Review — CenterNet: Keypoint Triplets for Object Detection (Object Detection)
Detecting Objects as Keypoint Triplet, Outperforms CornerNet, RefineDet, CoupleNet, RetinaNet, GRF-DSOD, DSOD, DSSD, SSD, YOLOv2, G-RMI, TDM, FPN, Faster R-CNN, etc.

In this story, CenterNet: Keypoint Triplets for Object Detection, (CenterNet), by University of Chinese Academy of Sciences, Huazhong University of Science and Technology, Huawei Noah’s Ark Lab, CAS, and Peng Cheng Laboratory, is reviewed. In this story:
- CenterNet detects each object as a triplet of keypoints, rather than a pair of keypoints like CornerNet, which improves both precision and recall.
- Two customized modules, cascade corner pooling, and center pooling, that enrich information collected by both the top-left and bottom-right corners and provide more recognizable information from the central regions.
This is a paper in 2019 ICCV over 380 citations. (Sik-Ho Tsang @ Medium)
Outline
- CenterNet: Overall Procedures
- Scale-aware Central Region Exploration (CRE)
- Center Pooling (CTP)
- Cascade Corner Pooling (CCP)
- Experimental Results
1. CenterNet: Overall Procedures

1.1. Network Architecture
- CornerNet is used as baseline. Thus, the backbone is similar to CornerNet. The stacked hourglass network used in Newell ECCV’16, with 52 and 104 layers as the backbone.
- CornerNet detects a pair of corners for each object.
- In contrast, for CenterNet, each object uses a center keypoint and a pair of corners.
- A heatmap for the center keypoints is embedded on the basis of CornerNet and the offsets of the center keypoints are predicted.
1.2. Overall Procedures
- The general detection steps are as follows:
- Top-k center keypoints are selected according to their scores.
- The corresponding offsets are used to remap these center keypoints to the input image.
- A central region is defined for each bounding box and check whether the central region contains center keypoints. And the class should be the same for the central region and the center keypoints.
- If a center keypoint is detected in the central region, the bounding box is preserved. The score of the bounding box is replaced by the average scores of the triple points.
- If there are no center keypoints detected in the central region, the bounding box will be removed.
- (Since the overall procedures are based on CornerNet. Please feel free to read CornerNet first if interested.)
1.3. Loss Function
- To train the network, a loss similar to CornerNet is used:

- where co means corners and ce means center.
- The losses are basically the same except there are additional terms related to the center keypoint.
2. Scale-aware Central Region Exploration (CRE)
- The size of the central region in the bounding box affects the detection results.
- Small central regions lead to a low recall rate for small bounding boxes, while large central regions lead to a low precision for large bounding boxes.
A a scale-aware central region to adaptively fit the size of bounding boxes.
The scale-aware central region tends to generate a relatively large central region for a small bounding box and a relatively small central region for a large bounding box.
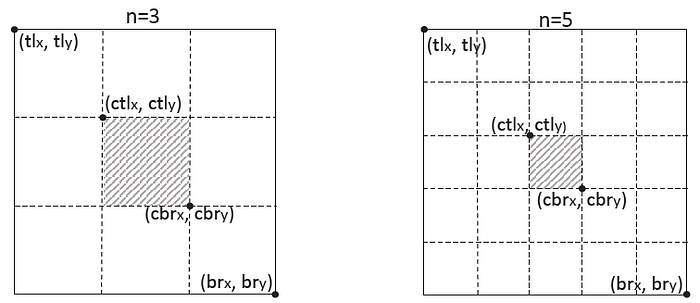
- For the bounding box i, let tlx and tly denote the coordinates of the top-left corner of i and brx and bry denote the coordinates of the bottom-right corner of i.
- For a central region j, let ctlx and ctly denote the coordinates of the top-left corner of j and cbrx and cbry denote the coordinates of the bottom-right corner of j.
- Then tlx, tly, brx, bry, ctlx, ctly, cbrx and cbry should satisfy the following relationship:
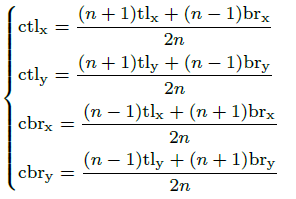
- where n is odd and determines the scale of the central region j.
- In this paper, n is set to be 3 and 5 for the scales of bounding boxes less than and greater than 150, respectively, as shown above.
3. Center Pooling (CEP)

- The geometric centers of objects do not always convey very recognizable visual patterns. (e.g., the human head contains strong visual patterns, but the center keypoint is often in the middle of the human body.)
- Center pooling is used to capture richer and more recognizable visual patterns.
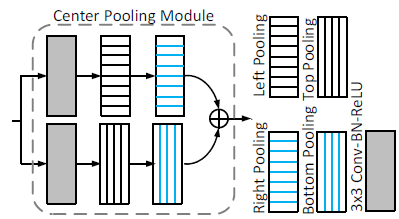
- The backbone outputs a feature map and to determine whether a pixel in the feature map is a center keypoint.
- CenterNet finds the maximum value in both the horizontal and vertical directions and adds these values together.
- By doing so, center pooling helps improve the detection of center keypoints.
In the above example, the head and the shoulder might have larger values at the feature map, CenterNet find them, and add them together for the center heatmap.
- This steps are performed for generating the center heatmap.
4. Cascade Corner Pooling (CCP)
4.1. Corner Pooling in CornerNet

