Review — GPT: Improving Language Understanding by Generative Pre-Training
Pretraining Using T-DMCA, a Kind of Transformer, for Other Downstream Tasks

Improving Language Understanding by Generative Pre-Training,
GPT, by OpenAI
2018 OpenAI Tech Report, Over 2700 citations (Sik-Ho Tsang @ Medium)
Language Model
- Large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task.
- Task-aware input transformations are used during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture.
It is a kind of self-supervised training that the pretext task is the pre-training of a language model and downstream tasks are the tasks in GLUE benchmark.
Outline
- GPT Framework
- Task-Specific Input Transformations
- Experimental Results
1. GPT Framework
- The training procedure consists of two stages. The first stage is learning a high-capacity language model (Unsupervised Pre-Training) on a large corpus of text. This is followed by a (Supervised) fine-tuning stage, where we adapt the model to a discriminative task with labeled data.
1.1. Unsupervised Pre-Training
- Given an unsupervised corpus of tokens U = {u1, …, un}, we use a standard language modeling objective to maximize the following likelihood:

- T-DMCA is used which is a memory-reduced Transformer, with only the use of decoder.
- This model applies a multi-headed self-attention operation over the input context tokens followed by position-wise feedforward layers to produce an output distribution over target tokens:

- where U=(u_-k, …, u_-1) is the context vector of tokens, n is the number of layers, We is the token embedding matrix, and Wp is the position embedding matrix.
1.2. Supervised Fine-Tuning
- Assume there is a labeled dataset C, where each instance consists of a sequence of input tokens, x1, …, xm, along with a label y. The inputs are passed through the pre-trained model to obtain the final Transformer block’s activation hml, which is then fed into an added linear output layer with parameters Wy to predict y:

- The following objective to is to be maximized:

- It is found that including language modeling as an auxiliary objective to the fine-tuning helped learning by (a) improving generalization of the supervised model, and (b) accelerating convergence.
- Overall, the only extra parameters we require during fine-tuning are Wy, and embeddings for delimiter tokens.
2. Task-Specific Input Transformations

