Brief Review — XLM-R: Unsupervised Cross-lingual Representation Learning at Scale
Multilingual Language Model
2 min readOct 28, 2023
Unsupervised Cross-lingual Representation Learning at Scale
XLM-R, by Facebook AI
2020 ACL, Over 4100 Citations (Sik-Ho Tsang @ Medium)Language Model (LM)
2007 … 2022 [GLM] [Switch Transformers] [WideNet] [MoEBERT] [X-MoE]
==== My Other Paper Readings Are Also Over Here ====
- A Transformer-based masked language model, dubbed XLM-R, is trained on 100 languages, using more than 2 terabytes of filtered CommonCrawl data.
Outline
- XLM-R
- Results
1. XLM-R
- A Transformer model is used similar to XLM.
- Batches from different languages are sampled using the same sampling distribution as XLM but with α=0.3.
- Unlike XLM, language embedding is not used to better deal with code-switching.
- XLM-R is trained on 100 languages.

- 1 CommonCrawl dump is used for English and 12 dumps are used for all other languages.
2. Results
2.1. XNLI
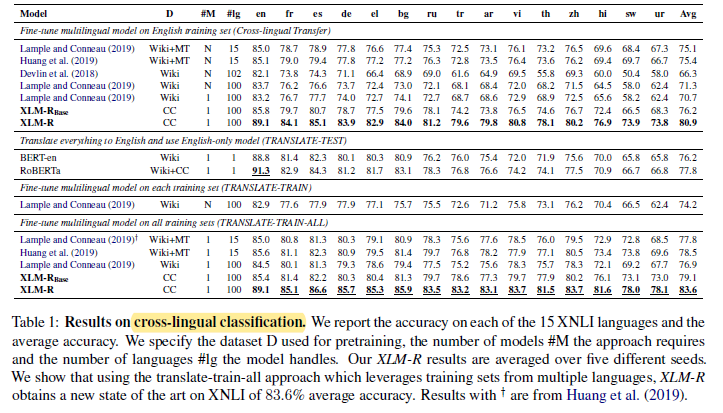
XLM-R sets a new state of the art on XNLI.
2.2. NER

On this task, XLM-R also outperforms mBERT by 2.42 F1 on average for cross-lingual transfer, and 1.86 F1 when trained on each language. Training on all languages leads to an average F1 score of 89.43%, outperforming cross-lingual transfer approach by 8.49%.
2.3. MLQA

XLM-R obtains F1 and accuracy scores of 70.7% and 52.7% while the previous state of the art was 61.6% and 43.5%. XLM-R also outperforms mBERT by 13.0% F1-score and 11.1% accuracy.
- It even outperforms BERT-Large on English, confirming its strong monolingual performance.
- (Please read the paper directly for more experimental results.)
