Brief Review — Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Gopher, Analysis by Training Models with Different Model Scales
3 min readApr 1, 2023
Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Gopher, by DeepMind,
2021 arXiv v2, Over 250 Citations (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] 2023 [GPT-4]
==== My Other Paper Readings Are Also Over Here ====
- An analysis of Transformer-based language model performance is presented across a wide range of model scales — from models with tens of millions of parameters up to a 280 billion parameter model called Gopher.
Outline
- Gopher
- Results
1. Gopher
1.1. Models

6 Transformer language models ranging from 44 million to 280 billion parameters, are trained and evaluated.
- The largest one is named as Gopher and the entire set of models as the Gopher family.
- The autoregressive Transformer architecture is used but with two modifications:
- RMSNorm (Zhang and Sennrich, 2019) instead of LayerNorm, and
- The relative positional encoding scheme from Dai et al. (2019) is used rather than absolute positional encodings. Relative encodings permit us to evaluate on longer sequences than that is trained on, which improves the modelling of articles and books.
- The text is tokenized using SentencePiece with a vocabulary of 32,000 and use a byte-level backoff to support open-vocabulary modelling.
- All models are trained using 300 billion tokens with a 2048 token context window.
- Data and model parellelism is used.
1.2. Dataset

- Gopher family of models are trained on MassiveText, a collection of large English-language text datasets from multiple sources: web pages, books, news articles, and code, as above, with filtering, removal and deduplication processes.
Overall, MassiveText contains 2.35 billion documents, or about 10.5 TB of text.
2. Results
2.1. Evaluation Tasks

2.2. Overall Results
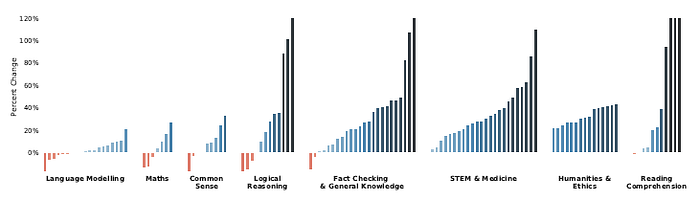
- Results are comparable across 124 tasks and the percent change is ploted in performance metric (higher is better) of Gopher versus the current LM SOTA.
Gopher outperforms the current state-of-the-art for 100 tasks (81% of all tasks). The baseline model includes LLMs such as GPT-3 (175B parameters), Jurassic-1 (178B parameters), and MT-NLG (530B parameters).
