Brief Review — ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
ERNIE 3.0 Titan with 260B Model Size
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
ERNIE 3.0 Titan, by Baidu Inc., and Peng Cheng Laboratory
2021 arXiv v1, Over 40 Citations (Sik-Ho Tsang @ Medium)Large Langauge Model (LLM)
2020 … 2023 [GPT-4] [LLaMA] [Koala] [BloombergGPT] [GLM-130B] [UL2] [PaLM 2] [Llama 2] [Med-PaLM]
==== My Other Paper Readings Are Also Over Here ====
- After ERNIE 1.0, ERNIE 2.0, and ERNIE 3.0, ERNIE 3.0 Titan with up to 260 billion parameters is also proposed.
- A self-supervised adversarial loss and a controllable language modeling loss are designed to make ERNIE 3.0 Titan generate credible and controllable texts.
- Online Distillation framework is also proposed.

- Later, ERNIE 3.5 is proposed: http://research.baidu.com/Blog/index-view?id=185
- ERNIE 4.0 is also published 2 days ago: https://www.youtube.com/watch?v=EYXMCMl0bs4
Outline
- ERNIE 3.0 Titan: Pretraining Tasks
- ERNIE 3.0 Titan: Model & Distillation
- Results
1. ERNIE 3.0 Titan: Pretraining Tasks

- Beside the pretraining tasks using in ERNIE 3.0, there is new task called Credible and Controllable Generations.
- A self-supervised adversarial loss and a controllable language modeling loss for generating credible and controllable texts, respectively.
1.1. Self-Supervised Adversarial Loss
The self-supervised adversarial loss allows the model to distinguish whether a text is generated or the original one. As a result, it is easy for ERNIE 3.0 Titan to discard the low credibility generated texts with repeating words, unfluent and conflicting sentences.
- This is formulated as a binary classification problem experimented on the ERNIE 3.0 adversarial dataset Da = {Doriginal, Dgenerated} which is a subset of original ERNIE 3.0 Corpus Doriginal with its adversarial samples Dgenerated generated by ERNIE 3.0.

- The output hidden state of the special token [CLS] is taken as input for binary classification. The cross-entropy loss is minimized.
- The positive examples consist of 2M natural paragraphs sampled from ERNIE 3.0 Corpus.
1.2. Controllable Language Modeling Loss
- The controllable language modeling loss is a modified language modeling loss by conditioning on extra prompts for controlling the generated texts as follows:

- where ERNIE 3.0 Titan is trained to minimize the negative log-likelihood loss on ERNIE 3.0 controllable dataset Dc.
- t means the tth token of x. xn is associated with prompts^n specifying the genre, topic, keywords, sentiment and length.
- Genre: is assigned to samples based on the source the data collected from.
- Topic: is labeled using a topic model which can classify a document into 26 different topics such as international, sports, society, …
- Keywords: are extracted using a keyword extraction model that reflect the key information of the article, such as subject, entity, etc.
- Sentiment: is derived using a sentiment classification model. A positive, negative, or neutral label is assigned to each sample.
- Length: is counted on the tokenized text. The length attribute can prompt the model to generate texts with the desired length to avoid harshly truncating.
2. ERNIE 3.0 Titan: Model & Distillation
2.1. Model

