Review — ImageNet-ReaL: Are we done with ImageNet?
Reassessed Labels (ReaL): New Labels for ImageNet
3 min readFeb 15, 2022

Are we done with ImageNet?
ImageNet-ReaL, by Google Brain (Zürich, CH), and DeepMind (London, UK)
2020 arXiv, Over 80 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Image Dataset, ImageNet
- “Has the community started to overfit to the idiosyncrasies of ImageNet labeling procedure?”
- To answer this, authors develop a significantly more robust procedure for collecting human annotations of the ImageNet.
- Now, except the original ImageNet, some papers also test their models on ImageNet-V2 set, and ImageNet-ReaL set, which is proposed in this paper.
Outline
- Problem and Relabeling of the ImageNet Set
- Experimental Results
1. Problem and Relabeling of the ImageNet

1.1. Single label per image (Top)
- Real-world images often contain multiple objects of interest. ImageNet annotations are limited to assigning a single label to each image, which can lead to a gross underrepresentation of the content of an image.
- This motivates re-annotating the ImageNet validation set in a way that captures the diversity of image content in real-world scenes.
1.2. Overly restrictive label proposals (Middle)
- The ImageNet annotation pipeline consists of querying the internet for images of a given class, then asking human annotators whether that class is indeed present in the image. While this procedure yields reasonable descriptions of the image, it can also lead to inaccuracies.
- Yet when considered together with other ImageNet classes, this description immediately appears less suitable (the “quill” is in fact a “feather boa”, the “passenger car” a “school bus”).
- Based on this observation, authors seek to design a labeling procedure which allows human annotators to consider (and contrast) a wide variety of potential labels, so as to select the most accurate description(s).
1.3. Arbitrary Class Distinctions (Bottom)
- ImageNet classes contain a handful of essentially duplicate pairs, which draw a distinction between semantically and visually indistinguishable groups of images.
- For example, the original ImageNet labels distinguish “sunglasses” from “sunglass”, “laptop” from “notebook”, and “projectile, missile” from “missile”.
- By allowing multiple annotations from simultaneously-presented label proposals, Authors seek to remove this ambiguity and arrive at a more meaningful metric of classification performance.
Relabeling and label cleaning is done to obtain ImageNet-ReaL set.
1.4. Relabeling
- In brief, relabeling is first preliminary done by models. These models suggest a set of label proposals. Human annotators are then further label the image based on the proposals.
- Since each image can contain more than one labels, a new metric is suggested called ReaL accuracy. It measures the precision of the model’s top-1 prediction, which is deemed correct if it is included in the set of labels, and incorrect otherwise.
- Also, sigmoid loss is used instead of the softmax loss since sigmoid loss which does not enforce mutually exclusive predictions.
2. Experimental Results

- Training on clean ImageNet data consistently improves accuracy of the resulting model.
- Changing the softmax loss to the sigmoid loss also results in consistent accuracy improvements across all ResNet architectures and training settings.
- Combining clean data and sigmoid loss leads to further improvements.
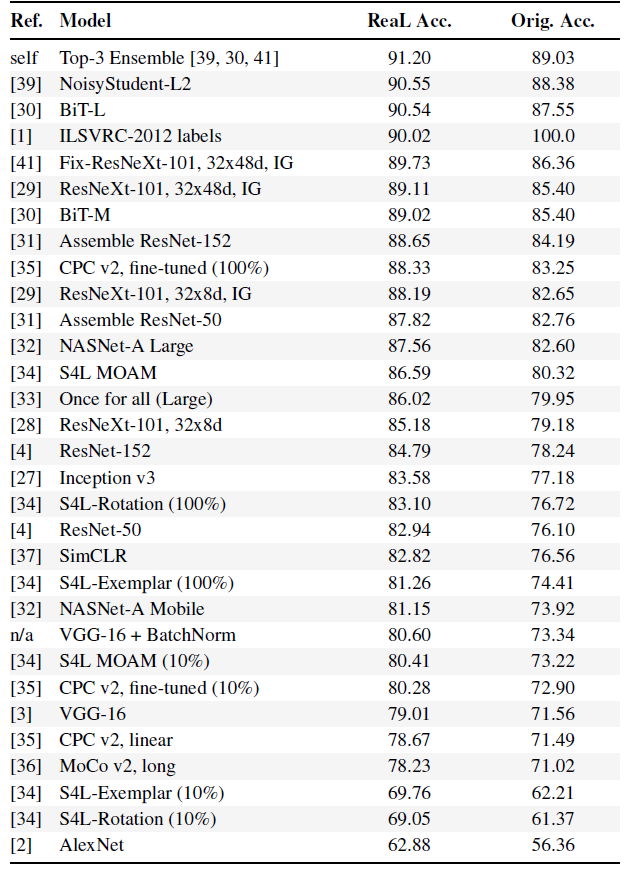
- Authors also evaluated other models for ReaL accuracies and original accuracy, as shown above.
Reference
[2020 arXiv] [ImageNet-ReaL]
Are we done with ImageNet?
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2]
