Review — GPT-NeoX-20B: An Open-Source Autoregressive Language Model
GPT-NeoX-20B, First LLM Open to Public
GPT-NeoX-20B: An Open-Source Autoregressive Language Model,
GPT-NeoX-20B, by EleutherAI,
2022 ACL, Over 40 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Large Language Model, LLM, GPT, GPT-2, GPT-3, FairSeq
- GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, is introduced. To the best of authors’ knowledge, this is the largest dense autoregressive model that has publicly available weights at the time of submission.
- GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models.
Outline
- GPT-NeoX-20B
- Results
1. GPT-NeoX-20B
- GPT-NeoX-20B is an autoregressive transformer decoder model, which largely follows that of GPT-3, with a few notable deviations.
- The model has 20 billion parameters, 44 layers, a hidden dimension size of 6144, and 64 heads.
1.1. Rotary Positional Embeddings
- Rotary embeddings, as in RoFormer, are used instead of the learned positional embeddings used in GPT models.

1.2. Parallel Attention + FF Layers
- The Attention and Feed-Forward (FF) layers are computed in parallel and the results are summed:

- This is primarily for efficiency purposes, as each residual addition with op-sharding requires one all-reduce in the forward pass and one in the backwards pass. By computing the Attention and FFs in parallel, the results can be reduced locally before performing a single all-reduce.
- Due to an oversight in code, two independent Layer Norms are unintentionally applied instead of using a tied layer norm the way:

1.3. Initialization
- For the Feed-Forward output layers before the residuals, the initialization scheme introduced in Wang (2021) is used, 2/(L√d).
- For all other layers, the small init scheme from Nguyen and Salazar (2019) i used, √(2(d+4d)).
1.4. All Dense Layers
- While GPT-3 uses alternating dense and sparse layers, authors instead opt to exclusively use dense layers to reduce implementation complexity.
1.5. Software Libraries
- The model is trained using a codebase that builds on Megatron (Shoeybi et al., 2020) and DeepSpeed (Rasley et al., 2020).
1.6. Hardware

- GPT-NeoX-20B is trained on twelve Supermicro AS-4124GO-NART servers, each with eight NVIDIA A100-SXM4–40GB GPUs and configured with two AMD EPYC 7532 CPUs. They are communicated using fast speed connections.
1.7. Training Data
- GPT-NeoX-20B was trained on the Pile (Gao et al., 2020), a massive curated dataset designed specifically for training large language models. It consists of data from 22 data sources, coarsely broken down into 5 categories:
- Academic Writing: Pubmed Abstracts and PubMed Central, arXiv, FreeLaw, USPTO Backgrounds, PhilPapers, NIH Exporter.
- Web-scrapes and Internet Resources: CommonCrawl, OpenWebText2, StackExchange, Wikipedia (English).
- Prose: BookCorpus2, Bibliotik, Project Gutenberg.
- Dialogue: Youtube subtitles, Ubuntu IRC, OpenSubtitles, Hacker News, EuroParl.
- Miscellaneous: GitHub, the DeepMind Mathematics dataset, Enron Emails.
In aggregate, the Pile consists of over 825 GiB of raw text data.
1.8. Tokenization

