Brief Review — Fastformer: Additive Attention Can Be All You Need
Additive Attention Mechanism, With Linear Complexity, Outperforms or On Par With Longformer, BigBird, Linformer
Fastformer: Additive Attention Can Be All You Need
Fastformer, by Tsinghua University, and Microsoft Research Asia
2021 arXiv v6, Over 140 Citations (Sik-Ho Tsang @ Medium)Language Model (LM)
2007 … 2022 [GLM] [Switch Transformers] [WideNet] [MoEBERT] [X-MoE] [sMLP] [LinkBERT, BioLinkBERT] [AlphaCode] [Block-wise Dynamic Quantization] 2023 [ERNIE-Code] [Grouped-Query Attention (GQA)]
==== My Other Paper Readings Are Also Over Here ====
- Fastformer is proposed, wherein an additive attention mechanism is designed to model global contexts, and then further transform each token representation based on its interaction with global context representations.
- In this way, Fastformer can achieve effective context modeling with linear complexity.
Outline
- Fastformer
- Results
1. Fastformer

- First, three independent linear transformation layer to transform the input into the attention query, key and value matrices Q, K, V.
- It then uses additive attention mechanism to summarize the query sequence into a global query vector with the attention weights:


- Next, it models the interaction between the global query vector and attention keys with element-wise product.
- Similarly, it then summarizes keys into a global key vector via additive attention with attention weights:


- And then it models the interactions between global key and attention values via element-wise product.
- A linear transformation is then used to learn global context-aware attention values, and finally added with the attention query to form the final output.
In this way, the computational complexity can be reduced to linearity.
- The above fastformer module is then formed a fastformer similar to Transformer
2. Results

- Efficient Transformer variants, such as Longformer, BigBird, Linformer, usually outperform the standard Transformer model.
- The quadratic computational cost of vanilla Transformer limits the maximum sequence length can be handled.
Fastformer can achieve competitive or better performance than other efficient Transformer variants in both long and short text modeling.
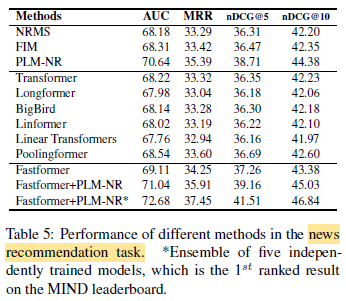
Fastformer achieves the best performance, and it also outperforms its basic NRMS model.
- In addition, Fastformer can further improve the performance of PLM-NR, and the ensemble model achieves the best results on the MIND leaderboard.
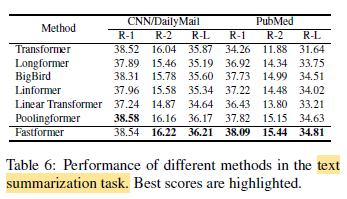
- On the CNN/DM dataset, many efficient Transformer variants (except Poolingformer and Fastformer) are inferior to the vanilla Transformer.
Fastformer can achieve the best performance in most metrics, which shows the advantage of Fastformer in natural language generation.

- The complexity of Fastformer only depends on the sequence length and the hidden dimension, and it has the least complexity among compared methods.
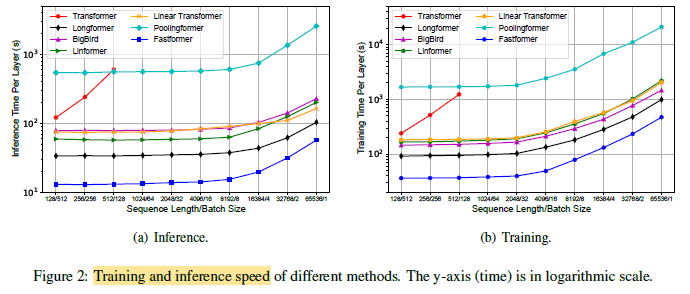
Fastformer is much more efficient than other linear complexity Transformer variants in terms of both training and inference time.
