Brief Review — Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism

Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism,
Megatron-LM, by NVIDIA,
2020 arXiv v4, Over 500 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, BERT, GPT-2
Outline
- Model Parallelism Transformer
- Results
1. Model Parallelism Transformer
- (Assume Transformer is already known here.)
Each Transformer layer has a self-attention layer and a MLP. Model parallel implementation is to be considered for the Transformer.
1.1. Model Parallelism in Transformer MLP
- The first part of the block is a General Matrix-Matrix Multiplication (GEMM) followed by a GELU nonlinearity:

- One option to parallelize the GEMM is to split the weight matrix A along its rows and input X along its columns as:

- This approach will require a synchronization point before the GELU.
- Another option is to split A along its columns A=[A1, A2]. This partitioning allows the GELU nonlinearity to be independently applied to the output of each partitioned GEMM:

- This is advantageous as it removes a synchronization point.

Hence, the first GEMM is partitioned in this column parallel fashion and the second GEMM is split along its rows so it takes the output of the GELU layer directly without requiring any communication, as above.
1.1. Model Parallelism in Transformer Self-Attention Block

- GEMMs associated with key (K), query (Q), and value (V) in a column parallel fashion such that the matrix multiply corresponding to each attention head is done locally on one GPU.
- The subsequent GEMM from the output linear layer (after self attention) is parallelized along its rows and takes the output of the parallel attention layer directly, without requiring communication between the GPUs.
1.3. Putting it All Together
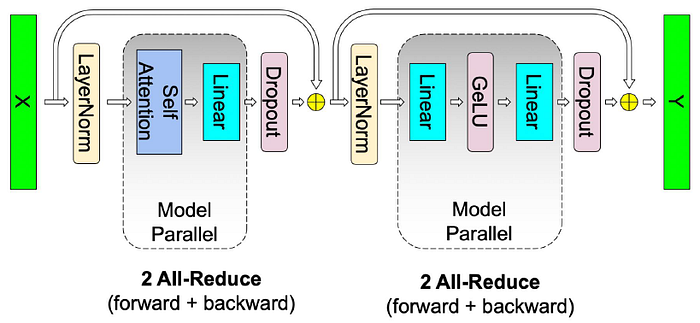
- This approach for both the MLP and self attention layer fuses groups of two GEMMs, eliminates a synchronization point in between, and results in better scaling.
- This enables us to perform all GEMMs in a simple Transformer layer using only two all-reduces in the forward path and two in the backward path.
2. Results
2.1. Language Modeling Results Using GPT-2

- Training data: 174 GB WebText/CC Stories/Wikipedia/RealNews.
- 3 model sizes: 355 million, 2.5 billion, and 8.3 billion.
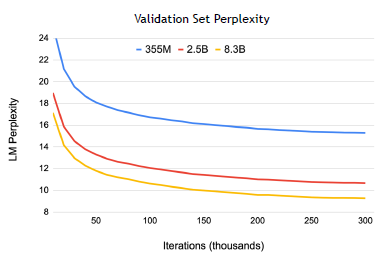
Larger language models converge noticeably faster and converge to lower validation perplexities than their smaller counterparts.
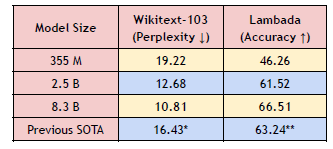
Increasing model size also leads to lower perplexity on WikiText103 and higher cloze accuracy on LAMBADA.
2.2. Bi-directional Transformer Results Using BERT
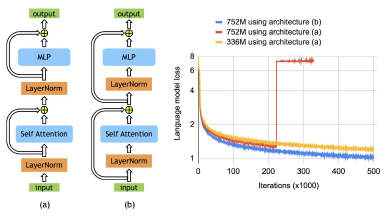
- According to ALBERT, the BERT’s Layer Norm is rearranged, within the skip connection, which can help for stable training.

- 3 Model sizes are established: 334M, 1.3B, and 3.9B.
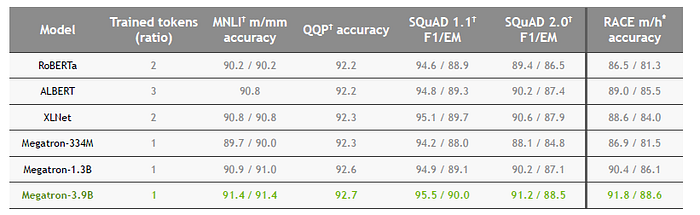
By scaling up, Megatron-3.9B obtains the best results.
- NVIDIA presents Megatron-LM in their GTC 2020 (link provided below). But later, GPT-3 is much much larger, with model size of 175B.
References
[2020 arXiv v4] [Megatron-LM]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
[GTC 2020] [Megatron-LM]
https://developer.nvidia.com/gtc/2020/video/s21496
4.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART] [Longformer] [ELECTRA] [Megatron-LM]
