Review — XLM: Cross-lingual Language Model Pretraining
XLM, Using Multiple Languages, Outperforms BERT

Cross-lingual Language Model Pretraining
XLM, by Facebook AI Research
2019 NeurIPS, Over 1000 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, BERT, Transformer
- Cross-lingual language model (XLM) is proposed to leverage parallel data with a new cross-lingual language model objective.
Outline
- Cross-lingual Language Models
- Results Using Cross-lingual Language Model Pretraining
1. Cross-lingual Language Models
- CLM, MLM, TLM objectives are defined here.
1.1. Shared Sub-word Vocabulary
- All languages are processed with the same shared vocabulary created through Byte Pair Encoding (BPE). This greatly improves the alignment of embedding spaces across languages that share either the same alphabet or anchor tokens such as digits or proper nouns.
- Sentences are sampled according to a multinomial distribution with probabilities:

1.2. Causal Language Modeling (CLM)
- The causal language modeling (CLM) task consists of a Transformer language model trained to model the probability of a word given the previous words in a sentence:

- However, this technique does not scale to the cross-lingual setting.
1.3. Masked Language Modeling (MLM)

- Following BERT, 15% of the BPE tokens are sampled randomly from the text streams, replaced by a [MASK] token 80% of the time, by a random token 10% of the time, and kept unchanged 10% of the time.
- Differences between the approach here and the MLM of BERT include the use of text streams of an arbitrary number of sentences (truncated at 256 tokens) instead of pairs of sentences.
- Both the CLM and MLM objectives are unsupervised and only require monolingual data. However, these objectives cannot be used to leverage parallel data.
1.4. Translation Language Modeling (TLM)

- A new translation language modeling (TLM) objective is introduced for improving cross-lingual pretraining, which is an extension of MLM.
- Instead of considering monolingual text streams, parallel sentences are concatenated.
e.g.: To predict a masked English word, the model can attend to both the English sentence and its French translation, and is encouraged to align English and French representations.
1.5. Cross-lingual Language Models
- In this work, cross-lingual language model pretraining with either CLM, MLM, or MLM used in combination with TLM, are considered.
- For the CLM and MLM objectives, the model is trained with batches of 64 streams of continuous sentences composed of 256 tokens. At each iteration, a batch is composed of sentences coming from the same language, which is sampled from the distribution {qi}i=1…N above, with α=0.7.
- When TLM is used in combination with MLM, these two objectives are alternated, and the language pairs are sampled with a similar approach.
1.6. Model Architecture
- A Transformer architecture with 1024 hidden units, 8 heads, GELU activations , a Dropout rate of 0.1 and learned positional embeddings, is used.
- For machine translation, only 6-layer Transformer is used. For XNLI, 12-layer Transformer is used.
2. Results Using Cross-lingual Language Model Pretraining
2.1. Cross-lingual Classification

- The pretrained XLM models provide general-purpose cross-lingual text representations.
- XLMs are fine-tuned on a cross-lingual classification benchmark. The cross-lingual natural language inference (XNLI) dataset is used to evaluate the approach.
- Precisely, a linear classifier is added on top of the first hidden state of the pretrained Transformer, and all parameters are fine-tuned on the English NLI training dataset.
By leveraging parallel data through the TLM objective (MLM+TLM), a significant boost in performance of 3.6% accuracy is obtained, improving even further the state of the art to 75.1%.
2.2. Unsupervised Machine Translation
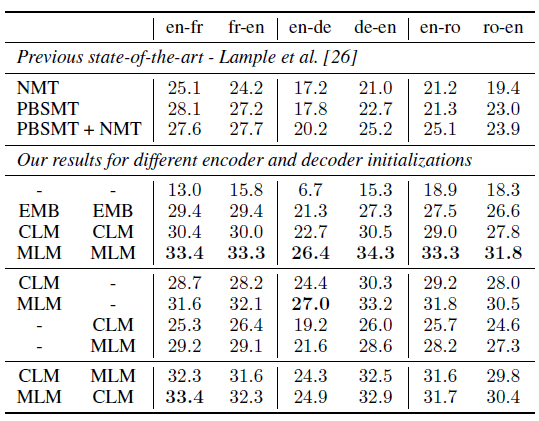
- By pretraining the entire encoder and decoder with a cross-lingual language model, Unsupervised Neural Machine Translation (UNMT) task can be improved.
- WMT’14 English-French, WMT’16 English-German and WMT’16 English-Romanian are used.
In German-English, the best model outperforms the previous unsupervised approach by more than 9.1 BLEU, and 13.3 BLEU if we only consider neural unsupervised approaches. MLM leads to consistent significant improvements of up to 7 BLEU on German-English.
2.3. Supervised Machine Translation

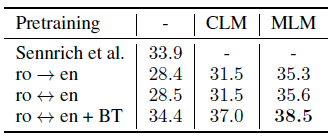
- It is extended to multilingual NMT.
- The impact of both CLM and MLM pretraining on WMT’16 Romanian-English is evaluated. (mono-directional (ro→en), bidirectional (ro↔en), and bidirectional with back-translation (ro↔en + BT))
Pretraining with the MLM objective leads to the best performance. The proposed bidirectional model trained with back-translation obtains the best performance and reaches 38.5 BLEU, outperforming the previous SOTA of Sennrich.
2.4. Low-resource Language Modeling
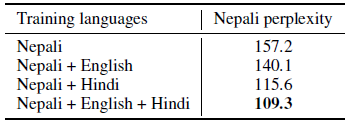
- For low-resource languages, it is often beneficial to leverage data in similar but higher-resource languages, especially when they share a significant fraction of their vocabularies.
- For instance, there are about 100k sentences written in Nepali on Wikipedia, and about 6 times more in Hindi. These two languages also have more than 80% of their tokens in common in a shared BPE vocabulary of 100k subword units.
By leveraging data from both English and Hindi, the perplexity is reduced to 109.3 on Nepali.
2.5. Unsupervised Cross-lingual Word Embeddings
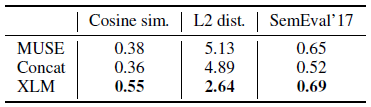
- A shared vocabulary is used, but the word embeddings are obtained via the lookup table of our cross-lingual language model (XLM).
- Cosine similarity and L2 distance between source words and their translations.
XLM outperforms both MUSE and Concat on cross-lingual word similarity, reaching a Pearson correlation of 0.69.
Instead of using single language, XLM uses multiple languages for pretraining.
Reference
[2019 NeurIPS] [XLM]
Cross-lingual Language Model Pretraining
Language Model
2007 … 2019 [T64] [Transformer-XL] [BERT] [RoBERTa] [GPT-2] [DistilBERT] [MT-DNN] [Sparse Transformer] [SuperGLUE] [FAIRSEQ] [XLNet] [XLM] 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT]
Machine Translation
2014 … 2019 [XLM] 2020 [Batch Augment, BA] [GPT-3] [T5] [Pre-LN Transformer] [OpenNMT] 2021 [ResMLP] [GPKD]
