 2.5% over EfficientFormer-L1, when not using KD.
2.3. Dense Prediction Tasks
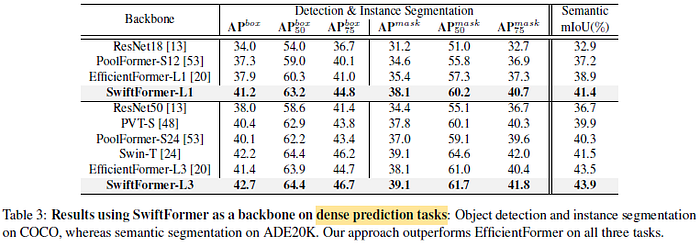
- The improvement in the downstream detection and instance segmentation tasks illustrates the effectiveness of SwiftFormer backbone models for the dense prediction tasks.
- Similarly, SwiftFormer-L3 backbone-based segmentation models achieve 43.9 mIoU, surpassing all previous methods.


SwiftFormer-L1 accurately detects and segments objects.
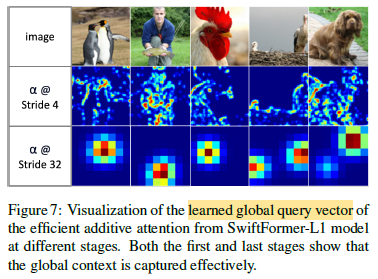
SwiftFormer localizes the features of the objects accurately with fine details in the first stage.
