Review — GloVe: Global Vectors for Word Representation
Using global corpus statistics for learning word representation, outperforms CBOW in Word2Vec
In this story, GloVe: Global Vectors for Word Representation, (GloVe), by Stanford University, is briefly reviewed. In this paper:
- Instead of local information, global corpus statistics is utilized for learning word representation.
This is a paper in 2014 EMNLP with over 24000 citations. (Sik-Ho Tsang @ Medium)
Outline
- The Statistics of Word Occurrences in a Corpus
- GloVe: Global Vectors
- Word Analogy Task Results
1. The Statistics of Word Occurrences in a Corpus
- Let the matrix of word-word co-occurrence counts be denoted by X, whose entries Xij tabulate the number of times word j occurs in the context of word i.
- Let Xi = Σk Xik be the number of times any word appears in the context of word i.
- Finally, let Pij=P(j|i)=Xij/Xi be the probability that word j appear in the context of word i.

- Let i=ice, and j=steam.
- For words k related to ice but not steam, say k=solid, we expect the ratio Pik/Pjk will be large.
- Similarly, for words k related to steam but not ice, say k=gas, the ratio should be small.
- For words k like water or fashion, that are either related to both ice and steam, or to neither, the ratio should be close to one.
Compared to the raw probabilities, the ratio is better able to distinguish relevant words (solid and gas) from irrelevant words (water and fashion) and it is also better able to discriminate between the two relevant words.
Word vector learning should be with ratios of co-occurrence probabilities rather than the probabilities themselves.
- Noting that the ratio Pik/Pjk depends on three words i, j, and k:

- where w is word vector, ~w is separate context word vector.
- One of the designs for F could be neural network.
2. GloVe: Global Vectors
- The cost function is to be minimized in order to find w:

- where V is the size of the vocabulary.
The training objective of GloVe is to learn word vectors such that their dot product equals the logarithm of the words’ probability of co-occurrence.
- If Xij=0, log Xij is undefined. f(Xij) is added such that f(Xij)=0 when Xij=0:
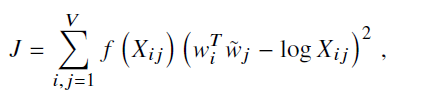
- Further, bias is added for completeness:
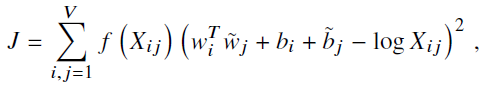
- GloVe is essentially a log-bilinear model with a weighted least-squares objective.
3. Word Analogy Task Results

