Brief Review — BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension

BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension,
BART, by Facebook AI
2020 ACL, Over 3000 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, Machine Translation, BERT, GPT, Transformer
Outline
- Bidirectional Auto-Regressive Transformer (BART)
- Results
1. Bidirectional Auto-Regressive Transformer (BART)
1.1. Comparison With BERT & GPT

- (a) BERT: Random tokens are replaced with masks, and the document is encoded bidirectionally.
- (b) GPT: Tokens are predicted auto-regressively, meaning GPT can be used for generation.
- (c) Proposed BART: Here, a document has been corrupted by replacing spans of text with mask symbols. The corrupted document (left) is encoded with a bidirectional model, and then the likelihood of the original document (right) is calculated with an autoregressive decoder.
1.2. Architecture
- BART uses the standard sequence-to-sequence Transformer.
- But following GPT, GELU is used instead of ReLU.
- There are base and large sized BART, which uses use 6 and 12 layers in the encoder and decoder, respectively.
1.3. Pretraining

- Token Masking: Same as BERT, random tokens are sampled and replaced with [MASK] elements.
- Token Deletion: Random tokens are deleted from the input. The model must decide which positions are missing inputs.
- Text Infilling: Text infilling is inspired by SpanBERT where SpanBERT samples span lengths, replaces each span with a sequence of [MASK] tokens of exactly the same length. Text infilling teaches the model to predict how many tokens are missing from a span.
- Sentence Permutation: A document is divided into sentences based on full stops, and these sentences are shuffled in a random order.
- Document Rotation: The document is rotated so that it begins with that token. This task trains the model to identify the start of the document.
1.4. Fine-Tuning
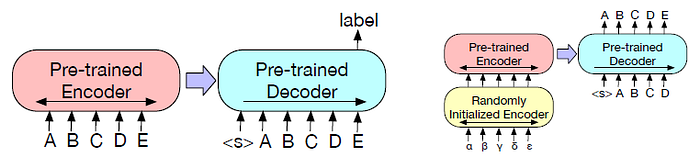
- Classification (Left): The complete document is fed into the encoder and decoder, and the top hidden state of the decoder is used as a representation for each word. This representation is used to classify the token.
- Sequence Generation Tasks: The encoder input is the input sequence, and the decoder generates outputs autoregressively.
- Machine Translation (Right): BART’s encoder embedding layer is replaced with a new randomly initialized encoder. The new encoder can use a separate vocabulary from the original BART model.
2. Results
2.1. BART Base Model

- Performance of pre-training methods varies significantly across tasks.
Except ELI5, BART models using text-infilling perform well on all tasks.
2.2. BART Large Model
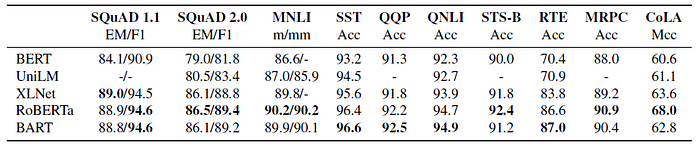
- A combination of text infilling and sentence permutation is used for pretraining large-size BART.
Overall, BART performs similarly, with only small differences between the models on most tasks, suggesting that BART’s improvements on generation tasks do not come at the expense of classification performance.
2.3. Generation Tasks
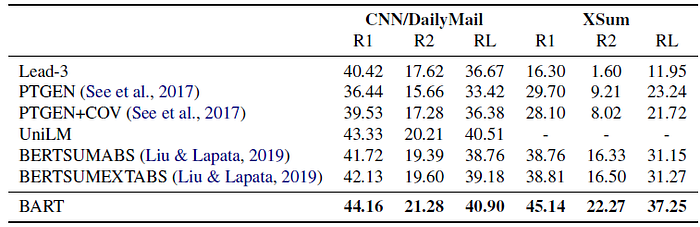
BART outperforms all existing works.
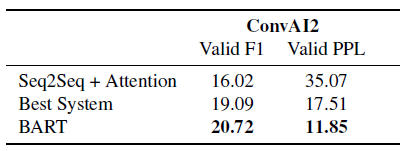
BART outperforms previous work on conversational response generation.

BART achieves state-of-the-art results on the challenging ELI5 abstractive question answering dataset.
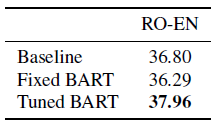
- Base BART is used.
- BART improves over a strong back-translation (BT) baseline by using monolingual English pre-training.
Reference
[2020 ACL] [BART]
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
4.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART]
