Review — Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation
Google’s Multilingual Neural Machine Translation (GMNMT)

Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation
GMNMT, by Google
2017 TACL, Over 1400 Citations (Sik-Ho Tsang @ Medium)
Natural Language Model (NLP), Neural Machine Translation (NMT)
- There is no changes to the GNMT model architecture but instead an artificial token is introduced at the beginning of the input sentence to specify the required target language.
- Multilingual NMT systems are enabled using a single model.
Outline
- System Architecture
- Many to One, One to Many, Many to Many Experiments
- Large-Scale Experiments
- Zero-Shot Translation Experiments
1. System Architecture
- GNMT model is used.
- There is one simple modification to the input data, which is to introduce an artificial token at the beginning of the input sentence to indicate the target language. Originally:

- Now:

- <2es> is to indicate that Spanish is the target language. Note that the model doesn’t specify the source language — the model will learn this automatically.
- The model is trained with all multilingual data consisting of multiple language pairs at once.
- Three interesting cases for mapping languages: 1) many to one, 2) one to many, and 3) many to many, are evaluated.
- Two Datasets are evaluated: 1) WMT: WMT’14 dataset. 2) Prod: Google Production Dataset (Close Source).
2. Many to One, One to Many, Many to Many Experiments
2.1. Many to One

- Multiple source languages and single target language.
- No additional token in this case since there is only one target language.
- The baseline NMT models trained on a single language pair (using 1024 nodes, 8 LSTM layers and a shared wordpiece model vocabulary of 32k, a total of 255M parameters per model).
- Single: Single language dataset is used to train the model.
- Multi: Multi-language datasets are used to train the model.
- Number of parameters are kept the same which is quite unfair to GMNMT as number of parameters available per language pair is reduced by a factor of N (N: Number of languages).
- For all experiments the multilingual models outperform the baseline single systems. One possible reason is that the model has been shown more English data on the target side, and that the source languages belong to the same language families, so the model has learned useful generalizations.
2.2. One to Many
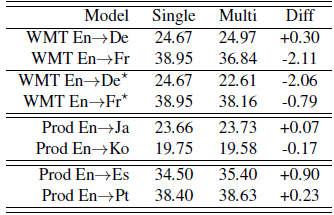
- Single source languages and multiple target language. An additional token to specify the target language.
- Multilingual models are comparable to, and in some cases outperform, the baselines, but not always.
2.3. Many to Many
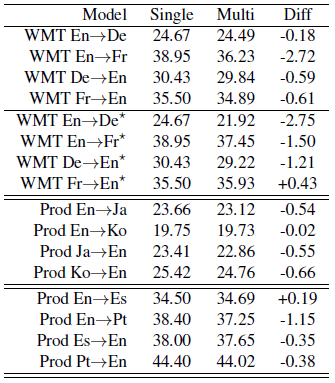
- Multiple source languages and multiple target languages within a single model.
- Although there are some significant losses in quality from training many languages jointly using a model with the same total number of parameters as the single language pair models, these models reduce the total complexity involved in training and productionization.
3. Large-Scale Experiments

- The table shows the result of combining 12 production language pairs having a total of 3B parameters (255M per single model) into a single multilingual model.
- A range of multilingual models were trained starting from the same size as a single language pair model with 255M parameters (1024 nodes) up to 650M parameters (1792 nodes).
- The multilingual models are on average worse than the single models (about 5.6% to 2.5% relative depending on size, however, some actually get better)
- But the largest multilingual model has still about five times less parameters than the combined single models.
- The multilingual model also requires only roughly 1/12-th of the training time (or computing resources) to converge.
In summary, multilingual NMT enables us to group languages with little loss in quality while having the benefits of better training efficiency, smaller number of models, and easier productionization.
4. Zero-Shot Translation Experiments

- Explicit bridging, meaning to translate to an intermediate language first and then translate to the desired target language.
- Disadvantages of this approach are: a) total translation time doubles, b) the potential loss of quality.
Model 2 (Implicit bridging) outperforms Model 1 (Explicit bridging) by close to 3 BLEU points although Model 2 was trained with four language pairs as opposed to with only two for Model 1.
- Finally, zero-shot Model 2 is incrementally trained with a small amount of true Pt→Es parallel data, the best quality and half the decoding time are obtained compared to explicit bridging in (b).
Overall this shows that the proposed approach of implicit bridging using zero-shot translation via multilingual models can serve as a good baseline.
(There are other results and analyses in the paper, please feel free to read the paper if interested.)
Reference
[2017 TACL] [GMNMT]
Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [T64] [Transformer-XL] [BERT]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE] [GMNMT]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