- The word analogy task consists of questions like, “a is to b as c is to ?” The dataset contains 19,544 such questions, divided into a semantic subset and a syntactic subset.
- The question “a is to b as c is to ?” by finding the word d whose representation wd is closest to wb-wa+wc according to the cosine similarity.
The GloVe model performs significantly better than the other baselines such as CBOW in Word2Vec, often with smaller vector sizes and smaller corpora.
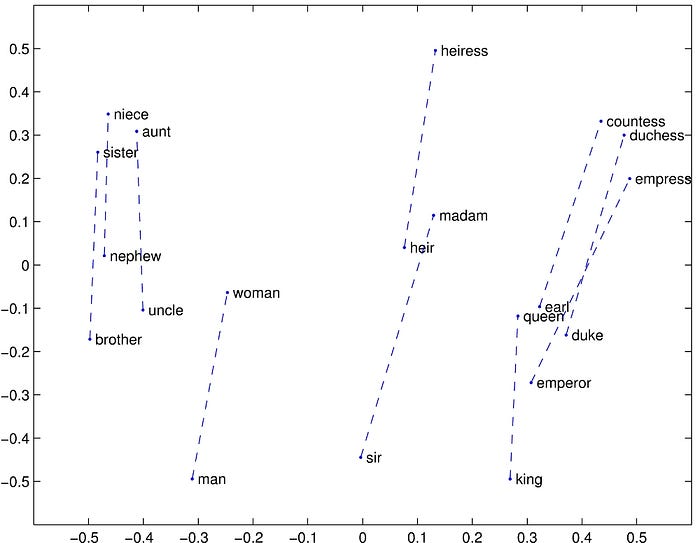
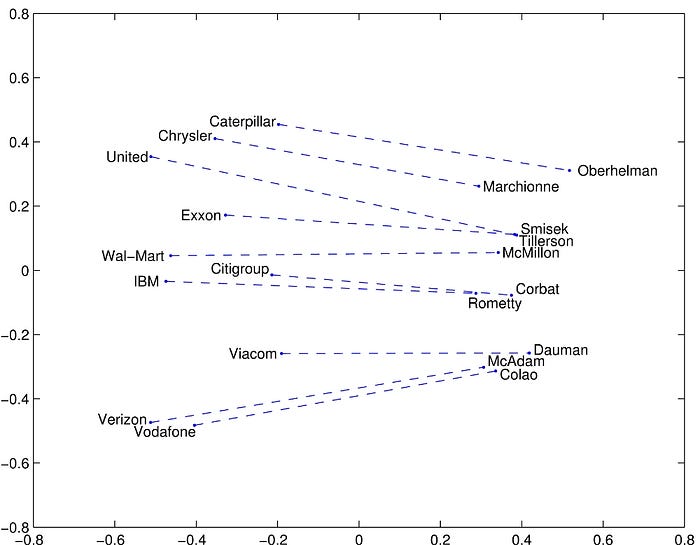
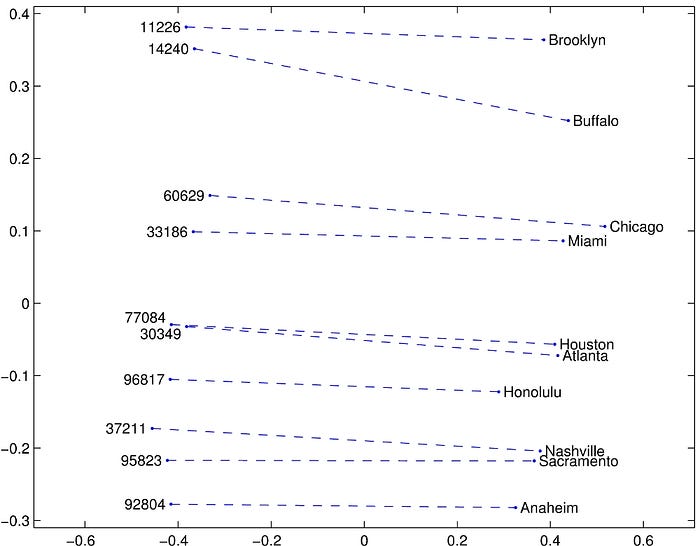
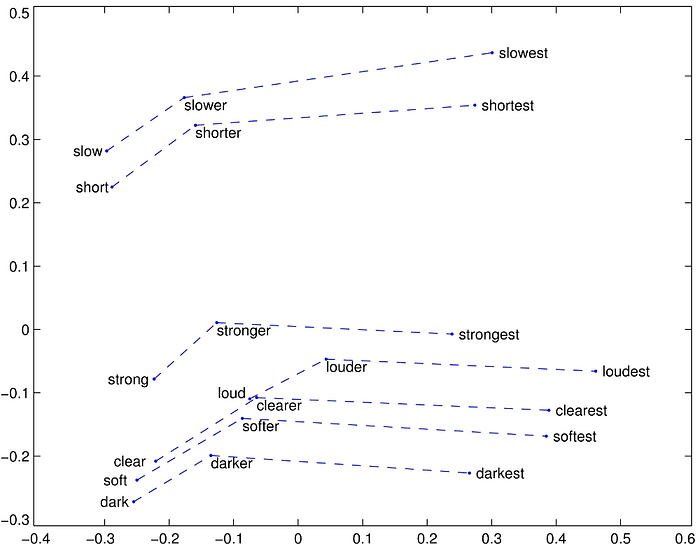
- The above visualized some examples.
There are still other experiments, please feel free to read the paper if interested. Prof. Andrew Ng has also presented GloVe in a very good way which is very easy to understand. It is really worth watching if you have taken his online course. :)
References
[2014 EMNLP] [GloVe]
GloVe: Global Vectors for Word Representation
Paper Website: https://nlp.stanford.edu/projects/glove/
Natural Language Processing (NLP)
Language Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
