Review: RandAugment
A Set of Data Augmentation Choices is Randomized

RandAugment: Practical automated data augmentation with a reduced search space, RandAugment, by Google Research, Brain Team
2020 NeurIPS, Over 600 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Data Augmentation
- For NAS-based data augmentation approaches, such as AutoAugment (AA), large search space is needed to find a set of augmentation techniques. This separate search phase significantly complicates training and is computationally expensive.
- In RandAugment, a simple but effective way is proposed to randomly select a set of augmentation techniques.
Outline
- RandAugment
- Experimental Results
1. RandAugment
1.1. N: Number of Transformation

- The primary goal of RandAugment is to remove the need for a separate search phase on a proxy task.
- A parameter-free procedure is proposed where RandAugment always selects a transformation with uniform probability 1/K.
- Given N transformations for a training image, RandAugment may thus express K^N potential policies.
- With N=14, the number of transformations is: identity, autoContrast, equalize, rotate, solarize, color, posterize, contrast, brightness, sharpness, shear-x, shear-y, translate-x, translate-y.
1.2. M: Magnitude of Transformation

- The final set of parameters to consider is the magnitude of the each augmentation distortion.
- Briefly, each transformation resides on an integer scale from 0 to 10 where a value of 10 indicates the maximum scale for a given transformation.
2. Experimental Results
2.1. RandAugment Studies

- The Wide-ResNet (WRN) models are trained with the additional K=14 data augmentations and N=1, over a range of global distortion magnitudes M parameterized on a uniform linear scale ranging from [0, 30].
(a) & (b): Larger networks demand larger data distortions for regularization.
- Dashed lines in (b) & (d): AutoAugment magnitude which is constant.
(c) & (d): Optimal distortion magnitude is larger for models that are trained on larger datasets.
- Two free parameters N and M specifying RandAugment are identified through a minimal grid search.
2.2. CIFAR & SVHN

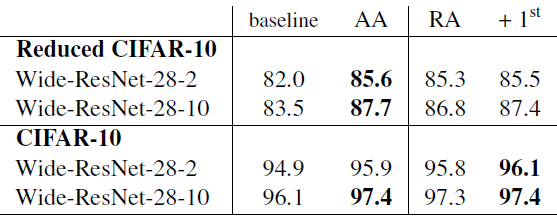
- CIFAR-10: The default augmentations for all methods include flips, pad-and-crop and Cutout. 1 setting for N and 5 settings for M (N=3 and tried 4, 5, 7, 9, and 11 for magnitude) are found using held-out val set.
RandAugment achieves either competitive (i.e. within 0.1%) or state-of- the-art on CIFAR-10 across four network architectures.
- CIFAR-100: Similar for CIFAR-100, 2 and 4 settings for N and M, are sampled respectively. (i.e. N={1, 2} and M={2, 6, 10, 14}). For WRN, Wide-ResNet-28–2 and Wide-ResNet-28–10, N=1, M=2 and N=2, M=14 achieves best results, respectively.
Again, RandAugment achieves competitive or superior results.
- SVHN: N=3 and tried 5, 7, 9, and 11 for magnitude.
WRN Wide-ResNet-28–10 with RandAugment matches the previous state-of-the-art accuracy on SVHN which used a more advanced model.
2.3. ImageNet

- RandAugment matches the performance of AutoAugment and Fast AutoAugment on the smallest model (ResNet-50).
On larger models RandAugment significantly outperforms other methods achieving increases of up to +1.3% above the baseline.
2.4. COCO
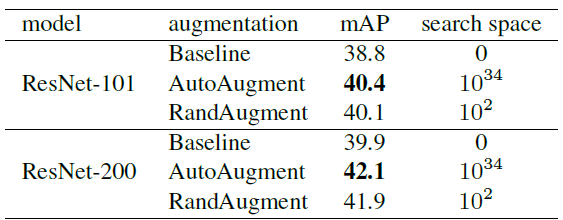
- AutoAugment expended ~15K GPU hours for search, where as RandAugment was tuned by on merely 6 values of the hyperparameters.
- N=1 and tried distortion magnitudes between 4 and 9.
RandAugment surpasses the baseline model and provides competitive accuracy with AutoAugment.
2.5. Investigating Transformations
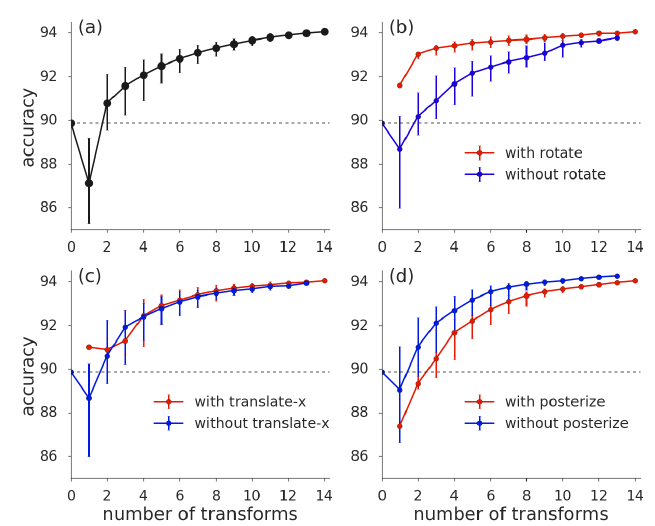
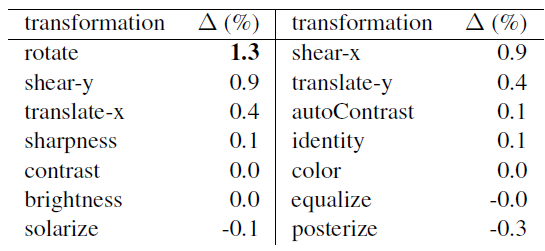
Surprisingly, rotate can significantly improve performance and lower variation even when included in small subsets of RandAugment transformations, while posterize seems to hurt all subsets of all sizes.
2.6. Learning the Probabilities for Selecting Image Transformations
- αij is denoted as the learned probability of selecting image transformation i for operation j. For K=14 image transformations and N=2 operations, αij constitutes 28 parameters.
- All weights are initialized such that each transformation is equal probability (i.e. RandAugment), and these parameters are updated based on how well a model classifies a held out set of validation images distorted by αij.
Learning the probabilities may improve the performance on small-scale tasks and explorations are reserved to larger-scale tasks for the future.
Reference
[2020 NeurIPS] [RandAugment]
RandAugment: Practical automated data augmentation with a reduced search space
Image Classification
1989–2018 … 2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet] [CB Loss] [AutoAugment, AA] [BagNet] [Stylized-ImageNet] [FixRes] [Ramachandran’s NeurIPS’19] [SE-WRN] [SGELU] [ImageNet-V2]
2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment]
2021: [Learned Resizer] [Vision Transformer, ViT]
