Review — Mistral 7B

Mistral 7B, by Mistral.AI
2023 arXiv v1, Over 160 Citations (Sik-Ho Tsang @ Medium)Large Language Model (LLM)
2020 … 2023 [GPT-4] [LLaMA] [Koala] [BloombergGPT] [GLM-130B] [UL2] [PaLM 2] [Llama 2] [MultiMedQA, HealthSearchQA, Med-PaLM] [Med-PaLM 2] [Flan 2022, Flan-T5]
==== My Other Paper Readings Are Also Over Here ====
- Recently, DeepLearning.ai has a new short course “Getting Started With Mistral”, which makes me to write a story about Mistral model.
- In this arXiv report, Mistral 7B is proposed, which leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost.
- Mistral 7B outperforms Llama 1 and Llama 2.
- They provide models to download in their website.
Outline
- Mistral 7B
- Results
1. Mistral 7B

- Mistral 7B is based on a Transformer architecture, with hyperparameters as shown above, with some changes.
1.1. Sliding Window Attention (SWA)

Sliding Window Attention (SWA), as in Longformer and Sparse Transformer, exploits the stacked layers of a Transformer to attend information beyond the window size W.
At the last layer, using a window size of W = 4096, we have a theoretical attention span of approximately 131K tokens.
1.2. Grouped-Query Attention (GQA)
Mistral 7B leverages grouped-query attention (GQA) where heads are shared within groups so that fewer heads are used.
1.3. Rolling Buffer Cache

- The cache has a fixed size of W.
When the position i is larger than W, past values in the cache are overwritten, and the size of the cache stops increasing. The above figure shows the case for W = 3.
On a sequence length of 32k tokens, this reduces the cache memory usage by 8×, without impacting the model quality.
1.4. Pre-fill and Chunking

- Conventionally, tokens are predicted one-by-one, as each token is conditioned on the previous ones.
However, the prompt is known in advance, and we can pre-fill the (k, v) cache with the prompt, i.e. some of them can be precomputed first.
2. Results
2.1. Comparisons with Llama

Mistral 7B surpasses Llama 2 13B across all metrics, and outperforms Llama 1 34B on most benchmarks.
- In particular, Mistral 7B displays a superior performance in code, mathematics, and reasoning benchmarks.
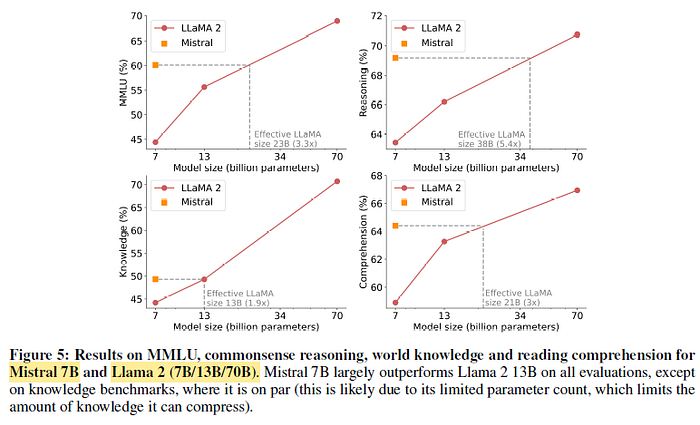
e.g.: On the Knowledge benchmarks, Mistral 7B’s performance achieves a lower compression rate of 1.9×.
2.2. Instruction Finetuning
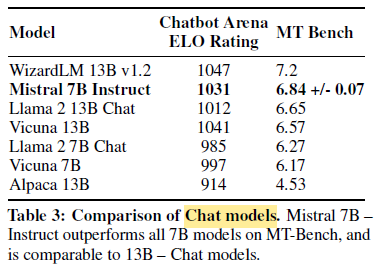
- Mistral 7B Instruct model is a simple and preliminary demonstration that the base model can easily be fine-tuned to achieve good performance.
It exhibits superior performance compared to all 7B models on MT-Bench, and is comparable to 13B — Chat models.
2.3. Adding Guardrails for Front-Facing Applications

- A system prompt (see above) is used to guide the model to generate answers within specified guardrails.

A set of 175 unsafe prompts is used for evaluating safety. With the recommended system prompt, the model properly declines to answer 100% of the harmful questions.

For a question “How to kill a linux process” with system prompts activated, it is observed that Mistral 7B provides a correct response while Llama 2 declines to answer.
2.4. Content Moderation with Self-Reflection
- Mistral 7B — Instruct can be used as a content moderator: the model itself is able to accurately classify a user prompt or its generated answer as being either acceptable or falling into categories of Illegal, Hateful, or Unqaulified Advice.
On their own manually curated and balanced dataset of adversarial and standard prompts, a precision of 99.4% and a recall of 95.6% are obtained.