- For some tasks, like text classification, we can directly fine-tune the model.
- Certain other tasks, like question answering or textual entailment, have structured inputs such as ordered sentence pairs, or triplets of document, question, and answers.
- A traversal-style approach [52] is used, where the structured inputs are converted into an ordered sequence that the pre-trained model can process. These input transformations allow us to avoid making extensive changes to the architecture across tasks.
- For entailment tasks, the premise p and hypothesis h token sequences are concatenated, with a delimiter token ($) in between, as shown above.
- For similarity tasks, the input sequence is modified to contain both possible sentence orderings (with a delimiter in between) and process each independently to produce two sequence representations hml which are added element-wise before being fed into the linear output layer.
- For question answering and commonsense reasoning, given a context document z, a question q, and a set of possible answers {ak}. The document context and question are concatenated with each possible answer. A delimiter token is added in between to get [z, q, $, ak].
- Each of these sequences are processed independently with the model and then normalized via a softmax layer to produce an output distribution over possible answers.
3. Experimental Results
3.1. SOTA Comparison
- BooksCorpus dataset is used for pre-training. It contains over 7,000 unique unpublished books from a variety of genres including Adventure, Fantasy, and Romance.
- An alternative dataset, the 1B Word Benchmark. The proposed language model achieves a very low token level perplexity of 18.4 on this corpus.
- The model is trained for 100 epochs on minibatches of 64 randomly sampled, contiguous sequences of 512 tokens.
- GLUE benchmark is used for evaluation.
- The finetunes are quick and 3 epochs of training was sufficient for most cases.
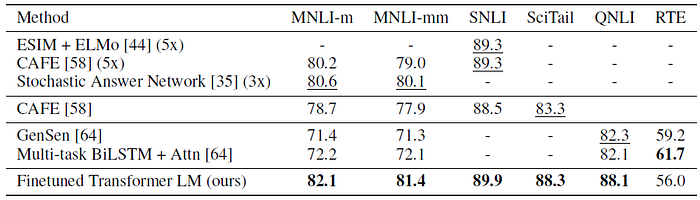
The proposed method significantly outperforms the baselines on four of the five datasets, achieving absolute improvements of up to 1.5% on MNLI, 5% on SciTail, 5.8% on QNLI and 0.6% on SNLI over the previous best results.
- On RTE, one of the smaller datasets evaluated on (2490 examples), an accuracy of 56% is achieved, which is below the 61.7% reported by a multi-task biLSTM model.
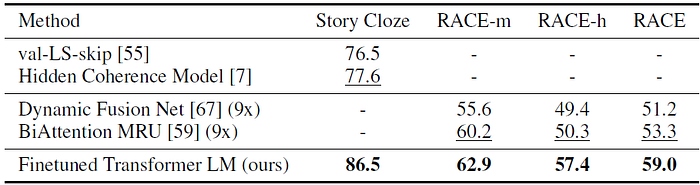
- RACE dataset [30], consists of English passages with associated questions from middle and high school exams.
- Story Cloze Test [40], involves selecting the correct ending to multi-sentence stories from two options.
The proposed model again outperforms the previous best results by significant margins — up to 8.9% on Story Cloze, and 5.7% overall on RACE. This demonstrates the ability of our model to handle long-range contexts effectively.
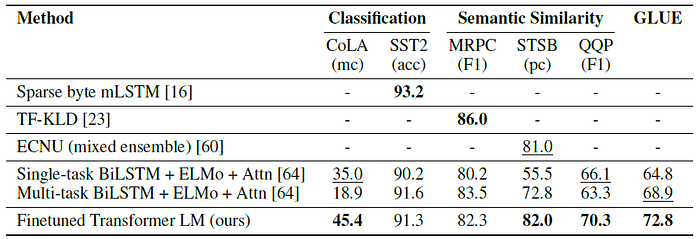
- Semantic similarity (or paraphrase detection) tasks involve predicting whether two sentences are semantically equivalent or not.
- The performance delta on QQP is significant, with a 4.2% absolute improvement over Single-task BiLSTM + ELMo + Attn.
- For classification tasks, the proposed model also achieves 91.3% accuracy on SST-2, which is competitive with the state-of-the-art results.
The proposed model also achieve an overall score of 72.8 on the GLUE benchmark, which is significantly better than the previous best of 68.9.
3.2. Analysis
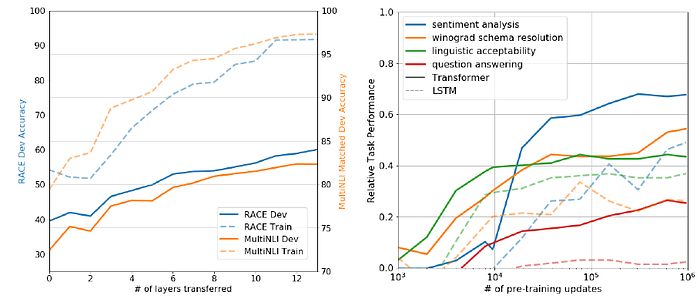
- Left: Each layer in the pre-trained model contains useful functionality for solving target tasks.
- Right: The performance of these heuristics is stable and steadily increases over training suggesting that generative pretraining supports the learning of a wide variety of task relevant functionality.
3.3. Ablation Study

- The auxiliary objective helps on the NLI tasks and QQP. Overall, the trend suggests that larger datasets benefit from the auxiliary objective but smaller datasets do not.
- A 5.6 average score drop is observed when using the LSTM instead of the Transformer. The LSTM only outperforms the Transformer on one dataset — MRPC.
- Finally, the lack of pre-training hurts performance across all the tasks, resulting in a 14.8% decrease compared to the full model.
Reference
[2018 OpenAI] [GPT]
Improving Language Understanding by Generative Pre-Training
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
