Review — MoCo v2: Improved Baselines with Momentum Contrastive Learning

Improved Baselines with Momentum Contrastive Learning
MoCo v2, by Facebook AI Research (FAIR)
2020 arXiv, Over 700 Citations (Sik-Ho Tsang @ Medium)
Self-Supervised Learning, Unsupervised Learning, Contrastive Learning, Representation Learning, Image Classification, Object Detection
- SimCLR systematically studies the major components for the success of self-supervised contrastive learning.
- MoCo v2 is achieved by enhancing MoCo v1 based on SimCLR’s studies: using an MLP projection head and more data augmentation.
- Indeed, this tech report only got 2 pages excluding the reference section.
Outline
- MoCo v2
- Experimental Results
1. MoCo v2
1.1. Background
- Contrastive loss function, called InfoNCE, in CPC, is used:

- where q is a query representation, k+ is a representation of the positive (similar) key sample, and {k-} are representations of the negative (dissimilar) key samples. τ is a temperature hyperparameter.
- End-to-End (Fig. a): In an end-to-end mechanism, the negative keys are from the same batch and updated end-to-end by back-propagation. SimCLR is based on this mechanism and requires a large batch to provide a large set of negatives.
- Memory Bank (Fig. b): The negative keys are maintained in a queue, and only the queries and positive keys are encoded in each training batch.
- In MoCo, a momentum encoder is adopted to improve the representation consistency between the current and earlier keys. MoCo decouples the batch size from the number of negatives.
1.2. Improved Designs
- SimCLR improves the end-to-end variant of instance discrimination in three aspects: (i) a substantially larger batch (4k or 8k) that can provide more negative samples; (ii) replacing the output fc projection head [16] with an MLP head; (iii) stronger data augmentation.
- In the MoCo framework, a large number of negative samples are readily available.
To enhance MoCo, the MLP head and data augmentation are used.
2. Experimental Results
2.1. Temperature

- Using the default τ=0.07, pre-training with the MLP head improves from 60.6% to 62.9%; switching to the optimal value for MLP (0.2), the accuracy increases to 66.2%.
2.2. MLP Head, Augmentation, Cosine Learning

- MLP: replace the fc head in MoCo with a 2-layer MLP head (hidden layer 2048-d, with ReLU).
- aug+: Extra blur augmentation is added onto the default one.
- cos: cosine learning rate schedule.
MLP+aug+cos improves MoCo v1. With longer training time of 800 epoches, results are even better.
2.3. SOTA Comparison
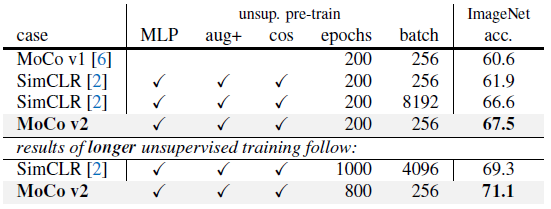
With MLP, aug+, cos, and longer training time (800 epochs), MoCo v2 achieves 71.1%, outperforming SimCLR’s 69.3% with 1000 epochs.
2.4. Computational Cost
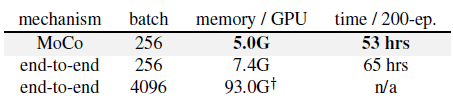
- For end-to-end mechanism, the 4k batch size is intractable even in a high-end 8-GPU machine. Also, under the same batch size of 256, the end-to-end variant is still more costly in memory and time, because it back-propagates to both q and k encoders, while MoCo back-propagates to the q encoder only.
Later on, MoCo extends as MoCo v3 by using Vision Transformer, ViT.
Reference
[2020 arXiv] [MoCo v2]
Improved Baselines with Momentum Contrastive Learning
Unsupervised/Self-Supervised Learning
1993 [de Sa NIPS’93] 2008–2010 [Stacked Denoising Autoencoders] 2014 [Exemplar-CNN] 2015 [Context Prediction] [Wang ICCV’15] 2016 [Context Encoders] [Colorization] [Jigsaw Puzzles] 2017 [L³-Net] [Split-Brain Auto] [Motion Masks] [Doersch ICCV’17] 2018 [RotNet/Image Rotations] [DeepCluster] [CPC/CPCv1] [Instance Discrimination] 2020 [CMC] [MoCo] [CPCv2] [PIRL] [SimCLR] [MoCo v2]