- Following the pre-training setting of ERNIE 3.0, ERNIE 3.0 Titan includes the universal representation module and the task-specific representation modules, which both use the Transformer-XL structure.
- A structure with 12 layers, 768 hidden units, and 12 heads is used for the task-specific representation modules. A structure with 48 layers, 12288 hidden units, and 192 heads is used for the universal representation modules.
We can see that the hidden units are much larger and number of heads is much more than ERNIE 3.0.
- This model requires 2.1TB for parameter and optimizer states storage and 3.14E11 TeraFLOPS for training 300 billion tokens.
- It will take 28 days to train with 2048 GPU V100 cards even with a 50% percentage of theoretical peak FLOPS.
- PaddlePaddle developed an end-to-end adaptive distributed training technology, including fine-grained parallelism, heterogeneous hardware-aware training, and fault tolerance mechanism. (For this part, please read the paper directly for more details.)
2.2. Distillation
- (There is hardware concern for Distillation, please read the paper directly for more details.)
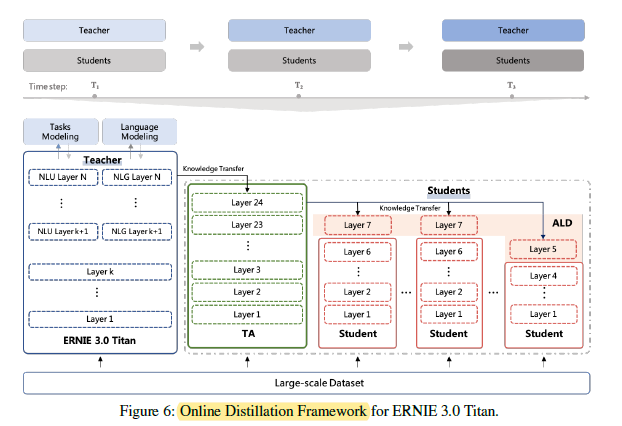
- Kullback–Leibler (KL) divergence of Al,a (attention values at multi-head self-attention (MHA) layer) between teacher and students as the Distillation objective.
- However, matching the attention in the last layer of the students will leave the FFN in the last layer untrained as the gradient only flows backward. To this end, an extra layer is stacked on the students during Distillation to ensure that the gradient can flow through the entire network and that all the parameters are trained during Distillation.
- This extra layer will be discarded when the students are fine-tuned on downstream tasks.
3. Results
- All experimental results of ERNIE 3.0 Titan are based on the insufficiently pre-trained model so far. ERNIE 3.0 Titan is still in training.
3.1. Fine-Tuning
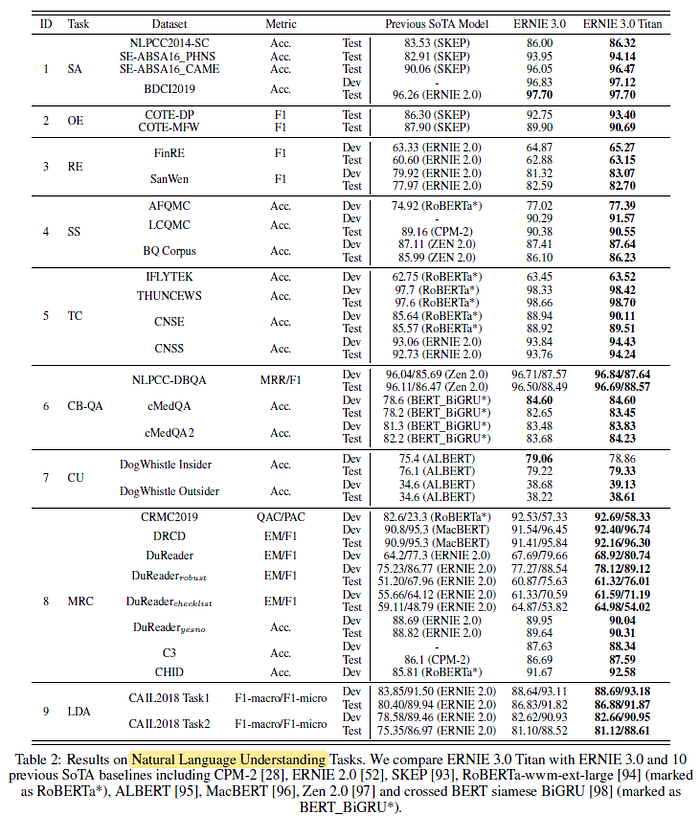
ERNIE 3.0 Titan performs the best for nearly all tasks.
3.2. Few-Shot
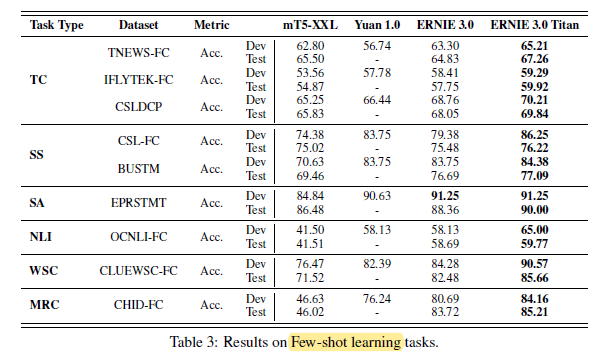
ERNIE 3.0 Titan consistently outperforms baseline models, including ERNIE 3.0.
3.3. Zero-Shot
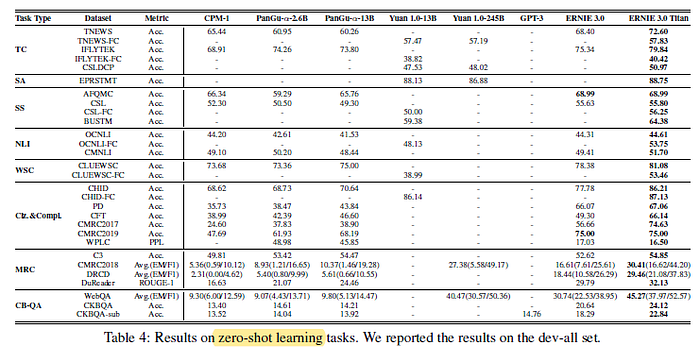
ERNIE 3.0 Titan achieves strong performance compared to recently proposed large-scale Chinese language models such as CPM-1 (2.6B), PanGu-α, Yuan 1.0 on all downstream tasks.
3.4. Distilled ERNIE 3.0 Titan
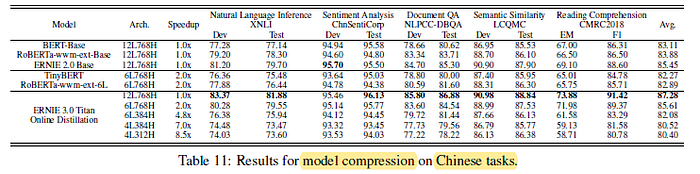
- The 12L768H student model achieves SOTA results on all tasks.
- The 6L768H version of distilled ERNIE 3.0 Titan performs the best and even outperforms the 12-layer BERT-Base on XNLI, LCQMC, and NLPCC-DBQA.
