Review — Learning to Resize Images for Computer Vision Tasks (Image Classification & Image Quality Assessment)
Learned Resizer Instead of Conventional Resizers, Joint Learning of Image Resizer and Recognition Model

In this story, Learning to Resize Images for Computer Vision Tasks, (Learned Resizer), by Google Research, is reviewed.
- Typically, to be efficient, the input images are resized to a relatively small spatial resolution (e.g. 224×224), before inputting into the CNN for both training and inference.
- An off-the-shelf image resizers such as bilinear and bicubic are used.
- In this paper, the typical linear resizer is replaced with learned resizers that can substantially improve performance.
This is a paper in 2021 ICCV. (Sik-Ho Tsang @ Medium)
Outline
- Learned Resizer Model
- Experimental Results on Image Classification
- Experimental Results on Image Quality Assessment (IQA)
- Further Ablation Study
1. Learned Resizer Model

1.1. Network Architecture
- The most important characteristics of this model are (1) the bilinear feature resizing, and (2) the skip connection that accommodates combining the bilinearly resized image and the CNN features.
- (1) The former factor allows for incorporation of features computed at original resolution into the model.
- The bilinear feature resizer acts as a feed-forward bottleneck (down-scaling), but in principle it can also act as an inverse bottleneck as well (up-scaling).
- The proposed architecture allows for resizing an image to any target size and aspect ratio.
- (2) Also, the skip connection accommodates for an easier learning process.
- The residual blocks, in ResNet, are used here. There are r identical residual blocks.
- All intermediate convolutional layers have n = 16 kernels of size 3×3.
- The first and the last layers consist of 7×7 kernels. The larger kernel size in the first layer allows for a 7×7 receptive field on the original image resolution.
- Batch normalization layers and LeakyReLu activations with a 0.2 negative slope coefficient, are used.
1.2. Number of Parameters

- The above table shows the number of parameters using different number of residual blocks r and different number of convolutional filters n.
- The proposed resizer model is relatively lightweight and does not add a significant number of trainable parameters.
r=1 and n=16 are used.
1.3. Loss Functions
1.3.1. Image Classification
- When using the learned resizer, there is no loss or regularization constraint on the resized image.
- For image classification, the models are trained with the cross-entropy loss:
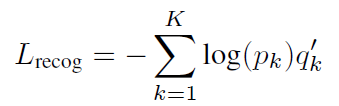
- The label-smoothing regularization, in Inception-v3, is also used. The label regularization prevents the largest logit from dominating the other logits, leading to a less confident model and less overfitting.
- ImageNet dataset is used for evaluation.
1.3.2. Image Quality Assessment (IQA)
- Each image in the AVA dataset [23] has a histogram of human ratings, with scores ranging from 1 to 10.
- Following the recent work in [36], the Earth Mover’s Distance (EMD) is used as the training loss.
- The last layer of the baseline model is modified to have 10 logits, with a Softmax layer:
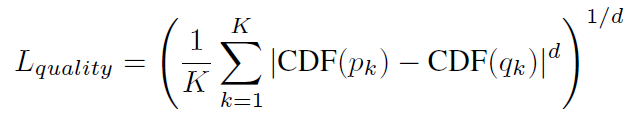
- where CDF(.) is the cumulative distribution function.
- d=2 is found to be effective. K is equal to 10 for AVA dataset.
- The EMD loss accommodates learning the distribution of human ratings. This has proven to be more effective than regressing to the mean ratings.

- The above table summarized the tasks implemented in this paper.
2. Experimental Results on Image Classification

- As can be seen, networks trained with the proposed resizer show an overall improvement over the default baseline.
- Comparing to the default baseline, DenseNet-121 and MobileNetV2 baselines show the largest and smallest gains, respectively.
- Also, it is worth mentioning that for the Inception-v2, DenseNet-121, and ResNet-50 models, the proposed resizer performs better than the bilinear resizer with comparable FLOPS.
- However, training the MobileNetV2 model with bilinear resizer at higher resolutions is more effective than using the learned resizer with similar FLOPS.
- Training resizers with equal input and output resolutions also results in improvement.


- Interestingly these effects tend to make the classification model more effective. Aside from the MobileNetV2 results, the other models tend to create overly sharpened results.
Overall, these effects do not meet the perceptual bar for human vision, but they surely improve the machine vision task.

- The learned resizers are trained with the initial baseline and then jointly fine-tuned with the target baseline model. The resizer’s input and output resolutions are 368×368 and 224×224, respectively.
- These results show that a resizer trained for one baseline can be effectively used to develop a resizer for another baseline with minimal fine-tuning.
3. Experimental Results on Image Quality Assessment (IQA)

- The proposed resizer performs better than the bicubic resizer with comparable FLOPS.
- At higher FLOPS, EfficientNet seems to be a more challenging baseline for the learned resizer.

- The residual images show the difference between the bicubic and the learned resizer. As can be seen, the residual image for the Inception-v2 and the DenseNet models represent a lot of fine grain details.
- On the other hand, the EfficientNet resizer shows a strong color shift and modest detail manipulations.

- The learned resizers are trained with the initial baseline and then jointly fine-tuned with the target baseline model. The resizer’s input and output resolutions are 368×368 and 224×224, respectively
- Similar to image classification, a resizer trained for one baseline can be effectively used to develop a resizer for another baseline with minimal fine-tuning.
4. Further Ablation Study

- The number of residual blocks r, and the number of filters n are varied to see the effect.
- In the classification task, as the resizer model gets bigger, the DenseNet and the MobileNetV2 baselines show modest improvements over the default configuration.
- However, Inception-v2 and ResNet do not benefit from larger number of parameters in the resizer.
- A similar trend can be observed in the IQA task.
- Perhaps one of the reasons for the non-growing performance of the larger resizer models is the lowered batch size.
- Note that given limited memory, larger resizers have to be trained with smaller batch sizes.
Reference
[2021 arXiv] [Learned Resizer]
Learning to Resize Images for Computer Vision Tasks
Image Classification
1989–1998: [LeNet]
2012–2014: [AlexNet & CaffeNet] [Dropout] [Maxout] [NIN] [ZFNet] [SPPNet] [Distillation]
2015: [VGGNet] [Highway] [PReLU-Net] [STN] [DeepImage] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2]
2016: [SqueezeNet] [Inception-v3] [ResNet] [Pre-Activation ResNet] [RiR] [Stochastic Depth] [WRN] [Trimps-Soushen]
2017: [Inception-v4] [Xception] [MobileNetV1] [Shake-Shake] [Cutout] [FractalNet] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [IGCNet / IGCV1] [Deep Roots]
2018: [RoR] [DMRNet / DFN-MR] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2] [CondenseNet] [IGCV2] [IGCV3] [FishNet] [SqueezeNext] [ENAS] [PNASNet] [ShuffleNet V2] [BAM] [CBAM] [MorphNet] [NetAdapt] [mixup] [DropBlock] [Group Norm (GN)]
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet] [CB Loss]
2020: [Random Erasing (RE)] [SAOL] [AdderNet]
2021: [Learned Resizer]
Image Quality Assessment (IQA)
FR: [DeepSim] [DeepIQA]
NR: [IQA-CNN] [IQA-CNN++] [DeepCNN] [DeepIQA] [DeepBIQ] [MEON] [DB-CNN] [Learned Resizer]