- For GPT-NeoX-20B, a BPE-based tokenizer similar to that used in GPT-2 is used, with the same total vocabulary size of 50257, with three major changes to the tokenizer:
- First, a new BPE tokenizer is trained based on the Pile.
- Second, the GPT-NeoX-20B tokenizer applies consistent space delimitation regardless. This resolves an inconsistency regarding the presence of prefix spaces.
- Third, tokenizer contains tokens for repeated space tokens.
2. Results
2.1. Training & Validation Loss
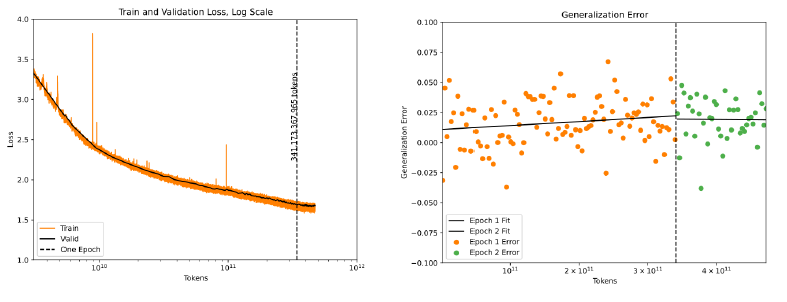
- In the past two years, the standard practice when training autoregressive language models has become to train for only one epoch.
As shown in the above figure, even at the 20B parameter scale, there is no drop in test validation loss after crossing the one epoch boundary.
2.2. Zero-Shot on Natural Language Tasks
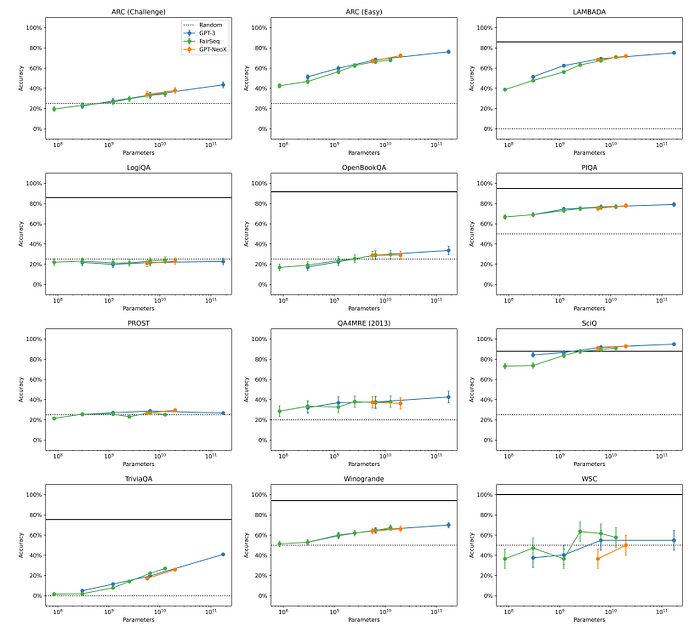
- While GPT-NeoX-20B outperforms FairSeq 13B on some tasks (e.g. ARC, LAMBADA, PIQA, PROST), it underperforms on others (e.g. HellaSwag, LogiQA zeroshot).
In total, across the 32 evaluations, GPT-NeoX-20B outperforms on 22 tasks, underperform on 4 tasks, and fall within the margin of error on 6 tasks.
2.3. Zero-Shot on Mathematics
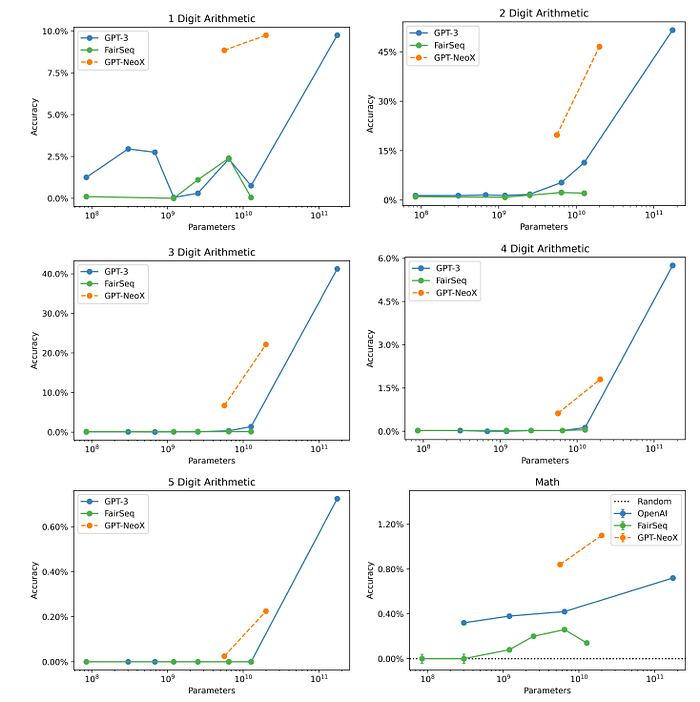
- While GPT-3 and FairSeq models are generally quite close on arithmetic tasks, they are consistently outperformed by GPT-J and GPT-NeoX.
2.4. Five-Shot Setting on MMMLU
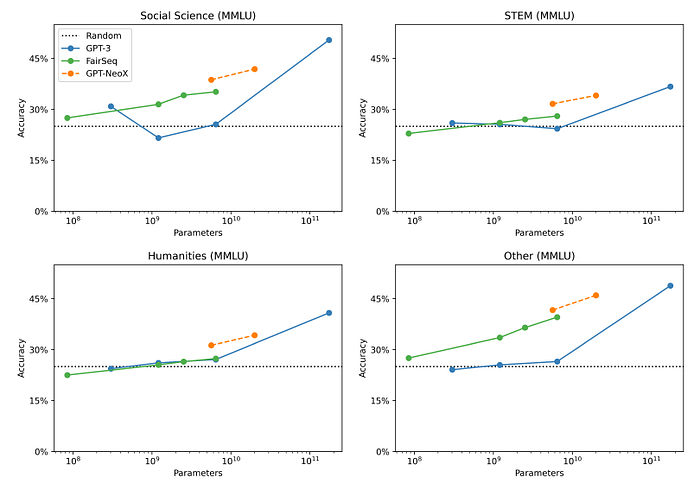
While authors do not have systematic five-shot evaluations of GPT-3 due to financial limitations, teh above figure suggests that GPT-J-6B and GPT-NeoX-20B are able to gain significantly more utility from five-shot examples.
The public release of the model is the most important contribution of this paper.
(The paper has 42 pages, I only present some here, please feel free to read the paper directly for more details.)
Reference
[2022 ACL] [GPT-NeoX-20B]
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
2.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART] [Longformer] [ELECTRA] [Megatron-LM] [SpanBERT] [UniLMv2] 2021 [Performer] [gMLP] [RoFormer] 2022 [GPT-NeoX-20B]
