Review — Model Distillation: Distilling the Knowledge in a Neural Network (Image Classification)
Smaller Models are Obtained Using Distillation. Faster Training for AlexNet on JFT Dataset.
In this story, Distilling the Knowledge in a Neural Network, by Google Inc., is briefly reviewed. This is a paper by Prof. Hinton.
Model ensembling is a simple way to improve the model performance. Yet, it can be computational expensive, especially if the individual models are large neural nets.
- In this paper, the knowledge in an ensemble of models is distilled into a single model.
This is a paper in 2014 NIPS with over 5000 citations. (Sik-Ho Tsang @ Medium)
Outline
- Higher Temperature for Model Distillation
- Experimental Results
1. Higher Temperature for Model Distillation
1.1. Higher Temperature for Soft Targets
- Neural networks typically produce class probabilities by using a “softmax” output layer that converts the logit, zi, computed for each class into a probability, qi, by comparing zi with the other logits:

- where T is a temperature that is normally set to 1.
Using a higher value for T produces a softer probability distribution over classes. This is useful since much of the information about the learned function resides in the ratios of very small probabilities in the soft targets.
- For example, one version of a 2 may be given a probability of 10^-6 of being a 3 and 10^−9 of being a 7 whereas for another version it may be the other way around. This is valuable information that defines a rich similarity structure over the data (i.e. it says which 2’s look like 3’s and which look like 7’s).
- Knowledge is transferred to the distilled model by training it on a transfer set and using a soft target distribution (T>1) for each case in the transfer set that is produced by using the cumbersome model with a high temperature in its softmax.
- The same high temperature is used when training the distilled model, but after it has been trained it uses a temperature T of 1.
1.2. The Calculation of Gradients
- Each case in the transfer set contributes a cross-entropy gradient, dC/dzi, with respect to each logit, zi of the distilled model.
- If the cumbersome model has logits vi which produce soft target probabilities pi and the transfer training is done at a temperature of T, The gradient is given by:

- If the temperature is high compared with the magnitude of the logits, it can be approximated as:

- Assuming that the logits z and v have been zero-meaned:

- The gradient can be further simplified as:
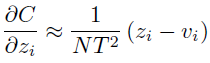
- It is later found that when the distilled model is much too small to capture all of the knowledge in the cumbersome model, intermediate temperatures work best.
2. Experimental Results
2.1. MNIST
- A single large neural net with two hidden layers of 1200 rectified linear hidden units on all 60,000 training cases. Dropout is used. This net achieved 67 test errors.
- A smaller net with two hidden layers of 800 rectified linear hidden units and no regularization achieved 146 errors.
- If the smaller net was regularized solely by adding the additional task of matching the soft targets produced by the large net at a temperature of 20, it achieved 74 test errors.
This shows that soft targets can transfer a great deal of knowledge to the distilled model.
- When the distilled net had 300 or more units in each of its two hidden layers, all temperatures above 8 gave fairly similar results. But when this was radically reduced to 30 units per layer, temperatures in the range 2.5 to 4 worked significantly better than higher or lower temperatures.
2.2. Speech Recognition
- An architecture with 8 hidden layers each containing 2560 rectified linear units and a final softmax layer with 14,000 labels (HMM targets ht) is used.
- The input is 26 frames of 40 Mel-scaled filterbank coefficients with a 10ms advance per frame and we predict the HMM state of 21st frame.
- The total number of parameters is about 85M.
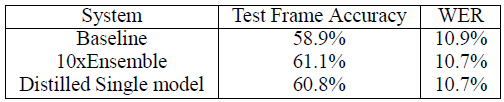
- To train the DNN acoustic model we use about 2000 hours of spoken English data, which yields about 700M training examples. This system achieves a frame accuracy of 58.9%, and a Word Error Rate (WER) of 10.9% on our development set.
- The ensemble gives a smaller improvement on the ultimate objective of WER (on a 23K-word test set) due to the mismatch in the objective function, but again, the improvement in WER achieved by the ensemble is transferred to the distilled model.
2.3. JFT

- JFT is an internal Google dataset that has 100 million labeled images with 15,000 labels.
- AlexNet needs to be trained using 6 months. Waiting for several years to train an ensemble of models was not an option.
- One way is to use “specialist” models, each of which is trained on data that is highly enriched in examples from a very confusable subset of the classes (like different types of mushroom).
- 61 specialist models are trained, each with 300 classes.
- At test time we can use the predictions from the generalist model to decide which specialists are relevant and only these specialists need to be run.
The idea is that the accuracy can be improved when we have more specialists covering a particular class. At the same time, the training time can be shorter since training independent specialist models is very easy to parallelize.
- Please feel free to read the paper for more details.
2.4. Soft Targets as Regularizers

- A lot of helpful information can be carried in soft targets that could not possibly be encoded with a single hard target.
- With only 3% of the data (about 20M examples), training the baseline model with hard targets leads to severe overfitting.
Soft targets allow a new model to generalize well from only 3% of the training set.
- The soft targets are obtained by training on the full training set.
Reference
[2014 NIPS] [Distillation]
Distilling the Knowledge in a Neural Network
Image Classification
1989–1998: [LeNet]
2012–2014: [AlexNet & CaffeNet] [Dropout] [Maxout] [NIN] [ZFNet] [SPPNet] [Distillation]
2015: [VGGNet] [Highway] [PReLU-Net] [STN] [DeepImage] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2]
2016: [SqueezeNet] [Inception-v3] [ResNet] [Pre-Activation ResNet] [RiR] [Stochastic Depth] [WRN] [Trimps-Soushen]
2017: [Inception-v4] [Xception] [MobileNetV1] [Shake-Shake] [Cutout] [FractalNet] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [IGCNet / IGCV1] [Deep Roots]
2018: [RoR] [DMRNet / DFN-MR] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2] [CondenseNet] [IGCV2] [IGCV3] [FishNet] [SqueezeNext] [ENAS] [PNASNet] [ShuffleNet V2] [BAM] [CBAM] [MorphNet] [NetAdapt] [mixup] [DropBlock] [Group Norm (GN)]
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet]
2020: [Random Erasing (RE)] [SAOL]