- Corners are often outside objects, which lack local appearance features. This issue is also occurred in CornerNet.
e.g. the boundaries of head and shoulder may have weaker feature responses than the centers of head and shoulder respectively.
4.2. Proposed Cascaded Corner Pooling (CCP)
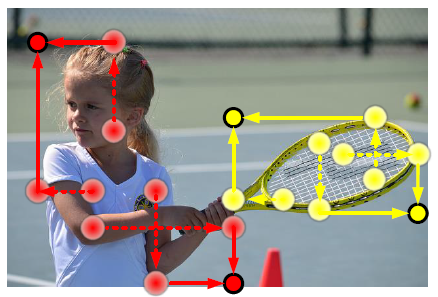
- To address this problem, CenterNet enables corners to extract features from central regions as shown above.
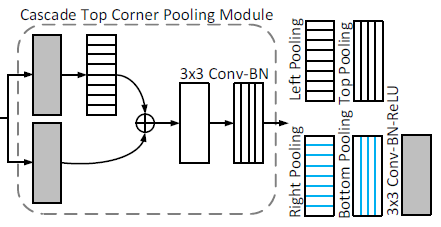
- Cascade corner pooling first looks along a boundary to find a maximum boundary value and then looks inside the box along with the location of the boundary maximum value to find an internal maximum value.
- Finally, the two maximum values are added together.
By cascade corner pooling, the corners obtain both the boundary information and the visual patterns of objects.
5. Experimental Results
5.1. Ablation Study

- Three components to CenterNet object detection, namely, central region exploration (CRE), center pooling (CTP), and cascade corner pooling (CCP), are tested.
- The baseline is CornerNet511–52.
- With all enabled, the best results are obtained.
5.2. Comparison with SOTA Approaches

- CenterNet511-52 (which means that the resolution of input images is 511 × 511 and the backbone is Hourglass-52) reports a single-scale testing AP of 41.6%, an improvement of 3.8% over 37.8%, and a multi-scale testing AP of 43.5%, an improvement of 4.1% over 39.4%, achieved by CornerNet under the same setting.
- When using the deeper backbone (i.e., Hourglass-104), the AP improvement over CornerNet are 4.4% (from 40.5% to 44.9%) and 4.9% (from 42.1% to 47.0%) under the single-scale and multi-scale testing, respectively.
These results demonstrate the effectiveness of CenterNet.
- In addition, the greatest comes from small objects. For instance, CenterNet511–52 improves the AP for small objects by 5.5% (single-scale) and by 6.4% (multi-scale).
- For the backbone Hourglass-104, the improvements are 6.2% (single-scale) and 8.1% (multi-scale), respectively.
This benefit stems from the center information modeled by the center keypoints.
And CenterNet outperforms CornerNet, RefineDet, CoupleNet, RetinaNet, GRF-DSOD, DSOD, DSSD, SSD, YOLOv2, G-RMI, TDM, FPN, Faster R-CNN, etc.
5.3. Inference Speed
- The average inference time of CornerNet511–104 is 300ms per image and that of CenterNet511–104 is 340ms per image.
- Meanwhile, using the Hourglass-52 backbone can speed up the inference speed. CenterNet511–52 takes an average of 270ms to process each image, which is faster and more accurate than CornerNet511–104.
5.4. Incorrect Bounding Box Reduction
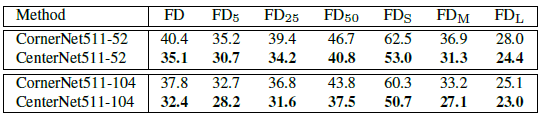
- CornerNet generates many incorrect bounding boxes even at the IoU = 0.05 threshold, i.e., CornerNet511–52 and CornerNet511–104 obtain 35.2% and 32.7% FD rates, respectively.
CenterNet decreases the FD rates at all criteria by exploring the central regions.
- The FD rates for small bounding boxes decrease the most, with decreases of 9.5% by CenterNet511–52 and 9.6% by CenterNet511–104.
5.5. Error Analysis
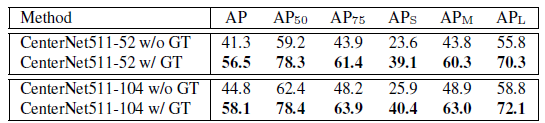
- With the use of ground-truth values for center keypoints, AP increases a lot which means there is still room for improvement.
5.6. Qualitative Results

Reference
[2019 ICCV] [CenterNet]
CenterNet: Keypoint Triplets for Object Detection
Object Detection
2014: [OverFeat] [R-CNN]
2015: [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net]
2016: [OHEM] [CRAFT] [R-FCN] [ION] [MultiPathNet] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [SSD] [YOLOv1]
2017: [NoC] [G-RMI] [TDM] [DSSD] [YOLOv2 / YOLO9000] [FPN] [RetinaNet] [DCN / DCNv1] [Light-Head R-CNN] [DSOD] [CoupleNet]
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet] [RefineDet] [CornerNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD] [CenterNet]

